






 本文介绍如何通过Forge配置优化Minecraft,包括调整多核心支持和区块加载设置,重点推荐asie MOD内存优化。通过修改config降低CPU占用和内存使用,解决内存溢出问题。
本文介绍如何通过Forge配置优化Minecraft,包括调整多核心支持和区块加载设置,重点推荐asie MOD内存优化。通过修改config降低CPU占用和内存使用,解决内存溢出问题。
首先MOJANG的高超优化本帖不在叙述,很多Minecraft的代码他们或许自己都看不懂。
这既是MC优化差的原因,也是拖了快5年的官方API迟迟不出的原因(貌似已经取消)。
同时MC在启动时还会加载很多然并卵的东西,这些东西或许是重复的,或许根本对游戏本身没有用。
不知道MOJANG是出于什么心态,但是对玩家来说,带来了更多不便与卡顿还有特性。
本文将会告诉大家很多知名的优化类Mod以及通过改config下的Forge选项来做到尽可能的优化硬件的占用率。
首先,让我们打开Forge的配置文件
请注意这一行
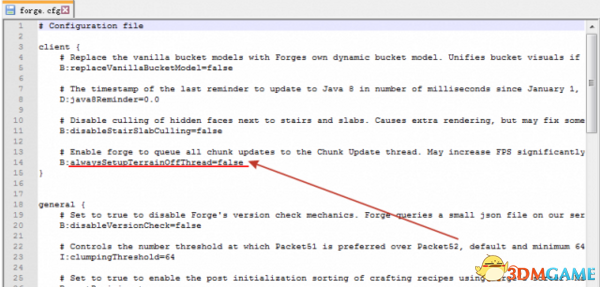
这就是Minecraft对于很多新兴的CPU占用率低的关键。
很多人认为MC不支持多核心,这个观念半对半错。
错在Forge支持多核心,实测将false改为true后MC性能有很大的提升,我在网吧测试(CPU:4790没k)改签占用只有20-40,改后50-100 FPS提升了超过100。
越是新、好的CPU,理论提示FPS越高。
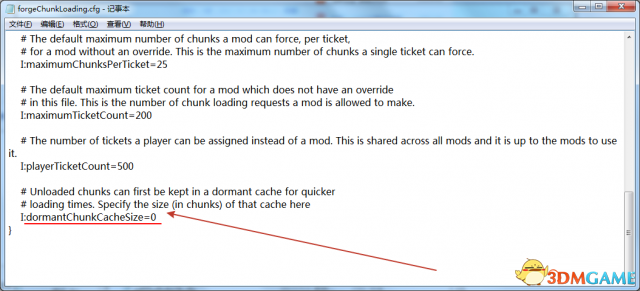
在Forge的区块加载里面,还有个这设置。
个人暂时不清楚这到底是要表示什么。
不过如果你的电脑有明显的加载区块卡顿或者每隔一定时间固定卡顿几秒。
可以把0调为其他的正数看看效果。
一个有点玄的东西。
asie这位dalao开发的MOD,实测对内存的优化好到逆天,在0.7.0 版本中个人装45个大型Mod内存任然只有500MB-600MB左右,很少超过了700。
其实就是禁止了二次纹理加载,就是MC默认启动其实会加载两次材质,这个东西禁用了一次并且在进入游戏前会cleanup一次垃圾内存。
这东西的优化实测比它的宣传图还好。
附上MOD下载地址
https://dl.3dmgame.com/201707/110270.html
这就是小编找到的我的世界内存溢出解决方法教程了,大家认为内存溢出怎么办这个问题解决的如何?

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









