





 本文探讨了单词嵌入和单词袋模型在推荐系统中的差异,重点关注它们如何影响信息处理和结果准确性。
本文探讨了单词嵌入和单词袋模型在推荐系统中的差异,重点关注它们如何影响信息处理和结果准确性。
单词嵌入
词嵌入始终是最佳选择吗? (Are word embeddings always the best choice?)
If you can challenge a well-accepted view in data science with data, that’s pretty cool, right? After all, “in data we trust”, or so we profess! Word embeddings have caused a revolution in the world of natural language processing, as a result of which we are much closer to understanding the meaning and context of text and transcribed speech today. It is a world apart from the good old bag-of-words (BoW) models, which rely on frequencies of words under the unrealistic assumption that each word occurs independently of all others. The results have been nothing short of spectacular with word embeddings, which create a vector for every word. One of the oft used success stories of word embeddings involves subtracting the man vector from the king vector and adding the woman vector, which returns the queen vector:
如果您可以用数据挑战数据科学界公认的观点,那很酷,对吗? 毕竟,“我们相信数据”,或者说我们自称! 词嵌入已在自然语言处理领域引起了一场革命,其结果是,我们现在更加接近于理解文本和转录语音的含义和上下文。 这是一个与旧的单词袋(BoW)模型不同的世界,该模型在不切实际的假设(每个单词独立于所有其他单词)的情况下依赖单词的频率。 单词嵌入的结果是惊人的,为每个单词创建一个向量。 单词嵌入的常用成功案例之一涉及从国王向量中减去男人向量,并添加女人向量,这将返回女王向量:
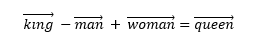
Very smart indeed! However, I raise the question whether word embeddings should always be preferred to bag-of-words. In building a review-based recommender system, it dawned on me that while word embeddings are incredible, they may not be the most suitable technique for my purpose. As crazy as it may sound, I got better results with the BoW approach. In this article, I show that the uber-smart feature of word embeddings in being able to understand related words actually turns out to be a shortcoming in making better product recommendations.
确实很聪明! 但是,我提出一个问题,即单词嵌入是否应始终比单词袋更受青睐。 在建立基于审阅的推荐系统时,我突然意识到,尽管词嵌入令人难以置信,但它们可能不是我所希望的最合适的技术。 尽管听起来很疯狂,但BoW方法使我获得了更好的结果。 在本文中,我证明了单词嵌入的超级智能功能,因为它能够理解相关的单词,实际上在提出更好的产品推荐方面是一个缺点。
单词嵌入 (Word embeddings in a jiffy)
Simply stated, word embeddings consider each word in its context; for example, in the word2vec approach, a popular technique developed by Tomas Mikolov and colleagues at Google, for each word, we generate a vector of words with a large number of dimensions. Using neural networks, the vectors are created by predicting for each word what its neighboring words may be. Multiple Python libraries like spaCy and gensim have built-in word vectors; so, while word embeddings have been criticized in the past on grounds of complexity, we don’t have to write the code from scratch. Unless you want to dig into the math of one-hot-encoding, neural nets and complex stuff, using word vectors today is as simple as using BoW. After all, you don’t need to know the theory of internal combustion engines to drive a car!
简而言之,词嵌入考虑了每个词的上下文; 例如,在word2vec方法中,这是由Tomas Mikolov和Google的同事开发的一种流行技术,对于每个单词,我们都会生成具有大量维的单词向量。 使用神经网络,通过为每个单词预测其相邻单词可能是什么来创建向量。 诸如spaCy和gensim之类的多个Python库具有内置的字向量。 因此,尽管过去以复杂性为由批评词嵌入,但我们不必从头开始编写代码。 除非您想深入研究一键编码,神经网络和复杂事物的数学原理,否则今天使用单词向量就像使用BoW一样简单。 毕竟,您无需了解驾驶汽车的内燃机原理!
退一步说的话(BoW) (Throwback to the bag-of-words (BoW))
In the BoW models, similarity between two documents using either cosine or Jaccard similarity literally checks which or how many words are exactly the same across two documents. To appreciate how much smarter the word embeddings approach is, let me use an example shared by user srce code on stackoverflow.com. Consider two sentences: (i) “How can I help end violence in the world?” (ii) “What should we do to bring global peace?” Let us see how word vectors versus BoW based cosine similarity treat these two sentences.
在BoW模型中,使用余弦或Jaccard相似度的两个文档之间的相似度从字面上检查两个文档中哪个或多少个单词完全相同。 为了了解单词嵌入方法有多精明 ,让我使用stackoverflow.com上用户srce代码共享的示例。 考虑两个句子:(i)“我如何帮助结束世界上的暴力行为?” (ii)“我们应该怎么做才能实现全球和平?” 让我们看看单词向量与基于BoW的余弦相似度如何处理这两个句子。
#code to calculate spaCy and BoW similarity scores from two texts
import spacy
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd#spaCy uses word vectors for medium (md) and large (lg)
nlp = spacy.load('en_core_web_md')
text1 = 'How can I help end violence in the world?'
text2 = 'What should we do to bring global peace?'#Calculates spaCy similarity between texts 1 and 2
doc1 = nlp(text1)
doc2 = nlp(text2)
print("spaCy similarity:", doc1.similarity(doc2))#Calculate cosine similarity using Bag-of-Words
documents =[text1, text2]
count_vectorizer = CountVectorizer(stop_words='english')
sparse_matrix = count_vectorizer.fit_transform(documents)
doc_term_matrix = sparse_matrix.todense()
df = pd.DataFrame(doc_term_matrix, columns=count_vectorizer.get_feature_names(), index=['x', 'y'])
print("Cosine similarity:", cosine_similarity(df, df)[0,1])With its word vectors, spaCy assigns a similarity of 91% to these two sentences, while the BoW cosine similarity score, not surprisingly, turns out to be 0 (since the two sentences do not share a single word). In most applications, the word vector approach will probably win hands down.
通过其单词向量,spaCy为这两个句子分配了91%的相似度,而BoW余弦相似度分数毫不奇怪地变为0(因为这两个句子不共享一个单词)。 在大多数应用中,词向量方法可能会赢得人们的青睐。
But not all may be well in paradise, and “Houston, we (may) have a problem.” Let us consider a pair of hi-fi speakers or headphones, and focus on two short reviews: (i) “These speakers have an excellent soundstage.” (ii) “These speakers boast outstanding imaging.” The spaCy model gives a similarity score of 86% between these two reviews, while BoW cosine similarity returns a value of 29%. The spaCy similarity score is very high because people often mention the features soundstage and imaging in close proximity of each other; however, these features mean very different things. Obviously, the ability to distinguish between soundstage and imaging in user or expert reviews will be critical in a building a recommender system for high-end speakers or headphones. So what is considered a strength of word embeddings may turn out to be a shortcoming in this context. Now onto the recommender system that I built for running shoes, and how and why I got better results with BoW.
但是,并非所有人都在天堂里生活得很好,“休斯顿,我们(可能)有问题。” 让我们考虑一对高保真扬声器或耳机,重点关注两个简短的评论:(i)“这些扬声器具有出色的音场。” (ii)“这些扬声器拥有出色的影像效果。” spaCy模型在这两个评论之间给出的相似度得分为86%,而BoW余弦相似度返回的值为29%。 空间相似度得分非常高,因为人们经常提到声场和影像之间非常接近的特征。 但是,这些功能意味着截然不同的事情。 显然,在构建用于高端扬声器或耳机的推荐系统时,区分用户或专家评论中的声场和影像的能力至关重要。 因此,在这种情况下,单词嵌入的强度可能会成为缺点。 现在介绍我为跑鞋构建的推荐系统,以及如何以及为什么在BoW上获得更好的结果。

使用单词嵌入与BoW的推荐系统 (A recommender system using word embeddings vs BoW)
My system takes features of a pair of running shoes (e.g., cushion, comfort, durability, support, etc.) as inputs from a user, and matches those preferred features to products using lots of customer reviews. I naturally started with spaCy for obtaining similarity scores between the features a shopper wants in running shoes and the product reviews I scraped from the Amazon website. After all, with spaCy, I could avoid having to change different parts of speech of a feature word into its noun form (e.g., replace comfortably or comfortable by comfort) or replace synonyms of a feature word (e.g., replace indestructible with durability). SpaCy would be smart enough to figure these things out on its own! With a given set of features, I calculate the similarity score for each review, and then the average similarity for every product. The three products with highest average similarity scores are shown below with three preferred features: cushion, comfort and durability (while I also use feature-level sentiment analysis to provide recommendations, it is not relevant in this discussion):
我的系统将一双跑鞋的功能(例如, 缓冲垫 , 舒适性 , 耐用性,支撑性等)作为用户的输入,并通过大量的客户评论将这些首选功能与产品进行匹配。 我自然是从spaCy开始的,目的是获得购物者想要的跑鞋功能与我从亚马逊网站上刮取的产品评论之间的相似度分数。 毕竟,借助spaCy,我可以避免将特征词的不同词性更改为名词形式(例如,舒适地替换为舒适 ),或替换特征词的同义词(例如,替换为不可破坏的耐久性 )。 SpaCy足够聪明,可以自行解决这些问题! 使用给定的功能集,我计算每个评论的相似性得分,然后计算每个产品的平均相似性。 下面显示了具有最高平均相似性评分的三种产品,它们具有三个优选特征: 缓冲 , 舒适性和耐用性 (尽管我也使用特征级别的情感分析来提供建议,但在本讨论中不相关):
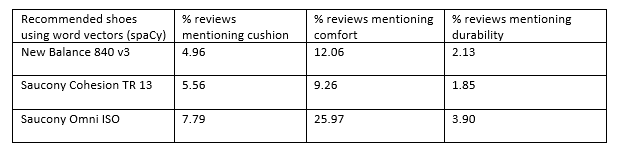
For the top three matching scores in Table 1, you will note that some of the product features were mentioned only in a small percentage of reviews (columns 2, 3, and 4). That’s not good, for if only 2–6% of reviews of a product mention a feature that a shopper considers important, I wouldn’t feel comfortable recommending that product to him/her. Curiously enough, when I used the plain vanilla BoW cosine similarity, I did not face this problem (Table 2).
对于表1中的前三项匹配得分,您会注意到,只有少数评论(第2、3和4列)提到了某些产品功能。 这不是很好,因为如果只有2–6%的产品评论提到购物者认为重要的功能,那么我就不愿意向他/她推荐该产品。 奇怪的是,当我使用普通的BoW余弦相似度时,我没有遇到这个问题(表2)。
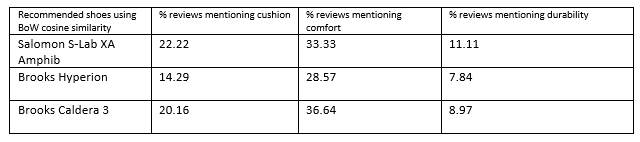
Because it looks for an exact match of words, BoW does not consider product feature words like cushion and comfort as similar or related, and produces a significantly lower similarity score if one of these features is missing in a review. But given that the word vectors approach considers cushion and comfort to be related, it barely increases the similarity score for reviews that mention both features over those that discuss only one. To check out my hunch further, I made up two reviews, one mentioning cushion and durability, and the other cushion, comfort and durability (Table 3).
由于BoW会寻找单词的完全匹配项,因此BoW不会将诸如坐垫和舒适性之类的产品功能词视为相似或相关,并且如果评论中缺少这些功能之一,则相似度得分会大大降低。 但是考虑到词向量方法认为缓冲性和舒适性是相关的,因此与仅讨论两个特征的评论相比,对于提及两个特征的评论,其勉强提高了相似度。 为了进一步了解我的直觉,我进行了两项评论,其中一项提到缓冲和耐用性 ,另一项提到缓冲 , 舒适性和耐用性 (表3)。
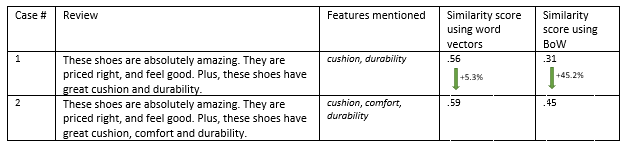
Indeed, I get a much bigger increase of 45% in the similarity score with the BoW approach when the feature comfort is also mentioned, while the corresponding increase with spaCy word vectors is a not-so-impressive 5.3%.
确实,当还提到特征舒适度时,与BoW方法相比,我在相似性分数上获得了更大的提高,达到了45%,而spaCy单词向量的相应提高却不那么令人印象深刻,为5.3%。
Would the problem I encountered with word embeddings go away if I created my own word vectors just from shoe reviews? Not really, for just as one may write regarding a sofa set: “The firm cushion is comfortable for my back,” a cross country runner, for whom cushion and comfort are two different features of shoes, may write: “These shoes have excellent cushion and comfort.” When word vectors are created with our own data, cushion and comfort will still come across being close to each other, and we will continue to face the same challenge.
如果仅根据鞋评创建自己的单词向量,我遇到的单词嵌入问题就会消失吗? 并非如此,就像一个关于沙发套件的人可能写的那样:“坚固的坐垫对我的后背很舒适,”越野跑者说到:“ 坐垫和舒适性是鞋子的两个不同特征”:缓冲和舒适。” 当使用我们自己的数据创建单词向量时,彼此之间仍然会感到 缓冲和舒适 ,而我们将继续面临同样的挑战。

最后的想法 (Final Thoughts)
Word embeddings have done wonders, bringing much needed semantics and context to words, which were just treated as frequency counts without any sequence or meaning in the BoW models. However, the example of recommender systems I provided suggests that we should not automatically assume that the newer methods will perform better in every application. Especially in settings where two or more words, which have distinct meanings, are likely to be mentioned close to each other, word embeddings may fail to adequately distinguish between them. In applications where such distinctions matter, the results are likely to be unsatisfactory, as I found out the hard way. The current state-of-the-art in word embeddings appears to be ill-equipped to handle the situation I described above.
词嵌入已经创造了奇迹,为词带来了很多需要的语义和上下文,这些词在BoW模型中被当作频率计数而没有任何序列或含义。 但是,我提供的推荐系统示例表明,我们不应该自动假定较新的方法在每个应用程序中都会表现更好。 尤其是在两个或两个以上具有不同含义的单词可能彼此靠近的情况下,单词嵌入可能无法充分区分它们。 如我所知,在这种区分很重要的应用程序中,结果很可能无法令人满意。 当前在词嵌入方面的最新技术似乎不足以应对我上面描述的情况。
单词嵌入

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









