






 该博客介绍了实时用户行为处理系统的设计,采用Storm确保数据至少一次(atleastonce)的处理策略,以减少数据丢失。为解决异常数据处理和数据积压,系统采用双队列和补偿重试策略。在高可用性方面,系统通过全栈集群化、异常模块降级处理以及数据一致性保障措施,确保服务在DB和Redis故障时仍能运行,且在故障恢复后能保持数据最终一致性。
该博客介绍了实时用户行为处理系统的设计,采用Storm确保数据至少一次(atleastonce)的处理策略,以减少数据丢失。为解决异常数据处理和数据积压,系统采用双队列和补偿重试策略。在高可用性方面,系统通过全栈集群化、异常模块降级处理以及数据一致性保障措施,确保服务在DB和Redis故障时仍能运行,且在故障恢复后能保持数据最终一致性。
对消息的处理storm支持多种数据保证策略,at least once,at most once,exactly once。对实时用户行为来说,首先是保证数据尽可能少丢失,另外要支持包括重试和降级的多种数据处理策略,并不能发挥exactly once的优势,反而会因为事务支持降低性能,所以实时用户行为系统采用的at least once的策略。java 调用失败重试2次这种策略下消息可能会重发,所以程序处理实现了幂等支持。
storm的发布比较简单,上传更新程序jar包并重启任务即可完成一次发布,遗憾的是没有多版本灰度发布的支持。
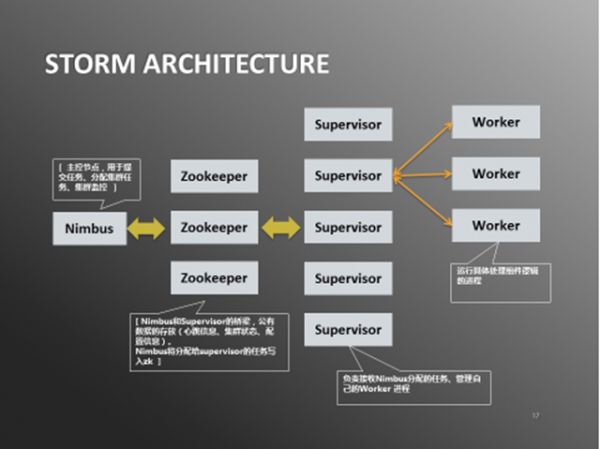
图3:Storm架构
在部分情况下数据处理需要重试,比如连接超时,或者无法连接。连接超时可能马上重试就能恢复,但是无法连接一般需要更长时间等待网络或的恢复,这种情况下处理程序不能一直等待,否则会造成数据延迟。实时用户行为系统采用了双队列的设计来解决这个问题。java 调用失败重试2次
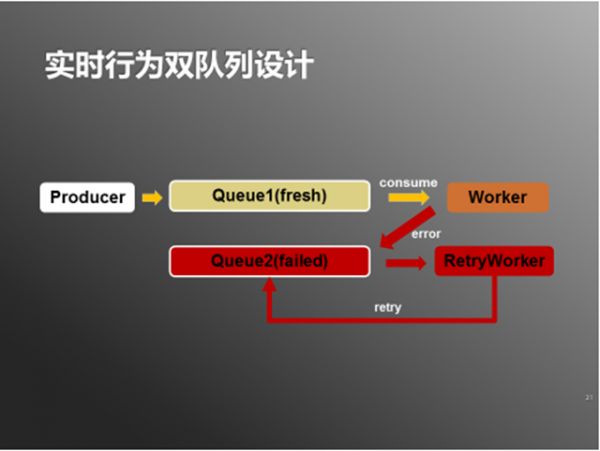
图4:双队列设计
生产者将行为纪录写入Queue1(主要保持数据新鲜),Worker从Queue1消费新鲜数据。如果发生上述异常数据,则Worker将异常数据写入Queue2(主要保持异常数据)。
这样Worker对Queue1的消费进度不会被异常数据影响,可以保持消费新鲜数据。RetryWorker会Queue2,消费异常数据,如果处理还没有成功,则按照一定的策略(如下图)等待或者重新将异常数据写入Queue2。
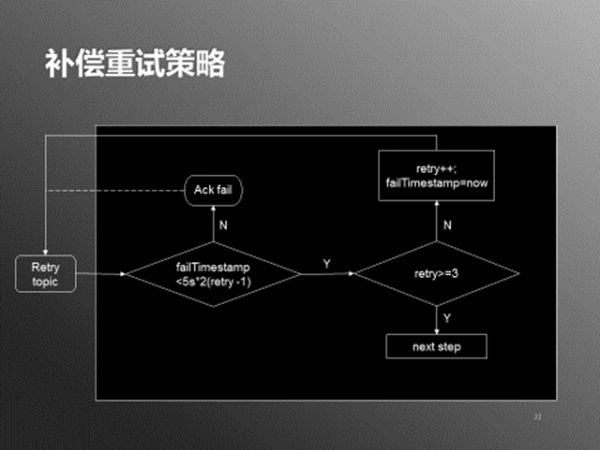
图5:补偿重试策略
另外,数据发生积压的情况下,可以调整Worker的消费游标,从最新的数据重新开始消费,保证最新数据得到处理。中间未经处理的一段数据则启动backupWorker,指定起止游标,在消费完指定区间的数据之后,backupWorker会自动停止。(如下图)
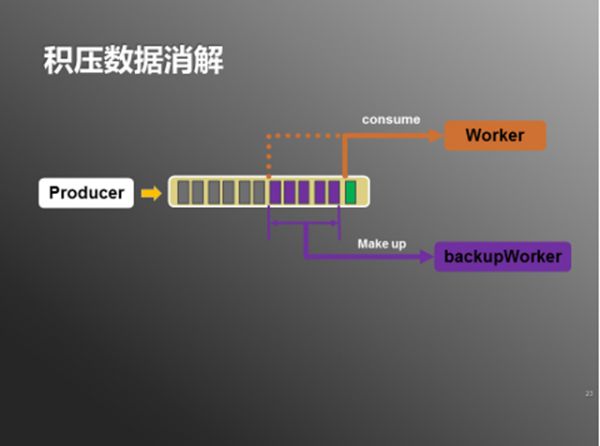
图6:积压数据消解
三、可用性
作为基础服务,对可用性的要求比一般的服务要高得多,因为下游依赖的服务多,一旦出现故障,有可能会引起级联反应影响大量业务。项目从设计上对以下问题做了处理,保障系统的可用性:
系统是否有单点? DB扩容/维护/故障怎么办? Redis维护/升级补丁怎么办? 服务万一挂了如何快速恢复?如何尽量不影响下游应用?
首先是系统层面上做了全栈集群化。kafka和storm本身比较成熟地支持集群化运维;web服务支持了无状态处理并且通过负载均衡实现集群化;Redis和DB方面携程已经支持主备部署,使用过程中如果主机发生故障,备机会自动接管服务;通过全栈集群化保障系统没有单点。
另外系统在部分模块不可用时通过降级处理保障整个系统的可用性。先看看正常数据处理流程:(如下图)
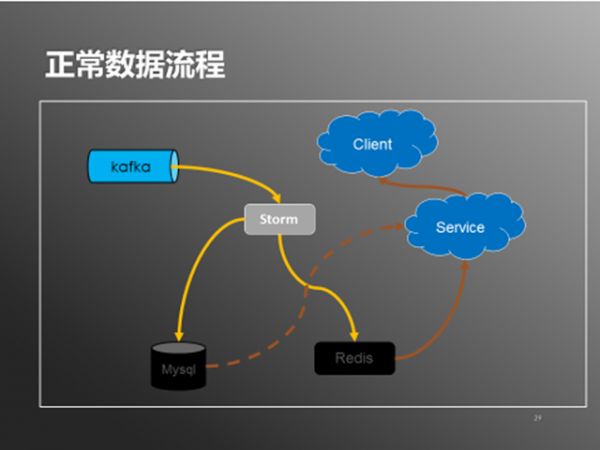
图7:正常数据流程
在系统正常状态下,storm会从kafka中读取数据,分别写入到redis和mysql中。服务从redis拉取(取不到时从db补偿),输出给客户端。DB降级的情况下,数据流程也随之改变(如下图)

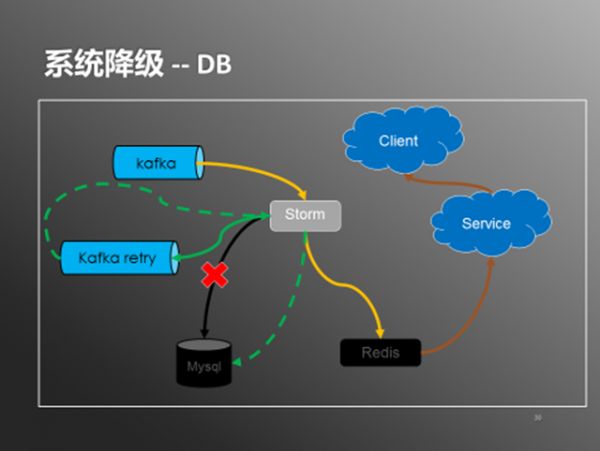
图8:系统降级-DB
当mysql不可用时,通过打开db降级开关,storm会正常写入redis,但不再往mysql写入数据。数据进入reids就可以被查询服务使用,提供给客户端。另外storm会把数据写入一份到kafka的retry队列,在mysql正常服务之后,通过关闭db降级开关,storm会消费retry队列中的数据,从而把数据写入到mysql中。redis和mysql的数据在降级期间会有不一致,但系统恢复正常之后会通过retry保证数据最终的一致性。redis的降级处理也类似(如下图)
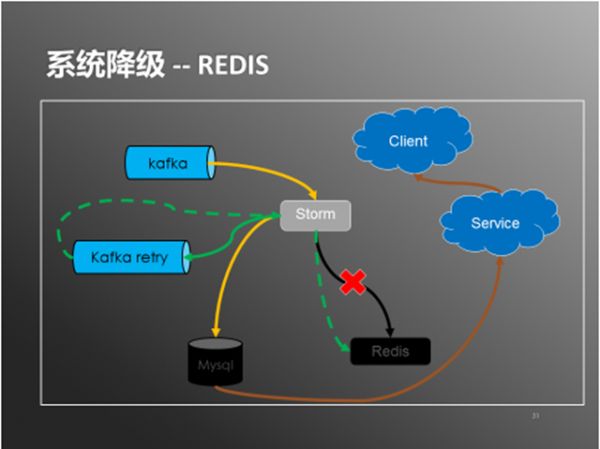
图9:系统降级-Redis
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-59884-2.html

















 1663
1663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









