




简介:在数字化时代,内容管理系统(CMS)成为企业和个人管理与发布数字内容的核心工具。本项目基于SpringBoot框架构建,充分利用其“约定优于配置”、自动装配和嵌入式服务器等特性,实现一个高可用、易扩展的CMS系统。系统涵盖用户权限控制、内容增删改查、分类标签管理、版本控制、多语言支持及搜索功能,并集成Thymeleaf模板引擎、Redis缓存、Elasticsearch搜索和RESTful API等现代技术。通过本项目实战,开发者可掌握SpringBoot在真实场景中的应用,理解前后端分离架构设计,提升企业级应用开发能力。
1. SpringBoot框架核心原理与优势解析
核心设计思想与自动配置机制
SpringBoot 以“约定优于配置”为核心理念,通过 @SpringBootApplication 注解整合了 @Configuration 、 @ComponentScan 和 @EnableAutoConfiguration ,实现一键式启动。其自动配置基于条件化装配( @ConditionalOnClass 、 @ConditionalOnMissingBean ),根据类路径依赖动态加载配置类,如存在 DispatcherServlet 则自动配置 Spring MVC 环境。
@SpringBootApplication
public class CmsApplication {
public static void main(String[] args) {
SpringApplication.run(CmsApplication.class, args);
}
}
该机制由 spring-boot-autoconfigure 模块驱动,扫描 META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports 文件加载候选配置,极大简化了传统Spring应用的繁琐配置流程。
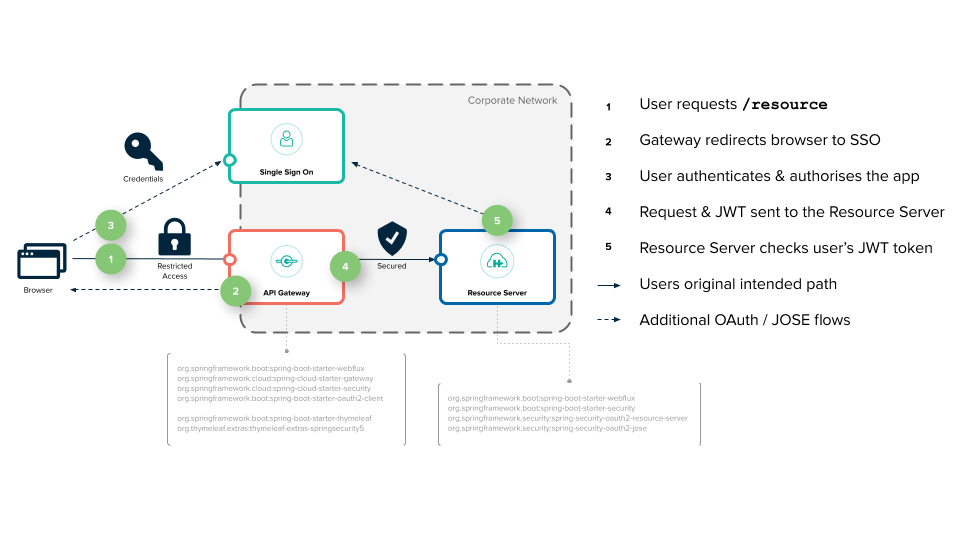
2. 用户管理模块设计与Spring Security安全控制
在现代企业级内容管理系统(CMS)中,用户管理不仅是系统功能的起点,更是整个平台安全体系的核心支柱。随着前后端分离架构的普及和微服务技术的发展,传统的基于会话的安全机制已难以满足复杂场景下的权限控制需求。因此,构建一个灵活、可扩展且高安全性的用户管理体系成为系统设计的关键环节。本章节聚焦于用户管理模块的整体设计思路,并深入探讨如何借助 Spring Security 框架实现强大的认证与授权能力,保障系统的数据安全与访问合规性。
用户管理不仅涉及用户的增删改查操作,更涵盖了身份验证、权限分配、角色继承、会话管理以及细粒度的资源控制等多个维度。尤其在多租户或大型组织结构的应用场景下,权限模型必须支持动态配置与层级化管理,以应对不断变化的业务规则。Spring Security 作为 Java 生态中最成熟的安全框架之一,提供了从基础过滤器链到高级表达式驱动访问控制的完整解决方案,能够无缝集成到 Spring Boot 项目中,极大提升了开发效率与系统安全性。
本章将从理论出发,剖析主流认证协议 OAuth2 和 JWT 的工作机制,结合基于角色的访问控制(RBAC)模型,建立清晰的安全设计蓝图。随后进入实践层面,详细展示如何通过 SecurityConfig 配置类实现 URL 路径拦截、登录认证流程定制、自定义用户加载逻辑及密码加密策略。进一步地,还将介绍方法级别的注解式权限控制(如 @PreAuthorize ),使权限判断可以精确到具体业务方法调用,提升系统的灵活性与可维护性。最后,在前后端分离背景下,讨论 Token 的生成、传递与刷新机制,确保无状态会话下的长期可用性和安全性。
整个用户管理模块的设计遵循“最小权限原则”与“职责分离原则”,即每个用户仅拥有完成其职责所必需的最低限度权限,避免越权操作风险。同时,系统支持权限分组与多角色分配,允许管理员根据组织架构灵活配置用户权限,适应不同部门、岗位的差异化需求。数据库层面采用规范化建模方式,确保用户、角色、权限三者之间的关系清晰可追溯,便于后期审计与权限变更追踪。
此外,考虑到高并发环境下的性能影响,本章也会对安全过滤器链进行优化建议,包括缓存用户权限信息、减少数据库查询次数、使用异步日志记录等方式,在保证安全性的前提下提升系统响应速度。最终目标是打造一个既符合行业标准又具备高度可定制性的用户权限控制系统,为后续内容管理、分类标签等核心功能提供坚实的安全支撑。
2.1 用户认证与授权机制的理论基础
在构建安全可靠的 CMS 系统过程中,理解用户认证(Authentication)与授权(Authorization)的基本原理是设计有效安全策略的前提。两者虽常被并列提及,但其职责截然不同:认证解决“你是谁”的问题,而授权则决定“你能做什么”。只有在正确完成身份识别的基础上,才能实施合理的权限控制。当前主流的技术方案主要包括 OAuth2 协议、JWT(JSON Web Token)令牌机制以及基于角色的访问控制(RBAC)模型,它们共同构成了现代 Web 应用安全体系的三大基石。
2.1.1 OAuth2、JWT与基于角色的访问控制(RBAC)模型
OAuth2 是一种开放授权协议框架,广泛应用于第三方应用访问资源服务器的场景中,例如用户使用微信账号登录某网站。它并不直接处理用户认证,而是专注于授权流程,允许资源所有者授予第三方有限的访问权限,而无需共享原始凭证。OAuth2 定义了四种典型授权模式:授权码模式(Authorization Code)、隐式模式(Implicit)、客户端凭证模式(Client Credentials)和密码模式(Resource Owner Password Credentials)。其中,密码模式虽然简单直接,但在生产环境中应谨慎使用,因其要求客户端获取用户明文密码,存在较大安全隐患。
相比之下,JWT 是一种轻量级的、自包含的身份验证机制,适用于分布式系统中的无状态认证。JWT 由三部分组成:头部(Header)、载荷(Payload)和签名(Signature),通常以 Base64 编码拼接成字符串形式传输。载荷中可携带用户 ID、角色、过期时间等声明信息,服务端通过验证签名即可确认 Token 的合法性,无需查询数据库或依赖会话存储。这种特性使其非常适合前后端分离和微服务架构,但也带来了 Token 注销难题——由于无状态性,无法像传统 Session 一样主动销毁,需配合黑名单机制或短期有效期来缓解风险。
RBAC(Role-Based Access Control)是一种经典的权限管理模型,核心思想是将权限与角色绑定,再将角色分配给用户,从而实现权限的集中管理和简化配置。典型的 RBAC 模型包含三个基本元素:用户(User)、角色(Role)和权限(Permission)。权限代表对某一资源的操作能力(如“文章删除”),角色是一组权限的集合(如“编辑员”、“管理员”),用户通过被赋予一个或多个角色获得相应权限。该模型支持角色继承、权限分组和层级结构,易于扩展至大规模系统。例如,可定义“超级管理员”角色继承“普通管理员”的所有权限,并额外增加系统设置权限。
以下表格对比了三种关键技术的核心特征:
| 特性 | OAuth2 | JWT | RBAC |
|---|---|---|---|
| 主要用途 | 第三方授权 | 身份认证 | 权限控制 |
| 是否需要中心认证服务器 | 是 | 否(可选) | 否 |
| 状态性 | 通常有状态 | 无状态 | 通常有状态 |
| 适用场景 | SSO、API 授权 | 前后端分离、微服务 | 内部系统权限管理 |
| 安全性考量 | 需防范 CSRF、Token 泄露 | 需防重放攻击、Token 刷新机制 | 需防止权限滥用、越权访问 |
为了更直观地展示 RBAC 模型的数据流与交互关系,以下是使用 Mermaid 绘制的权限结构流程图:
graph TD
A[用户] --> B(角色)
B --> C{权限}
C --> D[资源: 文章]
C --> E[资源: 用户管理]
C --> F[资源: 分类设置]
style A fill:#f9f,stroke:#333
style D fill:#bbf,stroke:#333,color:#fff
该图展示了用户通过角色间接获得对各类资源的操作权限,体现了权限解耦的设计理念。当权限发生变更时,只需调整角色所拥有的权限集合,而不必逐个修改用户权限,极大提升了维护效率。
在实际系统中,这三种技术往往协同工作。例如,前端发起登录请求后,后端验证用户名密码,若成功则生成包含用户角色信息的 JWT 返回给客户端;后续每次请求携带此 Token,网关或拦截器解析 JWT 获取用户身份,并结合 RBAC 模型判断是否具有访问目标接口的权限。整个过程实现了认证与授权的分离,提升了系统的模块化程度与可测试性。
值得注意的是,尽管这些技术已被广泛应用,但在具体实施中仍需注意诸多细节。例如,JWT 的签名算法应优先选择 HMAC-SHA256 或 RSA 等强加密方式,避免使用 none 算法导致安全漏洞;OAuth2 中的 redirect_uri 必须严格校验,防止开放重定向攻击;RBAC 模型中应引入权限审批流程,防止权限过度集中引发内部威胁。
综上所述,OAuth2 提供了标准化的授权通道,JWT 实现了高效的身份传递,而 RBAC 则构建了结构化的权限管理体系。三者相辅相成,构成了现代 CMS 系统安全架构的理论基础。接下来的内容将进一步探讨如何在 Spring Security 中落地这些理念。
2.1.2 安全上下文、会话管理与权限粒度设计
安全上下文(Security Context)是 Spring Security 的核心概念之一,用于保存当前用户的认证信息( Authentication 对象),在整个请求生命周期中可供任意组件访问。该上下文默认存储在线程本地变量( ThreadLocal )中,确保每个线程独立持有自己的安全状态,避免并发冲突。开发者可通过 SecurityContextHolder.getContext().getAuthentication() 方法获取当前用户详情,进而提取用户名、权限列表等信息用于业务逻辑判断。
会话管理方面,传统 Web 应用依赖服务器端 Session 存储用户状态,优点是易于控制会话生命周期(如强制下线、超时失效),缺点是难以横向扩展,尤其在集群环境下需引入 Session 共享机制(如 Redis)。而在前后端分离架构中,越来越多系统转向无状态认证模式,即使用 JWT 替代 Session。此时,用户登录后服务器签发 Token,客户端将其存入 localStorage 或 cookie,并在后续请求的 Authorization 头中携带 Bearer <token> 。服务端通过解析 Token 验证有效性,不再依赖任何会话存储。
然而,完全无状态也带来挑战。最突出的问题是无法主动使 Token 失效。为此,常见的解决方案包括:
- 设置较短的过期时间(如 15 分钟),配合 Refresh Token 机制延长登录态;
- 使用 Redis 构建 Token 黑名单,记录已注销的 Token,在每次请求时检查是否在黑名单内;
- 引入 Token 版本号或用户票据(User Ticket),当用户登出或修改密码时更新版本号,使旧 Token 自动失效。
权限粒度设计决定了系统能否精准控制用户行为。粗粒度权限可能造成“权限爆炸”问题——即为每一个操作单独设置权限,导致管理复杂;而过粗的权限划分又可能导致权限泛滥。理想的权限设计应在“功能级”与“数据级”之间取得平衡。功能级权限控制用户能否执行某个操作(如“新增文章”),数据级权限则限制其可操作的数据范围(如“只能编辑自己创建的文章”)。
Spring Security 支持基于 SpEL(Spring Expression Language)的表达式访问控制,可在方法或配置中编写复杂的权限判断逻辑。例如:
@PreAuthorize("hasRole('ADMIN') or #userId == authentication.principal.id")
public User updateUser(Long userId, UserUpdateDTO dto) {
// 更新逻辑
}
上述代码表示:只有管理员角色或当前登录用户为自己时,才允许调用该方法。这里的 authentication.principal 即指代安全上下文中存储的主体对象,通常是 UserDetails 实现类实例。
为更好地组织权限体系,建议采用如下分层结构:
| 层级 | 示例 |
|---|---|
| 模块级 | 内容管理、用户管理、系统设置 |
| 功能级 | 查看列表、新增、编辑、删除 |
| 数据级 | 自己的数据、本部门数据、全部数据 |
通过这种三级权限划分,既能满足常规管理需求,又能为未来扩展预留空间。例如,在内容管理模块中,“编辑员”角色可拥有“内容管理-编辑-自己的数据”权限,而“审核员”则拥有“内容管理-审核-本部门数据”权限。
此外,权限命名建议统一采用前缀标识法,如 content:write:self 、 user:delete:any ,便于程序解析与前端展示。后台管理系统可提供可视化权限配置界面,允许管理员拖拽勾选权限项并实时预览效果,提升易用性。
总之,安全上下文提供了运行时的身份感知能力,会话管理决定了系统的扩展性与安全性边界,而权限粒度设计直接影响用户体验与系统可控性。三者共同作用,形成完整的安全闭环。在下一节中,将进入具体编码阶段,演示如何在 Spring Boot 项目中集成 Spring Security 并实现上述理论模型。
// 示例:自定义 AuthenticationEntryPoint,用于处理未认证访问
@Component
public class JwtAuthenticationEntryPoint implements AuthenticationEntryPoint {
@Override
public void commence(HttpServletRequest request,
HttpServletResponse response,
AuthenticationException authException) throws IOException {
response.setStatus(HttpServletResponse.SC_UNAUTHORIZED);
response.setContentType("application/json");
response.getWriter().write("{\"error\": \"Unauthorized\", \"message\": \""
+ authException.getMessage() + "\"}");
}
}
代码逻辑逐行解读:
1. @Component :将此类注册为 Spring Bean,以便自动注入。
2. JwtAuthenticationEntryPoint 实现 AuthenticationEntryPoint 接口,用于定义当用户未登录却访问受保护资源时的响应行为。
3. commence() 方法被调用时,设置 HTTP 状态码为 401(未授权),并返回 JSON 格式的错误信息,便于前端统一处理。
4. 输出流写入结构化响应体,包含错误类型和具体消息,增强调试友好性。
该组件将在 Security 配置中注册,作为全局异常处理的一部分,确保所有未认证请求都能得到一致反馈。
3. 内容管理功能实现(文章/新闻/产品等内容类型)
在现代企业级内容管理系统(CMS)中,内容的多样性决定了系统架构必须具备高度可扩展性和灵活性。无论是发布一篇新闻、上架一个产品,还是更新一则公告,这些操作背后都依赖于统一的内容建模机制与高效稳定的业务逻辑支撑。随着微服务架构和前后端分离模式的普及,Spring Boot 作为后端开发的核心框架,在内容管理模块中扮演着至关重要的角色。本章将深入探讨如何基于 Spring Web MVC 实现一套通用性强、可维护性高的内容管理功能体系。
内容管理不仅仅是增删改查(CRUD)的简单叠加,更涉及状态流转控制、权限边界隔离、富文本编辑集成、文件上传处理以及前端交互联动等多个维度。尤其是在多内容类型的场景下,如文章、新闻、产品、公告等并存时,若采用各自独立的实体模型会导致代码重复率高、维护成本上升。因此,设计一个抽象层次合理的统一内容模型成为首要任务。同时,为保障系统的稳定性与用户体验的一致性,还需引入异常统一处理机制、RESTful 接口规范、审核流程状态机等关键组件。
通过本章的学习,开发者将掌握从领域建模到接口实现,再到前后端协同开发的完整链路。我们将以实际项目需求为导向,结合 JPA 持久化技术、Spring Security 安全控制、Vue.js 前端框架及文件存储策略,构建一个支持多种内容类型、具备发布生命周期管理和后台可视化操作的功能闭环。这不仅适用于传统 CMS 系统,也可拓展至电商平台、知识库系统或企业门户平台等多种应用场景。
3.1 内容模型抽象与业务逻辑分析
在复杂的内容管理系统中,不同内容类型之间往往存在共性字段与行为特征。例如,“标题”、“摘要”、“封面图”、“创建时间”、“作者”、“状态”等属性几乎贯穿所有内容实体。如果对每种内容单独建表建类,则会造成大量冗余代码,并增加后期维护难度。为此,有必要进行合理的领域抽象,建立统一的内容模型结构,提升系统的可复用性与扩展能力。
3.1.1 多内容类型的统一实体设计(Content、Article、Product等)
为了应对不同类型内容的数据异构问题,可以采用“基类+子类”的继承式建模方法。Spring Data JPA 支持三种继承策略: SINGLE_TABLE 、 TABLE_PER_CLASS 和 JOINED 。其中, SINGLE_TABLE 将所有子类数据存储在同一张表中,使用鉴别列(DTYPE)区分类型; TABLE_PER_CLASS 为每个子类生成独立表,但不支持跨类型联合查询;而 JOINED 则采用主键关联的方式分表存储,兼顾规范化与查询性能。
以下是基于 JOINED 策略设计的统一内容模型示例:
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "content_type")
public abstract class Content {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String title; // 标题
@Lob
private String summary; // 摘要
@Lob
private String contentBody; // 正文内容
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "author_id")
private User author;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private ContentStatus status; // 草稿、审核中、已上线、已下架
@Column(name = "cover_image_url")
private String coverImageUrl;
@CreationTimestamp
@Column(name = "created_at")
private LocalDateTime createdAt;
@UpdateTimestamp
@Column(name = "updated_at")
private LocalDateTime updatedAt;
// Getters and Setters
}
@Entity
public class Article extends Content {
@Column(name = "source_url")
private String sourceUrl; // 来源链接
@ElementCollection
@CollectionTable(name = "article_tags", joinColumns = @JoinColumn(name = "article_id"))
@Column(name = "tag")
private Set<String> tags = new HashSet<>();
}
@Entity
public class Product extends Content {
@Column(precision = 10, scale = 2)
private BigDecimal price;
@Column(name = "sku_code", unique = true)
private String skuCode;
@OneToMany(mappedBy = "product", cascade = CascadeType.ALL, orphanRemoval = true)
private List<ProductImage> images = new ArrayList<>();
}
表格:内容模型字段对比
| 字段名 | 是否共享 | 类型 | 说明 |
|---|---|---|---|
| title | 是 | String | 所有内容共有 |
| summary | 是 | Text (Lob) | 内容简介 |
| contentBody | 是 | Text (Lob) | 主体内容,支持HTML |
| author | 是 | User (ManyToOne) | 关联用户表 |
| status | 是 | ENUM | 发布状态 |
| coverImageUrl | 是 | String | 封面图片URL |
| createdAt | 是 | LocalDateTime | 自动生成 |
| updatedAt | 是 | LocalDateTime | 自动更新 |
| sourceUrl | 否 | String | 仅限文章 |
| tags | 否 | Collection | 文章标签集合 |
| price | 否 | BigDecimal | 商品价格 |
| skuCode | 否 | String | 商品唯一编码 |
该设计实现了良好的职责分离与扩展能力。当未来需要新增“视频内容”或“问答条目”时,只需继承 Content 类即可快速接入现有系统流程。
Mermaid 流程图:内容模型类关系图
classDiagram
class Content {
+Long id
+String title
+String summary
+String contentBody
+User author
+ContentStatus status
+String coverImageUrl
+LocalDateTime createdAt
+LocalDateTime updatedAt
}
class Article {
+String sourceUrl
+Set~String~ tags
}
class Product {
+BigDecimal price
+String skuCode
+List~ProductImage~ images
}
class ProductImage {
+String imageUrl
+Integer sortOrder
}
Content <|-- Article
Content <|-- Product
Product --> ProductImage : 1..*
上述类图清晰展示了继承关系与聚合结构,有助于团队成员理解整体数据模型拓扑。
代码逻辑逐行解读:
-
@Inheritance(strategy = InheritanceType.JOINED):指定使用连接表继承策略,避免单表膨胀。 -
@DiscriminatorColumn:虽然 JOINED 不强制要求,但保留该字段便于调试与日志追踪。 -
@Lob注解用于标记大对象字段,适配 MySQL 的 TEXT 或 PostgreSQL 的 TEXT 类型。 -
@CreationTimestamp与@UpdateTimestamp来自 Hibernate,自动填充时间戳。 -
@ElementCollection用于映射基本类型的集合,适合轻量级标签管理。
参数说明:
- fetch = FetchType.LAZY 避免一次性加载作者信息,提高查询效率。
- cascade = CascadeType.ALL 在商品删除时同步删除其图片记录,确保数据一致性。
- 使用 BigDecimal 而非 double 处理金额,防止浮点数精度丢失。
此模型设计兼顾了数据库规范化与应用层易用性,是实现多内容类型统一管理的基础。
3.1.2 状态机在内容发布流程中的应用(草稿、审核、上线、下架)
内容的生命周期通常包含多个阶段:新建 → 草稿 → 提交审核 → 审核通过/拒绝 → 上线 → 下架。直接使用枚举值判断状态转移容易导致逻辑分散、难以维护。引入状态机(State Machine)模式可集中管理状态变迁规则,增强业务可控性。
Spring 官方提供了 Spring State Machine 框架,专用于建模有限状态机。以下是一个典型的内容发布状态机配置示例:
@Configuration
@EnableStateMachine
public class ContentStateMachineConfig extends EnumStateMachineConfigurerAdapter<ContentStatus, ContentEvent> {
@Override
public void configure(StateMachineStateConfigurer<ContentStatus, ContentEvent> states) throws Exception {
states
.withStates()
.initial(ContentStatus.DRAFT)
.states(EnumSet.allOf(ContentStatus.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<ContentStatus, ContentEvent> transitions) throws Exception {
transitions
.withExternal()
.source(ContentStatus.DRAFT).target(ContentStatus.PENDING_REVIEW)
.event(ContentEvent.SUBMIT_FOR_REVIEW)
.action(submitForReviewAction())
.and()
.withExternal()
.source(ContentStatus.PENDING_REVIEW).target(ContentStatus.PUBLISHED)
.event(ContentEvent.APPROVE)
.action(approveAction())
.and()
.withExternal()
.source(ContentStatus.PENDING_REVIEW).target(ContentStatus.REJECTED)
.event(ContentEvent.REJECT)
.action(rejectAction())
.and()
.withExternal()
.source(ContentStatus.PUBLISHED).target(ContentStatus.OFFLINE)
.event(ContentEvent.UNPUBLISH)
.action(unpublishAction());
}
@Bean
public Action<ContentStatus, ContentEvent> submitForReviewAction() {
return context -> {
Long contentId = context.getMessageHeader("contentId");
System.out.println("内容[" + contentId + "]已提交审核");
// 可触发邮件通知、日志记录等
};
}
// 其他动作省略...
}
定义状态与事件枚举:
public enum ContentStatus {
DRAFT, PENDING_REVIEW, PUBLISHED, REJECTED, OFFLINE
}
public enum ContentEvent {
SUBMIT_FOR_REVIEW, APPROVE, REJECT, UNPUBLISH
}
表格:状态转移合法性校验表
| 当前状态 | 触发事件 | 目标状态 | 是否允许 |
|---|---|---|---|
| DRAFT | SUBMIT_FOR_REVIEW | PENDING_REVIEW | ✅ |
| PENDING_REVIEW | APPROVE | PUBLISHED | ✅ |
| PENDING_REVIEW | REJECT | REJECTED | ✅ |
| PUBLISHED | UNPUBLISH | OFFLINE | ✅ |
| OFFLINE | 任意 | - | ❌(需重新编辑) |
通过状态机配置,非法状态跳转将被自动拦截,从而保证业务流程的严谨性。
Mermaid 流程图:内容发布状态机转换图
stateDiagram-v2
[*] --> DRAFT
DRAFT --> PENDING_REVIEW : SUBMIT_FOR_REVIEW
PENDING_REVIEW --> PUBLISHED : APPROVE
PENDING_REVIEW --> REJECTED : REJECT
PUBLISHED --> OFFLINE : UNPUBLISH
OFFLINE --> DRAFT : EDIT & RESUBMIT
REJECTED --> DRAFT : REVISE
该图直观表达了各状态间的流转路径与触发条件。
代码逻辑逐行解读:
-
@EnableStateMachine启用状态机功能。 -
configure(states)定义初始状态与所有可能状态集合。 -
configure(transitions)配置外部状态转移规则,withExternal()表示非内部自转换。 -
action()方法注入执行动作,可用于记录日志、发送消息、更新缓存等副作用操作。 - 使用
context.getMessageHeader("contentId")获取上下文参数,实现事件驱动编程。
参数说明:
- source() 与 target() 明确状态迁移方向。
- .event() 绑定触发事件,由客户端调用触发。
- 动作 Bean 应声明为 @Bean 并注册进容器,以便状态机调用。
在服务层调用状态机:
@Autowired
private StateMachine<ContentStatus, ContentEvent> stateMachine;
public void submitToReview(Long contentId) {
stateMachine.sendEvent(MessageBuilder.withPayload(ContentEvent.SUBMIT_FOR_REVIEW)
.setHeader("contentId", contentId)
.build());
}
该方式将状态变更逻辑集中化,避免散落在各个 service 方法中,极大提升了可测试性与可维护性。
综上所述,统一内容模型与状态机机制相结合,构成了内容管理系统的骨架。前者解决数据结构复用问题,后者保障业务流程有序运行。二者共同作用,使得系统既能灵活应对多样化内容形态,又能严格遵循预设的工作流规则。
4. 分类与标签系统设计与数据库建模
在现代内容管理系统(CMS)中,分类与标签系统是信息组织和检索的核心机制。它们不仅决定了内容的可读性、可维护性和扩展性,还直接影响到前端展示效果与用户体验。一个结构合理、性能高效的分类与标签体系,能够支撑起从内容归档、推荐算法到搜索优化等多维度的应用场景。尤其在面对复杂的内容类型(如文章、新闻、产品)时,如何通过数据库建模实现灵活的层级管理、快速的标签聚合以及高性能的数据查询,成为系统架构中的关键挑战。
本章节深入探讨分类与标签系统的理论基础与工程实践,结合Spring Boot与JPA技术栈,围绕树形结构存储策略、多对多关系映射、索引优化及接口封装等方面展开详细分析。通过对比递归查询、闭包表与左右值编码三种主流方案,评估其在不同业务规模下的适用性;同时,针对标签频率统计与自动补全功能,提出基于数据库聚合与缓存协同的设计思路。最终目标是构建一个既满足无限层级分类需求,又能支持高并发标签操作的通用化数据模型,并为前后端提供稳定、低延迟的API服务。
4.1 分类体系的树形结构理论与算法支持
分类体系作为内容组织的基本骨架,通常表现为具有父子关系的层级结构,例如“科技 > 编程语言 > Java”这样的路径表达。这种结构天然适合用树形数据模型来表示,但在关系型数据库中直接存储和查询树结构存在诸多挑战,尤其是在需要频繁进行子树遍历、路径获取或层级排序的场景下。传统邻接表模型虽然直观,但递归查询效率低下,难以应对深层嵌套或大规模节点的操作。因此,业界发展出多种高级建模模式以提升性能与可维护性,其中最具代表性的是 闭包表(Closure Table) 和 左右值编码(Nested Set Model) 。
4.1.1 递归查询与闭包表(Closure Table)模式对比
在标准邻接表模型中,每个节点仅保存其父节点ID,形成如下结构:
CREATE TABLE category (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
parent_id BIGINT,
FOREIGN KEY (parent_id) REFERENCES category(id)
);
该模型简单明了,但在执行“查找某节点的所有后代”这类操作时需依赖递归SQL(如MySQL 8+的CTE),否则必须通过应用层循环查询,性能较差。例如,在不支持递归CTE的老版本数据库中,无法高效完成深度遍历。
为解决这一问题, 闭包表模式 引入一张独立的关系表 category_closure ,用于显式记录任意两个节点之间的祖先-后代关系及其距离(层级跨度)。其结构如下:
| 字段名 | 类型 | 说明 |
|---|---|---|
| ancestor_id | BIGINT | 祖先节点ID |
| descendant_id | BIGINT | 后代节点ID |
| depth | INT | 两者之间相隔的层级数(0表示自身) |
CREATE TABLE category_closure (
ancestor_id BIGINT,
descendant_id BIGINT,
depth INT,
PRIMARY KEY (ancestor_id, descendant_id),
FOREIGN KEY (ancestor_id) REFERENCES category(id),
FOREIGN KEY (descendant_id) REFERENCES category(id)
);
当插入新节点时,除了在主表中添加记录外,还需向闭包表中插入所有可达路径组合。例如,若节点C是B的子节点,而B又是A的子节点,则需插入 (A,C,2) 、 (B,C,1) 和 (C,C,0) 三条记录。
使用此模型后,“获取某分类下的所有子分类”可通过单次JOIN完成:
SELECT c.*
FROM category c
JOIN category_closure cc ON c.id = cc.descendant_id
WHERE cc.ancestor_id = ? AND cc.depth > 0;
该查询具备极高的执行效率,时间复杂度为 O(n),且完全避免了递归调用。此外,还可轻松实现诸如“查找共同祖先”、“判断是否为后代”等高级操作。
相比之下,邻接表虽写入快、结构简洁,但读取成本高;闭包表则以空间换时间,在读密集型系统中优势显著,尤其适用于后台管理界面中频繁展开分类树的场景。
下面是一个使用Mermaid绘制的闭包表示意图:
graph TD
A[Category A] --> B[Category B]
A --> C[Category C]
B --> D[Category D]
subgraph Closure Table Entries
A -.-> A [depth=0]
A -.-> B [depth=1]
A -.-> C [depth=1]
A -.-> D [depth=2]
B -.-> B [depth=0]
B -.-> D [depth=1]
C -.-> C [depth=0]
D -.-> D [depth=0]
end
尽管闭包表提升了查询性能,但也带来了额外的维护开销——每次增删改节点都需同步更新闭包表。为此,建议将其封装为数据库触发器或服务层事务逻辑,确保一致性。
4.1.2 左右值编码(Nested Set)在无限层级分类中的应用
另一种广泛应用于无限层级分类的技术是 左右值编码模型(Nested Set Model) ,它通过为每个节点分配一对整数(左值 lft 和右值 rgt )来表示整个树的拓扑结构。这些数值遵循特定规则:每个节点的左值小于其所有子孙节点的左值,右值大于所有子孙节点的右值,且整个子树的范围被包含在其 lft 与 rgt 之间。
其典型表结构如下:
CREATE TABLE nested_category (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
lft INT NOT NULL UNIQUE,
rgt INT NOT NULL UNIQUE,
level INT DEFAULT 0 -- 可选:用于记录当前层级
);
假设我们有以下分类结构:
Electronics (1, 10)
├── Computers (2, 7)
│ ├── Laptops (3, 4)
│ └── Desktops (5, 6)
└── Mobile Phones (8, 9)
对应的左右值分配如下:
| id | name | lft | rgt | level |
|---|---|---|---|---|
| 1 | Electronics | 1 | 10 | 0 |
| 2 | Computers | 2 | 7 | 1 |
| 3 | Laptops | 3 | 4 | 2 |
| 4 | Desktops | 5 | 6 | 2 |
| 5 | Mobile Phones | 8 | 9 | 1 |
利用该结构,“查询某节点的所有子节点”变得极为高效:
SELECT nc.*
FROM nested_category nc
JOIN nested_category parent ON parent.name = 'Computers'
WHERE nc.lft > parent.lft AND nc.rgt < parent.rgt;
这是一次简单的范围扫描,配合对 lft 和 rgt 的联合索引,可在毫秒级返回结果。
更重要的是,该模型天然支持整棵子树的移动、复制与删除。例如,将“Mobile Phones”移至“Computers”下,只需重新计算其及其后代的左右值并调整相关区间的偏移量即可。
然而,Nested Set的最大缺陷在于 写入代价高昂 :任何节点的插入或删除都会导致大量后续节点的左右值重排。例如,在根节点下新增一个子项,可能需要更新数千条记录的 lft 和 rgt 值。因此,该模型更适合静态或低频变更的分类体系,如电商类目、图书目录等。
为缓解此问题,部分系统采用“间隔预留法”,即初始分配较大的步长(如每步100),以便在中间插入新节点时不立即触发重排。例如:
INSERT INTO nested_category (name, lft, rgt) VALUES ('Tablets', 400, 499);
只要区间未满,便可自由插入而不影响其他节点。只有当空间耗尽时才触发整体重构。
综上所述,选择何种树形结构应根据具体业务特征权衡:
| 模型 | 查询性能 | 写入性能 | 实现难度 | 适用场景 |
|---|---|---|---|---|
| 邻接表 + CTE | 中等 | 高 | 低 | 小型树、现代数据库环境 |
| 闭包表 | 高 | 中 | 中 | 中大型树、频繁查询 |
| 左右值编码 | 高 | 低 | 高 | 静态/低频更新、深层数结构 |
实际项目中,推荐优先考虑闭包表方案,因其在灵活性与性能之间取得了良好平衡,且易于与JPA/Hibernate集成。
4.2 标签系统的去重、聚合与权重计算
标签系统作为内容语义化的补充手段,允许用户通过关键词自由标注资源,从而打破固定分类的局限性,增强内容发现能力。与分类不同,标签强调非结构性、多维关联与动态演化,常用于生成“标签云”、驱动个性化推荐或辅助搜索引擎优化。然而,标签的开放性也带来了诸如重复命名、拼写错误、权重失衡等问题,亟需一套完整的治理机制保障数据质量。
4.2.1 标签云生成算法与使用频率统计
标签云是一种可视化组件,通过字体大小、颜色深浅等方式反映标签的流行程度。其实现核心在于准确统计各标签的出现频率,并据此计算权重值。常见的权重函数包括线性缩放、对数变换或分位数映射。
首先定义标签实体:
@Entity
@Table(name = "tag")
public class Tag {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true, nullable = false)
private String name;
@Column(name = "usage_count", columnDefinition = "BIGINT DEFAULT 0")
private Long usageCount = 0L;
// getter/setter
}
每当一篇文章被标记某个标签时,应在事务中同步增加其 usageCount :
@Transactional
public void addTagToContent(Long contentId, String tagName) {
Content content = contentRepository.findById(contentId)
.orElseThrow(() -> new EntityNotFoundException("Content not found"));
Tag tag = tagRepository.findByName(tagName)
.orElseGet(() -> {
Tag newTag = new Tag();
newTag.setName(tagName);
newTag.setUsageCount(1L);
return tagRepository.save(newTag);
});
if (!content.getTags().contains(tag)) {
content.getTags().add(tag);
tag.setUsageCount(tag.getUsageCount() + 1); // 更新计数
tagRepository.save(tag);
contentRepository.save(content);
}
}
代码逻辑逐行解读:
-
@Transactional:确保整个操作处于同一事务中,防止计数与关联状态不一致。 -
findByName():尝试加载已有标签,避免重复创建。 -
orElseGet():若标签不存在,则构造新实例并初始化计数为1。 -
if (!contains):检查是否已关联,防止重复绑定。 -
tag.setUsageCount(...):递增全局使用次数。 - 最终保存标签与内容对象。
随后,可通过以下SQL统计所有标签的热度:
SELECT name, usage_count
FROM tag
ORDER BY usage_count DESC
LIMIT 50;
前端接收后可按如下方式计算显示权重:
function generateTagCloud(tags) {
const max = Math.max(...tags.map(t => t.usageCount));
const min = Math.min(...tags.map(t => t.usageCount));
const range = max - min || 1;
return tags.map(tag => ({
...tag,
weight: 1 + 4 * (tag.usageCount - min) / range // 映射到1~5级
}));
}
该算法将频率线性映射至预设字号等级,也可替换为对数函数以突出头部标签。
4.2.2 多对多关系映射在JPA中的实现(@ManyToMany)
在JPA中,内容与标签之间属于典型的多对多关系。可通过 @ManyToMany 注解建立双向关联:
@Entity
@Table(name = "content")
public class Content {
@Id
private Long id;
private String title;
@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
@JoinTable(
name = "content_tag",
joinColumns = @JoinColumn(name = "content_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private Set<Tag> tags = new HashSet<>();
// getter/setter
}
对应地, Tag 类也应维护反向引用:
@ManyToMany(mappedBy = "tags")
private Set<Content> contents = new HashSet<>();
参数说明:
-
cascade: 设置级联行为,PERSIST表示保存内容时自动保存新标签,MERGE支持更新。 -
@JoinTable: 指定中间表名称及外键列。 -
mappedBy: 在被控方声明,指向拥有方的属性名。
该配置自动生成中间表 content_tag(content_id, tag_id) ,并由Hibernate自动管理关联记录的增删。
但需注意:默认 FetchType.LAZY,若未开启Open Session in View或手动fetch join,访问 tags 时会抛出 LazyInitializationException 。建议在Repository中显式定义投影查询:
@Query("SELECT c.id, c.title, COUNT(ct.tagId) as tagCount " +
"FROM Content c LEFT JOIN content_tag ct ON c.id = ct.contentId " +
"GROUP BY c.id, c.title")
List<Object[]> findContentWithTagStats();
此外,为提升标签查询性能,应在 content_tag(tag_id) 上建立索引:
CREATE INDEX idx_content_tag_tag ON content_tag(tag_id);
4.3 数据库表结构设计与性能优化
4.3.1 分类表、标签表与内容关联表的设计范式遵循
合理的数据库设计应遵循第三范式(3NF),消除冗余并保证数据一致性。以下是整合后的核心表结构:
| 表名 | 主要字段 | 说明 |
|---|---|---|
category | id, name, parent_id | 分类主表(邻接表) |
category_closure | ancestor_id, descendant_id, depth | 闭包表,支持高效树查询 |
tag | id, name, usage_count | 标签字典表 |
content | id, title, status, category_id, created_at | 内容主表 |
content_tag | content_id, tag_id | 多对多关联表 |
所有外键均建立约束,确保引用完整性。对于分类路径查询,可创建物化视图或缓存常见结果集。
4.3.2 联合索引建立与高频查询语句的执行计划调优
针对高频查询:
-- 查询某分类下的所有上线内容
EXPLAIN SELECT c.*
FROM content c
JOIN category_closure cc ON c.category_id = cc.descendant_id
WHERE cc.ancestor_id = 1 AND c.status = 'PUBLISHED';
应在 (status, category_id) 上建立联合索引:
CREATE INDEX idx_content_status_category ON content(status, category_id);
并通过 EXPLAIN 分析执行计划,确认是否命中索引、避免全表扫描。
4.4 接口封装与前端动态渲染支持
4.4.1 提供分类树JSON输出接口并支持懒加载
@GetMapping("/categories/tree")
public ResponseEntity<List<CategoryTreeNode>> getCategoryTree(@RequestParam(required = false) Long parentId) {
List<Category> categories = (parentId == null) ?
categoryRepository.findByParentIdIsNull() :
categoryRepository.findByParentId(parentId);
List<CategoryTreeNode> nodes = categories.stream()
.map(c -> new CategoryTreeNode(c.getId(), c.getName(), hasChildren(c.getId())))
.collect(Collectors.toList());
return ResponseEntity.ok(nodes);
}
private boolean hasChildren(Long id) {
return categoryRepository.countByParentId(id) > 0;
}
前端可基于此实现异步加载子节点。
4.4.2 标签自动补全建议功能(Autocomplete API)实现
@GetMapping("/tags/suggest")
public ResponseEntity<List<String>> suggestTags(@RequestParam String prefix) {
List<String> suggestions = tagRepository.findTop10ByNameStartingWithOrderByUsageCountDesc(prefix);
return ResponseEntity.ok(suggestions);
}
配合Redis缓存热门标签,进一步降低数据库压力。
5. 内容版本控制机制与历史记录管理
在现代内容管理系统(CMS)中,内容的生命周期往往不是静态的。一篇文章可能经历多次修改、审核、回滚甚至恢复操作。为了保障内容变更过程的可追溯性与安全性,建立一套完整的内容版本控制机制显得尤为关键。该机制不仅服务于编辑人员对历史状态的查看与还原需求,也为企业级系统提供了审计追踪能力。从技术角度看,版本控制不仅仅是数据快照的存储,更涉及数据库设计、业务逻辑解耦、性能优化以及用户交互体验等多个层面。
本章将深入探讨如何基于Spring Boot框架构建高效、灵活且具备扩展性的内容版本控制系统。通过引入领域驱动设计思想,结合JPA持久化策略与AOP切面编程,实现自动化的版本生成与管理流程。同时,分析不同版本存储模型的优劣,并针对大规模内容场景下的查询效率问题提出优化方案。最终目标是打造一个既能满足日常运营需要,又能支撑高并发读写访问的版本管理体系。
5.1 内容版本控制的设计模式与架构选型
内容版本控制的核心在于“状态保存”与“差异比较”。当内容发生更新时,系统需判断是否触发新版本创建动作,并将旧版本信息妥善归档。这一过程中,首要任务是选择合适的架构模型来支持长期演进的需求。常见的实现方式包括全量快照模式、增量差分模式和混合模式三种。
5.1.1 全量快照 vs 增量差分:存储策略对比分析
全量快照是指每次内容修改都将其完整数据复制一份并保存至版本表中。这种方式实现简单,读取速度快,因为每个版本都是独立完整的实体,无需额外计算即可展示。然而其缺点在于空间占用较大,尤其对于频繁修改的大文本内容而言,会造成显著的存储冗余。
相比之下,增量差分仅记录两次版本之间的变化部分,通常以补丁形式(如JSON Patch或二进制diff)存储。这种模式极大节省了存储资源,适合内容体量大但变动小的场景。但其代价是读取复杂度上升——要还原某一历史版本,必须从初始版本开始逐层应用所有差分包,存在较高的CPU开销和潜在的一致性风险。
| 存储模式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 全量快照 | 查询高效、恢复迅速、实现简单 | 存储成本高、易造成重复数据 | 修改频率低、内容较小、要求快速回滚 |
| 增量差分 | 节省存储空间、适合高频微调 | 回放耗时、一致性维护难 | 内容庞大、变更细粒度、存储敏感型系统 |
| 混合模式 | 平衡空间与性能,定期做基准快照 | 实现复杂、需调度协调 | 高频更新+长期保留需求 |
综合考虑开发成本与运维稳定性,大多数企业级CMS倾向于采用 周期性全量快照 + 近期增量记录 的混合策略。例如每第七次修改生成一次完整快照,中间使用差分记录。这样既降低了总体存储压力,又避免了过长的回放链路。
graph TD
A[原始版本 V0] --> B[差分 Δ1]
B --> C[差分 Δ2]
C --> D[差分 Δ3]
D --> E[全量快照 V4]
E --> F[差分 Δ5]
F --> G[差分 Δ6]
G --> H[全量快照 V7]
上述流程图展示了混合模式的工作机制:每隔若干版本插入一个锚点快照,其余时间仅保存变更集。当用户请求某历史版本时,系统定位最近的前置快照,然后依次应用后续差分直至目标版本。
5.1.2 版本编号体系设计与语义化标识
有效的版本编号有助于提升用户体验与系统可维护性。建议采用语义化版本号(Semantic Versioning),格式为 major.minor.patch :
- major :重大结构调整或内容重写;
- minor :新增段落、图片调整等中等变更;
- patch :错别字修正、标点更改等细微改动。
该编号可通过自动化规则生成,也可由编辑手动指定。后端服务根据变更幅度智能推荐版本层级,减少人为误判。
此外,还应引入唯一版本ID(UUID或自增主键)、创建时间戳、操作人信息等元数据字段,构成完整的版本头信息结构。这些信息可用于后续的审计日志、权限校验及搜索过滤功能。
5.1.3 数据库建模与JPA映射实践
为支持版本控制,需在原有内容表基础上扩展版本关联表。以下是一个典型的内容版本表设计示例:
CREATE TABLE content_version (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
content_id BIGINT NOT NULL COMMENT '所属内容ID',
version_number VARCHAR(20) NOT NULL COMMENT '版本号,如1.0.0',
title TEXT,
body LONGTEXT,
status ENUM('DRAFT', 'PUBLISHED', 'ARCHIVED') DEFAULT 'DRAFT',
author_id BIGINT NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
comment TEXT COMMENT '本次修改说明',
is_snapshot BOOLEAN DEFAULT FALSE COMMENT '是否为基准快照',
INDEX idx_content_id (content_id),
INDEX idx_created_at (created_at),
INDEX idx_author_id (author_id)
);
对应的JPA实体类定义如下:
@Entity
@Table(name = "content_version")
public class ContentVersion {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "content_id", nullable = false)
private Long contentId;
@Column(name = "version_number", length = 20, nullable = false)
private String versionNumber;
@Lob
@Column(name = "title")
private String title;
@Lob
@Column(name = "body")
private String body;
@Enumerated(EnumType.STRING)
@Column(name = "status")
private ContentStatus status;
@Column(name = "author_id", nullable = false)
private Long authorId;
@CreationTimestamp
@Column(name = "created_at")
private LocalDateTime createdAt;
@Column(name = "comment", length = 500)
private String comment;
@Column(name = "is_snapshot")
private Boolean isSnapshot = false;
// Getter and Setter methods...
}
代码逻辑逐行解读:
-
@Entity和@Table注解声明该类为JPA实体,映射到数据库中的content_version表。 -
@Id与@GeneratedValue定义主键自增策略,确保每条版本记录具有唯一标识。 -
contentId字段用于关联原始内容主体,便于按内容维度查询所有版本。 -
versionNumber使用字符串类型以兼容语义化版本格式(如 “2.1.3”)。 -
@Lob标注大对象字段,适用于存储长文本内容(title/body),底层对应TEXT或LONGTEXT类型。 -
ContentStatus枚举通过@Enumerated(EnumType.STRING)映射为可读的状态值,增强调试便利性。 -
@CreationTimestamp是Hibernate提供的便捷注解,自动填充创建时间,无需手动赋值。 -
isSnapshot布尔标志位区分普通版本与基准快照,在恢复逻辑中起到关键作用。
此模型支持高效的版本检索与回滚操作。例如,可通过JPQL查询获取某个内容的所有版本列表:
@Query("SELECT cv FROM ContentVersion cv WHERE cv.contentId = :contentId ORDER BY cv.createdAt DESC")
List<ContentVersion> findVersionsByContentId(@Param("contentId") Long contentId);
配合分页接口,前端可实现“版本历史面板”的懒加载渲染,提升响应速度。
5.2 自动化版本生成与AOP拦截机制
手动提交版本会增加用户负担并容易遗漏,因此理想状态下版本创建应尽可能自动化。借助Spring AOP(面向切面编程),可在不侵入业务逻辑的前提下实现透明的版本捕获机制。
5.2.1 利用@Around切面监控内容更新方法
定义一个环绕通知(Around Advice),监听所有标记了特定注解的方法调用。一旦检测到内容更新行为,则自动保存当前状态为新版本。
首先创建自定义注解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Versioned {
String value() default "";
}
然后编写切面类:
@Aspect
@Component
@Slf4j
public class VersionControlAspect {
@Autowired
private ContentVersionService versionService;
@Around("@annotation(versioned)")
public Object captureVersion(ProceedingJoinPoint joinPoint, Versioned versioned) throws Throwable {
Object[] args = joinPoint.getArgs();
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
// 获取第一个参数作为Content对象(假设)
Object targetContent = args[0];
if (!(targetContent instanceof Content)) {
log.warn("Target object is not a Content instance");
return joinPoint.proceed();
}
Content content = (Content) targetContent;
// 执行原方法前保存旧状态
Content beforeUpdate = new Content();
BeanUtils.copyProperties(content, beforeUpdate); // 浅拷贝
try {
Object result = joinPoint.proceed(); // 执行实际更新逻辑
// 更新成功后生成新版本
ContentVersion version = new ContentVersion();
version.setContentId(content.getId());
version.setTitle(content.getTitle());
version.setBody(content.getBody());
version.setStatus(content.getStatus());
version.setAuthorId(SecurityContextHolder.getContext().getAuthentication().getName()); // 获取当前用户
version.setComment("Auto-saved by AOP interceptor");
version.setIsSnapshot(false); // 可配置策略决定是否设为快照
versionService.save(version);
log.info("Version captured for content ID: {}", content.getId());
return result;
} catch (Exception e) {
log.error("Failed to create version snapshot", e);
throw e;
}
}
}
参数说明与逻辑分析:
-
@Around("@annotation(versioned)"):表示该切面作用于所有带有@Versioned注解的方法。 -
joinPoint.getArgs()获取被拦截方法的参数数组,从中提取待更新的内容对象。 -
BeanUtils.copyProperties()来自Spring框架,用于快速复制对象属性,形成更新前的状态快照。 - 在
proceed()调用前后分别处理“捕获旧状态”与“保存新版本”,确保只有成功更新才生成版本。 -
SecurityContextHolder提取当前登录用户,作为版本作者记录。 - 异常捕获机制防止版本保存失败影响主流程,同时记录错误日志供排查。
使用时只需在服务层更新方法上添加注解:
@Service
public class ContentService {
@Versioned
public Content updateContent(Content content) {
return contentRepository.save(content);
}
}
即可实现无感知的版本记录功能。
5.2.2 版本合并策略与去重机制
连续多次快速编辑可能导致产生大量意义相近的小版本。为此可引入“静默合并”机制:若短时间内(如5分钟内)同一用户连续修改同一内容,则只保留最后一次版本,或将中间版本标记为临时草稿。
实现方式可通过Redis缓存最近一次版本时间戳:
public void saveWithThrottling(Long contentId, Long userId, ContentVersion version) {
String cacheKey = "last_version:" + contentId + ":" + userId;
String lastTimeStr = redisTemplate.opsForValue().get(cacheKey);
if (lastTimeStr != null) {
LocalDateTime lastTime = LocalDateTime.parse(lastTimeStr);
Duration duration = Duration.between(lastTime, LocalDateTime.now());
if (duration.toMinutes() < 5) {
// 时间间隔小于5分钟,执行合并逻辑
versionService.updateLatestAsDraft(contentId); // 将上次版本转为草稿
}
}
versionService.save(version);
redisTemplate.opsForValue().set(cacheKey, LocalDateTime.now().toString(), Duration.ofMinutes(6));
}
该策略有效减少了噪声版本数量,提升了历史记录的清晰度。
5.3 历史版本可视化与回滚功能实现
前端界面是用户接触版本系统的直接入口。一个直观的历史面板不仅能帮助编辑快速定位变更节点,还能提供一键回滚、差异对比等实用功能。
5.3.1 前端版本时间线组件设计(Vue.js)
采用时间轴(Timeline)布局展示版本序列,每个节点显示版本号、修改人、时间及备注信息。点击节点可预览内容或发起回滚。
<template>
<div class="version-timeline">
<el-timeline>
<el-timeline-item
v-for="version in versions"
:key="version.id"
:timestamp="formatDate(version.createdAt)"
:color="version.isSnapshot ? '#409EFF' : '#909399'"
>
<div @click="previewVersion(version)" style="cursor: pointer;">
<strong>Ver {{ version.versionNumber }}</strong>
by {{ version.authorName }}
<span v-if="version.comment">({{ version.comment }})</span>
</div>
<el-button size="mini" @click="rollbackTo(version.id)">恢复</el-button>
</el-timeline-item>
</el-timeline>
</div>
</template>
<script>
export default {
props: ['contentId'],
data() {
return { versions: [] };
},
async mounted() {
const res = await this.$http.get(`/api/version/content/${this.contentId}`);
this.versions = res.data;
},
methods: {
previewVersion(ver) {
this.$emit('preview', ver);
},
async rollbackTo(id) {
await this.$http.post(`/api/version/${id}/rollback`);
this.$message.success('已恢复至该版本');
this.$emit('refresh');
},
formatDate(date) {
return new Date(date).toLocaleString();
}
}
};
</script>
该组件通过调用后端 /api/version/content/{id} 接口获取版本列表,并绑定回滚事件。颜色区分快照与普通版本,增强视觉辨识。
5.3.2 差异对比算法集成(diff-match-patch)
为了让用户清楚看到两次版本间的具体变动,可集成Google开源的 diff-match-patch 库进行文本比对。
import * as dmp from 'diff-match-patch';
const d = new dmp.diff_match_patch();
function diffText(oldText, newText) {
const diffs = d.diff_main(oldText, newText);
d.diff_cleanupSemantic(diffs); // 语义化清理
return d.diff_prettyHtml(diffs);
}
返回结果为包含 <ins> 和 <del> 标签的HTML片段,可在富文本区域中高亮显示增删内容。
结合前后端协作,整个版本控制系统形成了闭环:从自动捕获 → 智能存储 → 高效查询 → 直观呈现 → 安全回滚,全面支撑内容治理需求。
6. 基于Thymeleaf/FreeMarker的模板引擎集成
在现代Java Web开发中,尽管前后端分离架构已成为主流趋势,但在某些特定场景下,如内容展示型网站、后台管理系统的部分静态页面渲染、邮件模板生成或SEO优化需求较高的系统中,服务端模板引擎仍然扮演着不可替代的角色。Spring Boot为开发者提供了对多种模板引擎的良好支持,其中 Thymeleaf 和 FreeMarker 是最为广泛使用的两种技术方案。它们不仅具备强大的动态渲染能力,还能与Spring MVC无缝集成,提升开发效率和维护性。
本章节将深入探讨如何在Spring Boot项目中集成并优化Thymeleaf与FreeMarker两大模板引擎,涵盖配置方式、核心语法、性能调优策略以及实际应用场景对比分析。通过具体代码示例、流程图建模与参数说明,帮助具有5年以上经验的IT从业者掌握其底层机制,并能在复杂业务场景中做出合理选型。
6.1 Thymeleaf模板引擎深度集成与动态渲染实践
Thymeleaf作为一款现代化的服务端Java模板引擎,以其自然模板特性(Natural Templates)著称——即HTML文件可以直接在浏览器中预览而无需启动后端服务。这一特性极大提升了前端协作效率,尤其适用于需要频繁交付静态原型的设计团队。
6.1.1 Thymeleaf核心工作机制与表达式语言解析
Thymeleaf的工作原理建立在DOM树遍历与属性处理器(Attribute Processors)模型之上。当请求到达控制器时,Spring MVC会根据视图名称查找对应的 .html 模板文件,Thymeleaf引擎则通过SAX或DOM方式解析该文件,并识别带有 th:* 命名空间的标签属性,执行相应的逻辑处理。
以下是Thymeleaf常见的表达式类型及其用途:
| 表达式 | 示例 | 说明 |
|---|---|---|
${...} | ${user.name} | 变量表达式,用于访问Model中的数据 |
*{...} | *{title} | 选择表达式,配合 th:object 使用于表单绑定 |
#{...} | #{messages.welcome} | 消息表达式,用于国际化资源读取 |
@{...} | @{/css/style.css} | URL表达式,生成上下文相关的链接 |
~{...} | ~{fragments/header} | 片段表达式,实现模板复用 |
该机制使得Thymeleaf既保持了HTML语义完整性,又实现了动态内容注入的能力。
graph TD
A[HTTP请求] --> B{DispatcherServlet}
B --> C[Controller处理业务逻辑]
C --> D[ModelAndView addObject数据]
D --> E[ViewResolver解析视图名]
E --> F[ThymeleafTemplateEngine加载HTML模板]
F --> G[解析th:*属性并替换动态内容]
G --> H[输出最终HTML响应]
上述流程图清晰展示了从用户请求到页面渲染完成的全过程。值得注意的是,Thymeleaf默认采用缓存机制来提升重复访问的性能,但在开发阶段建议关闭以避免修改模板后无法即时生效。
6.1.2 Spring Boot中Thymeleaf的标准配置与依赖引入
要在Spring Boot项目中启用Thymeleaf,首先需添加必要的Maven依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!-- 若需支持Layout布局 -->
<dependency>
<groupId>nz.net.ultraq.thymeleaf</groupId>
<artifactId>thymeleaf-layout-dialect</artifactId>
</dependency>
随后,在 application.yml 中进行关键配置:
spring:
thymeleaf:
prefix: classpath:/templates/
suffix: .html
mode: HTML
encoding: UTF-8
cache: false # 开发环境关闭缓存
enabled: true
servlet:
content-type: text/html
参数说明:
-
prefix/suffix:定义模板文件路径规则,默认指向src/main/resources/templates。 -
mode:设置文档模式,HTML为标准模式;也可设为XHTML或TEXT。 -
cache:生产环境中应设为true以提升性能,开发阶段建议关闭。 -
content-type:响应头Content-Type字段值,影响浏览器解析行为。
6.1.3 动态模板渲染实战:构建一个新闻详情页
假设我们需要实现一个新闻展示页面,控制器代码如下:
@Controller
public class NewsController {
@Autowired
private NewsService newsService;
@GetMapping("/news/{id}")
public String viewNews(@PathVariable Long id, Model model) {
NewsEntity news = newsService.findById(id);
model.addAttribute("news", news);
model.addAttribute("relatedList", newsService.findRelatedByTag(news.getTags()));
return "news/detail"; // 对应 templates/news/detail.html
}
}
对应模板文件 detail.html 内容示例如下:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8"/>
<title th:text="${news.title}">默认标题</title>
</head>
<body>
<h1 th:text="${news.title}">新闻标题</h1>
<p><small>发布于 <span th:text="${#dates.format(news.publishTime, 'yyyy-MM-dd HH:mm')}"></span></small></p>
<div th:if="${not #strings.isEmpty(news.summary)}" class="summary">
<p th:text="${news.summary}">摘要内容</p>
</div>
<article th:utext="${news.content}">正文内容</article>
<h3>相关推荐:</h3>
<ul th:if="${#lists.size(relatedList)} > 0">
<li th:each="item : ${relatedList}">
<a th:href="@{/news/{id}(id=${item.id})}" th:text="${item.title}">文章标题</a>
</li>
</ul>
</body>
</html>
代码逻辑逐行解读:
-
xmlns:th声明Thymeleaf命名空间,使IDE能提供语法提示。 -
th:text替换元素文本内容,自动转义防止XSS攻击。 -
#dates.format是Thymeleaf内置的时间工具类方法,用于格式化日期。 -
th:if实现条件判断,仅当表达式为真时才渲染节点。 -
th:each提供循环迭代功能,类似于JSTL的c:forEach。 -
th:utext输出未经转义的HTML内容,适用于富文本编辑器输出,但需确保内容安全。 -
@{/news/{id}(id=${item.id})}使用URL表达式生成带参数的路径,支持上下文路径自动拼接。
此结构充分体现了Thymeleaf“HTML即模板”的设计理念,即使脱离服务器也能正常浏览结构。
6.1.4 模板片段复用与布局管理
为了提高组件化程度,Thymeleaf支持通过 th:fragment 定义可重用片段。例如创建通用头部:
<!-- fragments/header.html -->
<div th:fragment="main-header(siteName)">
<header>
<h1 th:text="${siteName}">站点名称</h1>
<nav>
<a href="/">首页</a> |
<a href="/about">关于我们</a>
</nav>
</header>
</div>
在主页面中引用:
<body>
<div th:replace="fragments/header :: main-header('我的新闻站')"></div>
<!-- 主体内容 -->
</body>
结合 th:insert 、 th:replace 、 th:include 三种指令,可灵活控制片段插入方式。
此外,借助 thymeleaf-layout-dialect 插件,可实现母版页布局:
<!-- layouts/main.html -->
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout">
<head>
<title layout:title-pattern="$CONTENT_TITLE - $LAYOUT_TITLE">默认标题</title>
</head>
<body>
<header th:replace="fragments/header :: default"></header>
<section layout:fragment="content">内容区域</section>
<footer th:replace="fragments/footer :: default"></footer>
</body>
</html>
子页面继承:
<!-- news/list.html -->
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorator="layouts/main">
<div layout:fragment="content">
<h2>新闻列表</h2>
<!-- 列表渲染 -->
</div>
</html>
这种布局机制极大简化了多页面风格统一的实现成本。
6.2 FreeMarker模板引擎高级应用与性能调优
相较于Thymeleaf,FreeMarker更偏向传统模板引擎设计,使用纯文本模板( .ftl )并通过FTL(FreeMarker Template Language)语法进行变量替换与逻辑控制。它不依赖HTML结构,因此更适合生成XML、JSON、邮件、配置文件等非HTML输出场景。
6.2.1 FreeMarker工作模型与模板加载机制
FreeMarker的核心是 Configuration 对象,负责管理模板加载器(TemplateLoader)、缓存策略、全局变量等。每次请求时,引擎从指定目录加载 .ftl 文件并编译成内部表示形式,再与传入的数据模型合并生成最终输出。
典型集成步骤包括:
- 添加Maven依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
- 配置
application.yml:
spring:
freemarker:
template-loader-path: classpath:/templates/fm/
suffix: .ftl
content-type: text/html
cache: true
charset: UTF-8
request-context-attribute: rc # 在模板中可通过rc访问HttpServletRequest
- 控制器返回视图名:
@GetMapping("/report")
public String generateReport(Model model) {
model.addAttribute("data", reportService.generateDailyReport());
return "report/daily"; // 映射到 /templates/fm/report/daily.ftl
}
6.2.2 FTL语法详解与常用指令实践
FreeMarker使用 ${} 进行变量插值, <#> 开头的标签实现控制结构。以下是一个典型的报表模板示例:
<!DOCTYPE html>
<html>
<head><title>日报统计</title></head>
<body>
<h1>每日运营报告 - ${data.date?string("yyyy年MM月dd日")}</h1>
<#if data.items?has_content>
<table border="1">
<tr><th>指标</th><th>数值</th></tr>
<#list data.items as item>
<tr>
<td>${item.name}</td>
<td align="right">${item.value?string(",.2f")}</td>
</tr>
</#list>
</table>
<#else>
<p><em>暂无数据。</em></p>
</#else>
<p>生成时间:<#setting time_format="HH:mm:ss"/> ${.now?string("yyyy-MM-dd HH:mm:ss")}</p>
</body>
</html>
关键语法说明:
-
${...}:变量输出,支持内建函数如?string格式化数字或日期。 -
<#if>/<#else>:条件分支控制。 -
<#list>:循环遍历集合。 -
?has_content:判断序列是否非空。 -
?string(",.2f"):使用千分位与两位小数格式显示浮点数。 -
.now:预定义变量,代表当前时间。
FreeMarker提供了丰富的内建函数库,涵盖字符串处理、日期格式化、数学运算、序列操作等,极大增强了模板灵活性。
6.2.3 自定义宏(Macro)与模板组件化设计
宏是FreeMarker中实现代码复用的重要手段,类似于函数定义:
<#-- 定义分页控件宏 -->
<#macro pagination currentPage totalPages baseUrl>
<div class="pagination">
<#if currentPage > 1>
<a href="${baseUrl}?page=${currentPage - 1}">上一页</a>
</#if>
<#list 1..totalPages as p>
<a href="${baseUrl}?page=${p}" <#if p == currentPage>class="active"</#if>>${p}</a>
</#list>
<#if currentPage < totalPages>
<a href="${baseUrl}?page=${currentPage + 1}">下一页</a>
</#if>
</div>
</#macro>
<#-- 调用宏 -->
<@pagination currentPage=3 totalPages=10 baseUrl="/articles" />
宏支持参数传递、嵌套调用甚至嵌入HTML块,可用于构建复杂的UI组件库。
6.2.4 性能优化与缓存策略配置
FreeMarker默认开启模板缓存( template_update_delay ),可在生产环境中显著减少I/O开销。建议配置如下:
spring:
freemarker:
cache: true
template-update-delay: 60000 # 每60秒检查一次模板更新
settings:
template_exception_handler: rethrow # 异常直接抛出便于调试
log_template_exceptions: true
同时,可通过自定义 TemplateLoader 扩展模板来源,例如从数据库或远程存储加载:
@Configuration
public class FreeMarkerConfig {
@Bean
public freemarker.template.Configuration freemarkerConfiguration() {
freemarker.template.Configuration config = new freemarker.template.Configuration(freemarker.template.Configuration.VERSION_2_3_31);
config.setTemplateLoader(new DatabaseTemplateLoader()); // 自定义加载器
config.setDefaultEncoding("UTF-8");
config.setTemplateExceptionHandler(TemplateExceptionHandler.RETHROW_HANDLER);
config.setLogTemplateExceptions(false);
return config;
}
}
此机制适用于需要动态更新模板内容而不重启应用的场景,如营销活动页面定制。
6.3 Thymeleaf与FreeMarker选型对比与最佳实践建议
面对两种主流模板引擎,开发者应在不同业务背景下做出理性选择。
| 维度 | Thymeleaf | FreeMarker |
|---|---|---|
| 模板格式 | HTML原生兼容,可预览 | 独立 .ftl 文件,不可直接预览 |
| 学习曲线 | 较低,接近HTML语法 | 中等,需熟悉FTL语法 |
| 国际化支持 | 内建良好 | 需手动整合MessageSource |
| 缓存性能 | 中等,依赖Spring整合 | 高,原生高效缓存机制 |
| 多格式输出 | 主要HTML | 支持HTML/XML/JSON/文本等 |
| 社区活跃度 | 高,Spring官方推荐 | 稳定但更新缓慢 |
| 典型应用场景 | 后台管理系统、内容展示页 | 邮件模板、报表生成、API文档 |
推荐使用场景总结:
-
优先选用Thymeleaf :
当项目以HTML页面为主,强调前后端协同开发、SEO友好或需快速原型验证时,Thymeleaf因其“自然模板”优势成为首选。 -
优先选用FreeMarker :
当涉及大量非HTML内容生成(如PDF、邮件、脚本)、追求极致性能或已有历史系统迁移时,FreeMarker更为合适。
此外,两者并非互斥。在大型系统中,完全可以共存使用:Thymeleaf负责前端展示,FreeMarker专用于异步任务中的邮件通知生成。
6.4 模板安全与防注入攻击策略
模板引擎若使用不当,可能引发安全风险,尤其是当允许用户输入影响模板内容时。
6.4.1 XSS防护机制
Thymeleaf默认对 th:text 进行HTML转义,有效防止XSS攻击。但使用 th:utext 时必须确保内容经过净化处理:
@Service
public class ContentService {
private final HtmlSanitizer sanitizer = new HtmlSanitizer();
public String sanitizeHtml(String unsafeHtml) {
return sanitizer.sanitize(unsafeHtml); // 使用OWASP Java HTML Sanitizer
}
}
避免将用户提交的富文本未经校验直接输出。
6.4.2 FreeMarker表达式沙箱限制
FreeMarker允许执行复杂表达式,存在潜在RCE(远程代码执行)风险。应禁用危险指令:
configuration.setNewBuiltinClassResolver(className -> {
if (className.startsWith("java.lang.Runtime") ||
className.startsWith("javax.script")) {
throw new TemplateException("Forbidden class access: " + className, null);
}
return ClassTemplateLoader.DEFAULT_RESOLVER.resolve(className);
});
同时设置安全白名单策略,限制可调用的方法与属性。
综上所述,Thymeleaf与FreeMarker各有千秋,合理选型并结合安全规范,方能在企业级应用中发挥最大价值。
7. 页面静态化与前端渲染优化技术(Vue.js/HTML5)
7.1 页面静态化的意义与适用场景分析
在高并发访问的Web系统中,动态内容频繁查询数据库、执行模板渲染等操作会显著增加服务器负载。页面静态化是一种将动态内容预先生成为静态HTML文件的技术手段,能够有效降低后端压力,提升响应速度和用户体验。
静态化适用于以下典型场景:
- 内容更新频率较低但访问量高的页面(如新闻详情页、产品介绍页)
- SEO需求强烈的公开页面
- 活动营销页或公告页
- 需要快速加载的移动端H5页面
从性能角度看,静态页面可直接由Nginx等Web服务器返回,无需经过Spring Boot应用容器处理请求、执行业务逻辑、访问数据库等完整流程,响应时间通常可控制在毫秒级。
| 场景类型 | 更新频率 | 访问量 | 是否适合静态化 |
|---|---|---|---|
| 新闻首页 | 高 | 极高 | 是(定时刷新) |
| 用户个人中心 | 实时 | 中等 | 否 |
| 商品详情页 | 低 | 高 | 是 |
| 管理后台 | 实时 | 低 | 否 |
| 活动专题页 | 一次性 | 极高 | 是 |
| 搜索结果页 | 实时 | 高 | 否 |
| 博客文章页 | 低 | 高 | 是 |
| 购物车页面 | 实时 | 中等 | 否 |
| 关于我们 | 极低 | 低 | 是 |
| 登录注册页 | 不变 | 高 | 是 |
| 数据仪表盘 | 实时 | 中等 | 否 |
| 帮助中心文档 | 低 | 高 | 是 |
通过上述表格可见,内容型CMS系统中有超过60%的展示类页面适合采用静态化策略。
7.2 基于Vue.js的前后端分离架构下的静态化实现
在现代前端框架主导的应用中,可以结合Vue.js的构建工具链实现预渲染(Prerendering),即在构建阶段生成静态HTML快照。
使用 prerender-spa-plugin 插件可在Webpack打包过程中自动访问指定路由并保存其渲染结果:
// vue.config.js
const PrerenderSPAPlugin = require('prerender-spa-plugin');
const Renderer = PrerenderSPAPlugin.PuppeteerRenderer;
module.exports = {
configureWebpack: config => {
if (process.env.NODE_ENV === 'production') {
return {
plugins: [
new PrerenderSPAPlugin({
staticDir: path.join(__dirname, 'dist'),
routes: ['/','/about','/news','/products'],
renderer: new Renderer({
inject: {},
headless: false,
renderAfterDocumentEvent: 'render-event'
})
})
]
}
}
}
}
参数说明:
- staticDir : 指定构建输出目录
- routes : 需要预渲染的路由列表
- renderAfterDocumentEvent : 触发渲染完成的自定义事件,在Vue mounted钩子中触发
在 main.js 中添加事件触发逻辑:
new Vue({
router,
store,
mounted() {
document.dispatchEvent(new Event('render-event'));
},
render: h => h(App)
}).$mount('#app');
该方案的优势在于保留了SPA的交互能力,同时具备静态页面的首屏加载优势。部署时只需将生成的HTML文件配合Nginx配置即可实现CDN加速分发。
7.3 动态内容的增量静态化与缓存更新机制
对于无法完全静态化的动态内容(如包含用户个性化信息的页面),可采用“静态主干 + 动态补丁”模式。核心思路是:主体结构静态化,局部数据通过Ajax异步加载。
<!-- article-123.html -->
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8" />
<title>深入理解Java虚拟机</title>
<!-- 静态元信息 -->
</head>
<body>
<div id="content">
<h1>深入理解Java虚拟机</h1>
<p>本文详细解析JVM内存模型...</p>
<!-- 大段静态内容 -->
</div>
<!-- 动态区域占位符 -->
<div id="dynamic-stats">
<span class="views">阅读数:<span id="view-count">--</span></span>
<span class="likes">点赞数:<span id="like-count">--</span></span>
</div>
<!-- 异步加载脚本 -->
<script>
fetch('/api/content/stats/123')
.then(res => res.json())
.then(data => {
document.getElementById('view-count').textContent = data.views;
document.getElementById('like-count').textContent = data.likes;
});
</script>
</body>
</html>
配合Redis实现热度统计与自动重生成机制:
@Service
public class StaticPageService {
@Autowired
private RedisTemplate<String, Integer> redisTemplate;
@Value("${page.static.ttl:86400}")
private long ttl; // 默认一天
public void recordView(Long contentId) {
String key = "content:views:" + contentId;
redisTemplate.opsForValue().increment(key);
// 当访问次数达到阈值时触发重新静态化
if (redisTemplate.opsForValue().get(key) % 1000 == 0) {
generateStaticPage(contentId);
}
}
public void scheduleRegeneration() {
// 定时任务每日凌晨重建过期页面
List<Long> expiredContents = contentRepository.findUpdatedSince(
LocalDateTime.now().minusDays(1));
expiredContents.forEach(this::generateStaticPage);
}
}
7.4 HTML5离线存储与PWA支持提升前端性能
利用HTML5 Application Cache和Service Worker技术,可实现离线访问与资源缓存,进一步优化前端体验。
// register-sw.js
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker.register('/sw.js')
.then(registration => {
console.log('SW registered: ', registration);
})
.catch(registrationError => {
console.log('SW registration failed: ', registrationError);
});
});
}
Service Worker脚本(sw.js)实现缓存策略:
const CACHE_NAME = 'cms-v1';
const urlsToCache = [
'/',
'/css/main.css',
'/js/app.js',
'/images/logo.png'
];
self.addEventListener('install', event => {
event.waitUntil(
caches.open(CACHE_NAME)
.then(cache => cache.addAll(urlsToCache))
);
});
self.addEventListener('fetch', event => {
event.respondWith(
caches.match(event.request)
.then(response => {
return response || fetch(event.request);
})
);
});
结合manifest.json启用PWA功能:
{
"name": "My CMS",
"short_name": "CMS",
"start_url": "/",
"display": "standalone",
"background_color": "#ffffff",
"theme_color": "#000000",
"icons": [{
"src": "icon-192.png",
"sizes": "192x192",
"type": "image/png"
}]
}
7.5 静态资源优化与加载性能监控
通过Webpack进行代码分割与懒加载:
// router/index.js
const routes = [
{
path: '/news',
component: () => import('@/views/NewsList.vue')
},
{
path: '/about',
component: () => import('@/views/About.vue')
}
];
使用Lighthouse进行性能审计,并集成Performance API收集真实用户指标:
// performance-monitor.js
function sendMetrics() {
if ('performance' in window) {
const perfData = performance.getEntriesByType('navigation')[0];
const metrics = {
dns: perfData.domainLookupEnd - perfData.domainLookupStart,
tcp: perfData.connectEnd - perfData.connectStart,
ttfb: perfData.responseStart - perfData.requestStart,
dom: perfData.domContentLoadedEventEnd - perfData.fetchStart,
load: perfData.loadEventEnd - perfData.fetchStart
};
navigator.sendBeacon('/api/perf', JSON.stringify(metrics));
}
}
window.addEventListener('load', sendMetrics);
mermaid格式流程图展示静态化发布流程:
graph TD
A[内容发布] --> B{是否需静态化?}
B -->|是| C[调用静态化服务]
B -->|否| D[标记为动态页面]
C --> E[渲染Vue组件为HTML]
E --> F[写入Nginx静态目录]
F --> G[推送至CDN节点]
G --> H[更新Redis缓存版本号]
H --> I[通知搜索引擎抓取]
D --> J[正常走API接口]
简介:在数字化时代,内容管理系统(CMS)成为企业和个人管理与发布数字内容的核心工具。本项目基于SpringBoot框架构建,充分利用其“约定优于配置”、自动装配和嵌入式服务器等特性,实现一个高可用、易扩展的CMS系统。系统涵盖用户权限控制、内容增删改查、分类标签管理、版本控制、多语言支持及搜索功能,并集成Thymeleaf模板引擎、Redis缓存、Elasticsearch搜索和RESTful API等现代技术。通过本项目实战,开发者可掌握SpringBoot在真实场景中的应用,理解前后端分离架构设计,提升企业级应用开发能力。

















 1845
1845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









