







 本文介绍了如何利用R语言的rvest包基础功能爬取网页数据,通过实例演示了从内蒙古财经大学官网获取党政部门、学院及教辅部门名称和域名的过程,讲解了HTML节点的选择、文本和属性的提取等关键步骤。
本文介绍了如何利用R语言的rvest包基础功能爬取网页数据,通过实例演示了从内蒙古财经大学官网获取党政部门、学院及教辅部门名称和域名的过程,讲解了HTML节点的选择、文本和属性的提取等关键步骤。
基于R语言rvest包的网页数据爬取(基础)
Project Num:201901
写在前面:
在使用技术手段爬取需要登录账号才可以获取到的数据时,请先认真阅读该网站的用户协议,以免产生不必要的法律问题。
文末附带html节点速查表以及rvest包函数功能速查表
关于html5页面源码的常识
html5是指包括HTML、CSS、JavaScript在内的一套技术组合。
(以下工作建议在firefox浏览器中进行)
前情提要:
HTML是超文本标记语言,重点去体会标记语言的特点,我个人感觉类似markdown(例如Rmarkdown),每一个节点开头都是以开始,以结尾,举例:
文档标题
可见文本
看起来层次感很强,节点名永远是以一对或多对的形式出现。(这段html5的源码可以粘在一份*.txt文件里,然后把扩展名改为html,然后用web浏览器打开)
检查元素
检查网页元素是爬取网页内容的基础,你可以在浏览器中查看你所要爬取的数据所在的页面,将光标移动到要爬取的内容上,然后右键选择查看元素
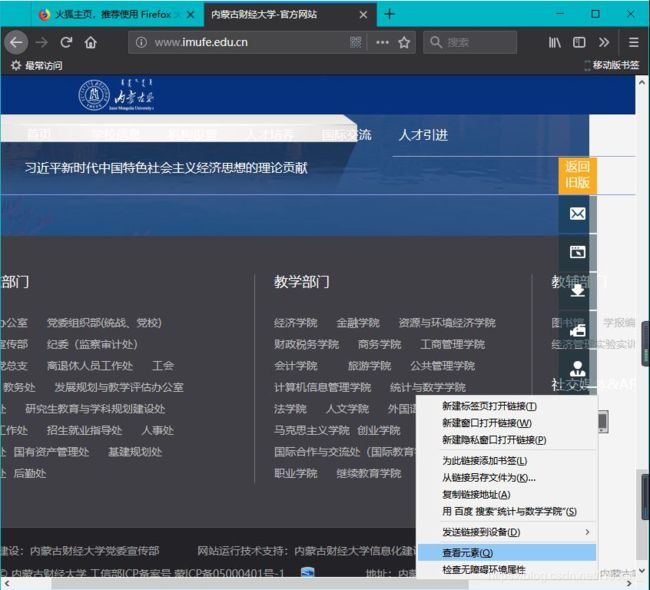
然后打开查看器,我们可以看到"统计与数学学院"的域名与文本
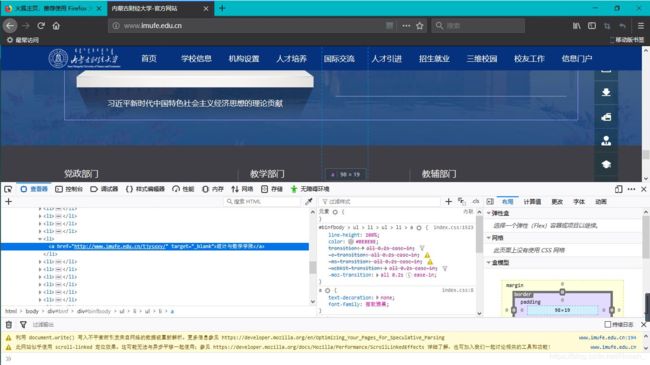
可以看到,在"内蒙古财经大学"的官网首页中,党政部门、各学院以及教辅部门的内容被放在若干个节点中,而这些节点则在id="binf"的节点里,所以到这里我们可以将我们所需要的内容范围缩小到里。

明确了要爬取的节点之后,我们就可以开始使用R语言中的rvest包中的函数来尝试
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









