






我们知道在高安全模式下,在主服务器上提交的事务必须同时在镜像服务器上提交成功,否则该事务无法在主数据库上提交。
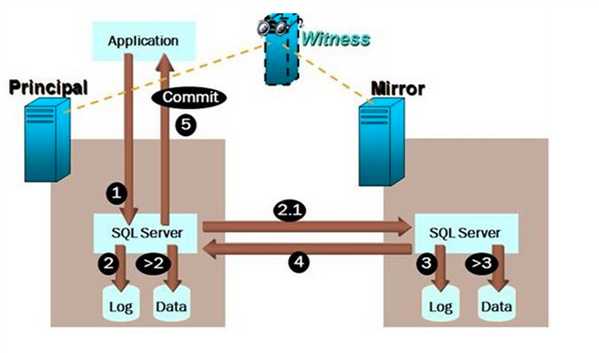
在上面的图中,一个事务在主数据库上提交的步骤包含:
客户端程序将事务发送给主数据库服务器SQLServer
主数据库服务器 SQL Server为这个事务写日志文件
2.1 主数据库服务器将这个事务的日志内容传递给镜像服务器的SQL Server
镜像数据库服务器SQL Server将收到的日志内容写入到日志文件。
镜像服务器回复主服务器写日志的动作完成。
主服务器SQL Server回复客户端程序该事务提交成功。
>2.主数据库服务器SQL Server在检查点时将该事务修改的数据页从内存中写入数据文件。
>3.镜像数据库服务器SQL Server将日志对于的数据页在文件上做变更。
从这样的顺序中,我们提出一个问题,如果镜像服务器的SQL Server在那个时候不能完成步骤3,是否这时主数据库服务器对于的数据库就不能正常的提交事务了呢?本文介绍的两个测试就是模拟日志文件和数据库不可用时候的测试结果
测试一:数据库有多个数据文件和日志文件,分布在不同的磁盘上,在镜像数据库联机的情况下删除一个磁盘,即一个数据文件和日志文件不可能的测试:
1.创建数据库test,添加四个文件。注意为第一个日志文件设置较小的大小并禁止自动增长:
test C:\Program Files\Microsoft SQL Server\MSSQL.2\MSSQL\DATA\test.mdf
test_log C:\Program Files\Microsoft SQL Server\MSSQL.2\MSSQL\DATA\test_log.ldf
test1 E:\test1.ndf
testlog1 E:\testlog1.ldf
2.配置数据库镜像高安全模式,主服务器为SQL1,镜像数据库为SQL2.
3.创建两张测试表test和test1,插入超过1,000,000行数据到test表中.由于第一个日志文件较小且不能自动增长,因此SQL Server开始使用第二个日志文件testlog1.检查数据库镜像的状态:
结果:主数据库显示已principal/sychronized
4.执行下面的脚本,开始事务,这个事务会执行超过10分钟:
begin tran
insert into test select * from test
insert into test select * from test
commit
当事务开始执行1分钟以后,暂停数据库镜像1分钟,然后在手工恢复数据库镜像的同步:
结果: 主数据库状态显示principal/synchronizing.
访问test1表,可以返回数据。
6.手工将E盘从镜像数据库服务上拔出:.
结果: 主数据库状态立即变更为 (principal/suspend)。
测试访问主数据库并查询test1表
镜像数据库状态变更为: (mirrored, suspend/restoring)
7.检查事务的执行:
几分钟以后,这个事务显示在主数据库上提交成功。
.
8.检查主数据库和镜像数据库的SQL Server错误日志:
主数据库:
Error: 1453, Severity: 16, State: 1.
‘TCP://LDUA2481460-2.DOM248146.COM:5023‘, the remote mirroring partner for database ‘test‘, encountered error 5159, status 1, severity 24. Database mirroring has been suspended. Resolve the error on the remote server and resume mirroring, or remove mirroring and re-establish the mirror server instance.
镜像数据库:
‘TCP://LDUA2481460-2.DOM248146.COM:5023‘, the remote mirroring partner for database ‘test‘, encountered error 5159, status 1, severity 24. Database mirroring has been suspended. Resolve the error on the remote server and resume mirroring, or remove mirroring and re-establish the mirror server instance.
Operating system error 2(The system cannot find the file specified.) on file "E:\test_3.ldf" during RestoreFileHdr.
Test 2:在执行并同步一个大事务的时候将镜像数据库删除:
1. 创建数据库test,包含一个数据文件一个日志文件。
test1 E:\test1.mdf
test1_log E:\test1_log.ldf
2.配置数据库镜像高安全模式,主服务器为SQL1,镜像数据库为SQL2.
3.创建两张测试表test和test1,插入超过1,000,000行数据到test表中.由于第一个日志文件较小且不能自动增长,因此SQL Server开始使用第二个日志文件testlog1.检查数据库镜像的状态:
结果:主数据库显示已principal/sychronized
4.执行下面的脚本,开始事务,这个事务会执行超过10分钟:
begin tran
insert into test select * from test
insert into test select * from test
commit
5.当事务开始执行1分钟以后,暂停数据库镜像1分钟,然后在手工恢复数据库镜像的同步:
结果: 主数据库状态显示principal/synchronizing.
访问test1表,可以返回数据。
6.手工将E盘从镜像数据库服务上拔出:
结果: 主数据库状态立即变更为 (principal/ disconnected)。
测试访问主数据库并查询test1表
镜像数据库不存在。
7.检查事务的执行:
几分钟以后,这个事务显示在主数据库上提交成功。
8.检查主数据库和镜像数据库的SQL Server错误日志:
主数据库:
1453, Severity: 16, State: 1
‘TCP://LDUA2481460-2.DOM248146.COM:5023‘, the remote mirroring partner for database ‘test1‘, encountered error 5149, status 1, severity 16. Database mirroring has been suspended. Resolve the error on the remote server and resume mirroring, or remove mirroring and re-establish the mirror server instance..
镜像数据库:
Error: 17053 Severity: 16 State: 1
RestoreFileHdr: Operating system error 2(The system cannot find the file specified.) encountered.
Error: 5159 Severity: 24 State: 1
Operating system error 2(The system cannot find the file specified.) on file "E:\test1_1.ldf" during RestoreFileHdr.
Error: 823 Severity: 24 State: 3.
The operating system returned error 21(The device is not ready.) to SQL Server during a write at offset 0x00000000012000 in file ‘E:\test1.mdf‘. Additional messages in the SQL Server error log and system event log may provide more detail. This is a severe system-level error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information see SQL Server Books Online.
Error: 1454 Severity: 16 State: 1.
While acting as a mirroring partner for database ‘test1‘ server instance ‘LDUA2481460-1\MSSQLSERVER1‘ encountered error 823 status 3 severity 24. Database mirroring will be suspended. Try to resolve the error and resume mirroring.
测试结果:
主数据库在这两种情况下依然可以访问并且成功提交事务
转自:http://blogs.msdn.com/b/apgcdsd/archive/2012/03/09/10280123.aspx

















 4071
4071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









