






用python selenium提取网页中的所有标签中的超用python selenium提取网页中的所有链接,url = driver.find_element_by提取所有链接应该用循环: urls = driver.find_elements_by_xpath("//a")for url in urls: print(url.get_attribute("href"))如果get_attribute方法报错应该是没有找到a标签对象,如果确定是有的话,可能是页面加载比较慢还没加载出来。
python,CSS布局HTML小编今天和大家分享一个简单的selenium+re的网页源码爬取
网页爬取不一定要用Selenium,Selenium是为了注入浏览器获取点击行为的调试工具,如果网页无需人工交互就可以抓取,不建议你使用selenium。要使用它,你需要安装一个工具软件,使用Chrome浏览器需要下载chromedriver.exe到system32下。
python用selenium可以从浏览器窗口人工选择链接点我现在想爬取一些已知题目(但是不准确)的论文,在百度学术中有很多相可以 但是用scrapy可以更好的实现 毕竟API要比UI的操作稳定很多,而且Scrapy在爬虫方面要比selenium专业很多
如何用selenium爬取动态加载网页
动态网页抓取都是典型的办法 直接查看动态网页的加载规则。如果是ajax,则将ajax请CSS布局HTML小编今天和大家分享找出来给python。 如果是js去处后生成的URL。就要阅读JS,搞清楚规则。再让python生成URL。
c#selenium的webdriver能爬取静态页面吗
python selenium.webdriver + PhantomJS爬取网页问题
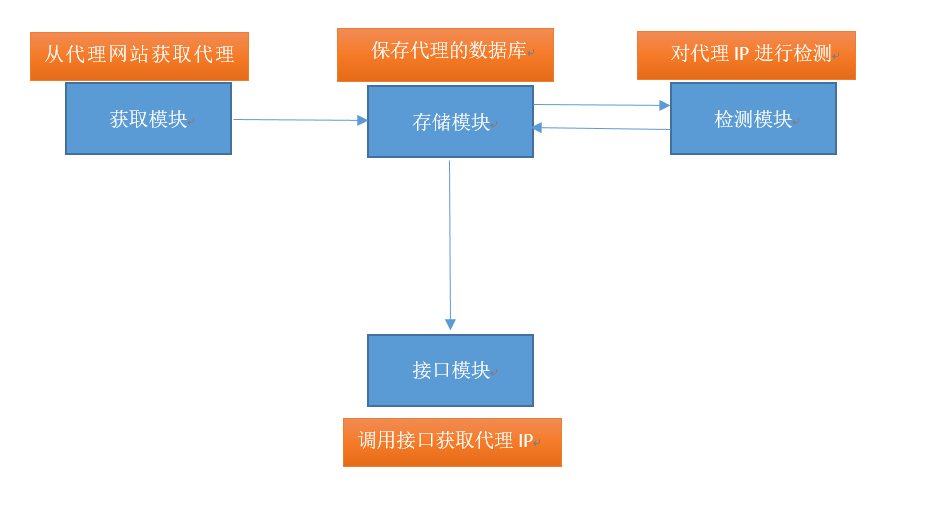
selenium+PhantomJS可以模拟网站交互 但是频繁爬取网址,如何更改IP,如selenium+PhantomJS可以模拟网站交互但是频繁爬取网址,如何更改IP,如何修改请CSS布局HTML小编今天和大家分享头呢?CSS布局HTML小编今天和大家分享大神解答... selenium+PhantomJS可以模拟网站交互但是频繁爬取网址,如何更改IP,
scrapy selenium 加载完成后的网页怎么爬取

















 3038
3038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









