



 DeepR是一款Python库,专为在Tensorflow上构建复杂管道而设计,结合了易用性、性能和面向生产的特性。适用于推荐引擎的构建,支持大规模数据处理和模型训练,同时解决了配置、日志记录、代码灵活性等问题。
DeepR是一款Python库,专为在Tensorflow上构建复杂管道而设计,结合了易用性、性能和面向生产的特性。适用于推荐引擎的构建,支持大规模数据处理和模型训练,同时解决了配置、日志记录、代码灵活性等问题。
Authors Guillaume Genthial, Romain Beaumont, Denis Kuzin, Amine Benhalloum
作家 Guillaume Genthial , Romain Beaumont , Denis Kuzin , Amine Benhalloum
Links Github, Docs, Quickstart, MovieLens Example
链接 Github , 文档 , 快速入门 , MovieLens示例
介绍 (Introduction)
At Criteo we build recommendation engines. We make millions of recommendations every second with milliseconds latencies from billions of products.
在Criteo,我们构建推荐引擎。 我们每秒从数十亿种产品中提出数百万个建议,而毫秒级的延迟 。
While scalability and speed are hard requirements, we also need to optimize for multiple, often changing, criteria: Maximize the number of sales, clicks, etc. Concretely, this translates into dozens of models trained every day, quickly evolving with new losses, architectures, and approaches.
虽然扩展性和速度是硬性要求,但我们还需要针对多个(经常更改)的标准进行优化:最大化销售,点击次数等。具体而言,这转化为每天训练的数十种模型,随着新的损失和体系结构快速发展和方法。
DeepR is a Python library to build complex pipelines as easily as possible on top of Tensorflow. It combines ease-of-use with performance and production-oriented capabilities.
DeepR是一个Python库,用于在Tensorflow上尽可能轻松地构建复杂的管道。 它结合了易于使用,性能和面向生产的功能。
At Criteo, we use DeepR to define multi-step training pipelines, preprocess data, design custom models and losses, submit jobs to remote clusters, integrate with logging platforms such as MLFlow and Graphite, and prepare graphs for Ahead-Of-Time XLA compilation and inference.
在Criteo,我们使用DeepR定义多步训练管道 ,预处理数据,设计自定义模型和损失,将作业提交到远程集群,与MLFlow和Graphite等日志记录平台集成,并准备图形以进行提前XLA编译和推论。
DeepR和TensorFlow (DeepR and TensorFlow)
TensorFlow provides great production-oriented capabilities, thanks to (in part) the ability to translate graphs defined in Python into self-contained protobufs that can be reloaded by other services with more efficient backends. More importantly, this alleviates the need to rely on Python for serving and simplifies model deployment.
TensorFlow提供了出色的面向生产的功能,这在一定程度上要归功于能够将Python中定义的图形转换为自包含的protobuf ,这些protobuf可以由具有更高效率后端的其他服务重新加载。 更重要的是,这减轻了依赖Python服务的需求,并简化了模型部署 。
The switch to eager execution with TF2 opens new possibilities in terms of control flow. However, the static graph approach taken by TF1 and the Estimator API has some advantages in terms of serving capabilities and distributed training support. For legacy and maturity reasons, we chose to work with TF1 for now, waiting for TF2 to stabilize.
切换到急切执行TF2,在控制流程方面开辟了新的可能性。 但是,TF1和Estimator API所采用的静态图方法在服务能力和分布式培训支持方面具有一些优势。 出于遗留和成熟的原因,我们选择暂时使用TF1,以等待TF2稳定下来。
While pure Deep Learning libraries like TensorFlow, PyTorch, Jax, etc. typically focus on defining computational graphs, providing (relatively) low-level tools, DeepR is a collection of higher-level functionality to help with both the model definition and everything that goes around it.
虽然像TensorFlow,PyTorch,Jax等纯粹的深度学习库通常专注于定义计算图 ,提供(相对)低级工具,但DeepR是高级功能的集合,可帮助模型定义和所有后续工作周围。
Main pain-points are usually around job scheduling, configuration, logging, code flexibility and reuse rather than new layers implementation. As we keep adding more and more models, we want them to coexist into one consistent codebase, limiting backwards compatibility issues.
主要的痛点通常是围绕作业 调度 , 配置 , 日志记录 , 代码 灵活性和重用,而不是新的层实现。 随着我们不断添加越来越多的模型,我们希望它们共存于一个一致的代码库中,从而限制了向后兼容性问题。
DeepR的优势是什么? (What are DeepR strengths?)
DeepR comes with a config system built for Machine Learning. One of the biggest problems DeepR addresses is configuration, a major challenge in machine learning codebases, as parameters of any function may have to be exposed as hyper-parameters.
DeepR随附针对机器学习而构建的配置系统。 DeepR解决的最大问题之一是配置,这是机器学习代码库中的主要挑战,因为任何函数的参数可能都必须公开为超参数。
When a parameter is far down the call stack, it can be particularly tricky and cause all sorts of issues. Defaults might be difficult to change for example.
当参数远远超出调用堆栈时,它可能会特别棘手,并会引起各种问题。 例如,默认值可能很难更改。
More importantly, it impacts how jobs are launched, and it is not uncommon to end up with long commands with hundreds of parameters, half of them not even being used but kept for backward compatibility.
更重要的是,它影响作业的启动方式,并以带有数百个参数的长命令结束并不罕见,其中一半甚至没有使用,而是为了向后兼容而保留。
DeepR comes with a config system, most similar to Thinc / Gin-config, that makes it possible to configure arbitrarily nested trees of objects, interfacing nicely with json.
DeepR带有一个配置系统,最类似于Thinc / Gin-config ,它可以配置任意嵌套的对象树,并与json很好地接口。
The config system, combined with Python-fire, results in a flexible and powerful Command Line Interface at no additional cost. This lets us submit jobs on a remote cluster, as sending a config file along with a command is usually the easiest way to interact with a job scheduler.
配置系统与Python-fire结合使用,可产生灵活而强大的命令行界面 ,而无需支付额外费用。 这使我们可以在远程群集上提交作业,因为发送配置文件和命令通常是与作业计划程序进行交互的最简单方法。
In other words, we allow the code to stay the same by moving “breaking” changes to the configs. Also, by being able to define the object’s dependencies at the config level, we do not need “assemblers” and other dependency injection mechanisms in the code, simplifying the overall design and maintainability. Finally, because parsing .json files is straightforward, we can reload and update a config programmatically, which is something we need to do for hyper-params search or scheduling.
换句话说,我们通过将“ breaking”更改移到configs来使代码保持不变。 另外,通过能够在配置级别定义对象的依赖关系,我们在代码中不需要“汇编程序”和其他依赖关系注入机制,从而简化了总体设计和可维护性。 最后,由于解析.json文件非常简单,因此我们可以以编程方式重新加载和更新配置 ,这是超参数搜索或调度所需要执行的操作。
DeepR鼓励您撰写工作 (DeepR encourages you to write jobs)
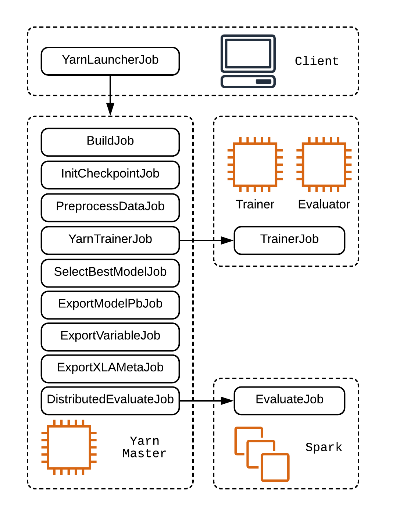
Another problem that DeepR addresses is pipelining.
DeepR解决的另一个问题是流水线。
Training a model is just another ETL, where the input usually is a dataset and the output a protobuf with the model’s graph and weights.
训练模型只是另一个ETL ,其中输入通常是数据集,输出通常是带有模型图形和权重的protobuf 。
Calling model.train()is merely one of the multiple steps. In general, we need to preprocess the data, initialize checkpoints, select the best model, compute predictions, export the model in different formats, etc.
调用model.train()只是多个步骤之一。 通常,我们需要预处理数据,初始化检查点,选择最佳模型,计算预测,以不同格式导出模型等。
DeepR adopts an approach similar to Spark with the Job abstraction that while being flexible, encourages modular logic and code reuse.
DeepR采用类似于Spark的Job抽象方法,该方法既灵活又鼓励模块化逻辑和代码重用 。
DeepR adopts an approach similar to Spark with the Job abstraction that while being flexible, encourages modular logic and code reuse.
DeepR采用与Job抽象类似的Spark方法,该方法既灵活又鼓励模块化逻辑和代码重用 。
As a bonus, jobs can be run on different machines with different hardware requirements: preprocessing probably needs a machine with a good IO, while training would be faster on a GPU.
另外,可以在具有不同硬件要求的不同计算机上运行作业:预处理可能需要一台具有良好IO的计算机,而在GPU上进行培训会更快。
And it’s worth the effort: we were able to reduce our memory footprint by 4 and speedup training by 2, not only saving cost on the infra side but also lifting limitations that existed because of memory.
这值得付出努力: 我们能够将内存占用减少4倍,将培训速度提高2倍 ,不仅节省了基础方面的成本,而且还消除了由于内存而存在的限制。
DeepR可与Hadoop(HDFS,Yarn),MlFlow和Graphite一起使用 (DeepR works with Hadoop (HDFS, Yarn), MlFlow and Graphite)
One of DeepR’s strengths is its tight integration with Hadoop, especially HDFS and Yarn, thanks in part to
DeepR的优势之一是其与Hadoop的紧密集成,尤其是HDFS和Yarn,这部分要归功于
tf-yarn (a library to train Estimators on yarn, also created at Criteo)
tf-yarn (用于在纱线上训练估算器的库,也是在Criteo创建的)
pex (a library to generate Python executables)
pex (用于生成Python可执行文件的库)
pyarrow (Apache Arrow binding)
pyarrow (Apache Arrow绑定)
In practice, this means that there is no additional development time to train a model locally or on a Yarn cluster.
实际上,这意味着没有额外的开发时间来在本地或在Yarn集群上训练模型。
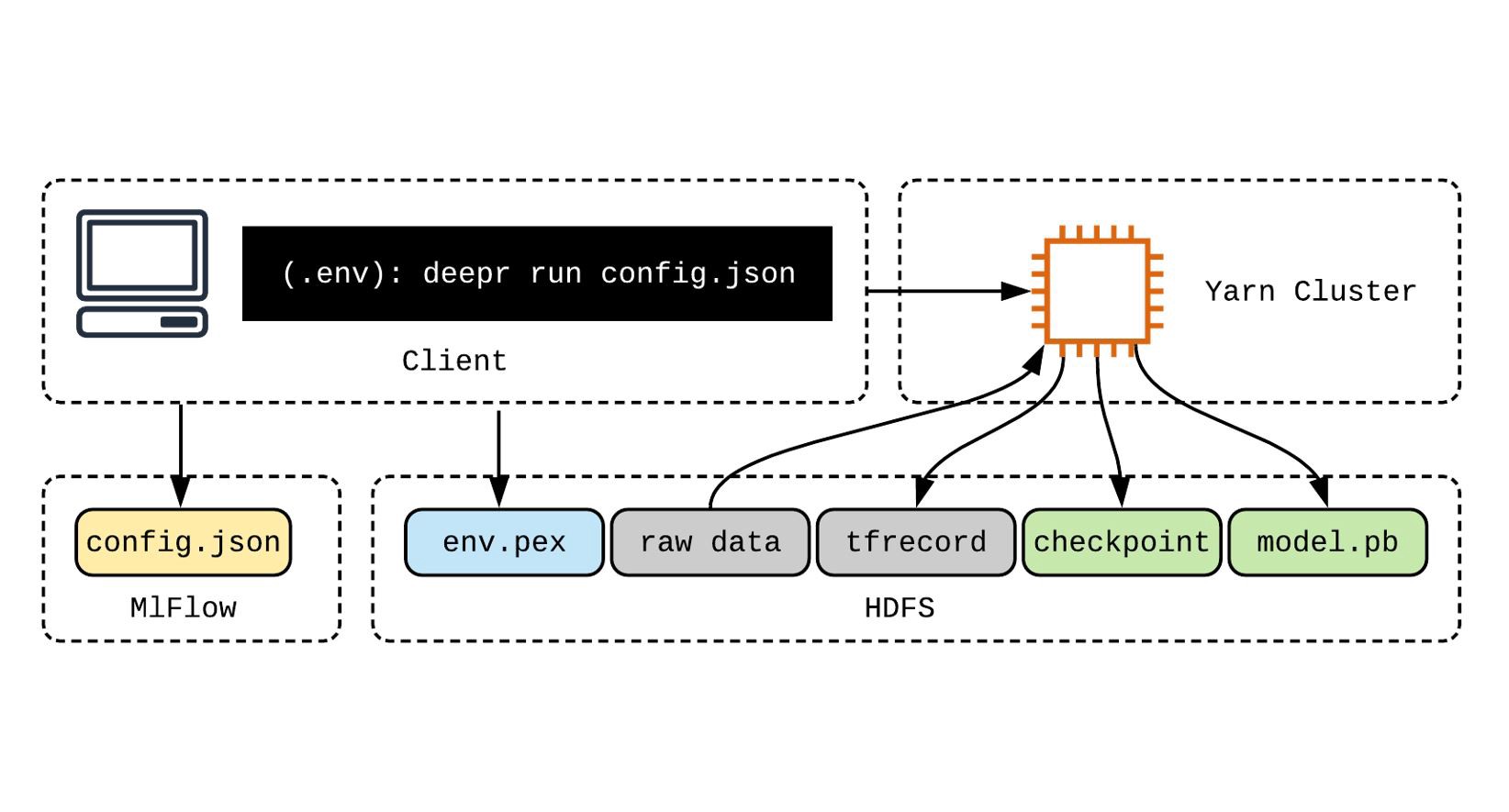
DeepR also provides a suite of tools to use MLFlow for logging metrics and parameters, with support for distributed training and job scheduling on remote clusters.
DeepR还提供了一套工具来使用MLFlow记录指标和参数,并支持远程集群上的分布式培训和作业计划。
Add the ability to save config files as artifacts, and now we have full-reproducibility, an easy way to track and compare experiments as well as a centralized place for all config files, ready for deployment!
添加将配置文件保存为工件的功能,现在,我们具有完全可重复性 ,这是一种简单的方法来跟踪和比较实验,还为所有配置文件提供了一个集中的位置,可供部署!
DeepR还可以帮助估计器进行模型定义 (DeepR can also help with models definition for Estimators)
DeepR also adopts a functional approach to model and layers definition, similar to TRAX, Thinc, or the Keras functional API.
DeepR还采用功能性方法来建模和定义图层,类似于TRAX , Thinc或Keras 功能性API 。
While TensorFlow and PyTorch provide a low-level declarative approach to graph definition, the Estimator API around which DeepR is built works better with functional programming (especially true with TF1 variable management), and we found it easier to manipulate higher-level logic blocks (layers) as functions, chaining them in Directed Acyclic Graphs.
尽管TensorFlow和PyTorch提供了一种低级的声明式方法来定义图形,但构建DeepR的Estimator API可以更好地与函数式编程(尤其是TF1变量管理)兼容,并且我们发现更容易操作高级逻辑块(层)作为函数 ,将它们链接到有向非循环图 。
In that way, the
Layerabstraction provided by DeepR can be seen as a simple way to define graphs for the Estimator API. However, note that it provides this capability as a bonus, since the rest of the code base makes no assumption on how graphs are created.这样,DeepR提供的“
Layer抽象”可以看作是为Estimator API定义图形的简单方法。 但是,请注意,它提供了此功能作为奖励,因为其余的代码库均未假设如何创建图形。
DeepR附带了一套用于操作TF对象的工具 (DeepR comes with a suite of tools to manipulate TF objects)
Finally, DeepR comes with some custom hooks, readers, predictors, jobs, preprocessors, etc. that bundle TensorFlow code. It is very similar to the legacy tf.contrib module, as a collection of missing higher-level tools to manipulate native types.
最后,DeepR附带了一些捆绑了TensorFlow代码的自定义挂钩 , 阅读器 , 预测变量,作业,预处理器等。 它与遗留的tf.contrib模块非常相似,只是缺少了一些用于处理本机类型的高级工具。
开始吧 (Get started)
You can use DeepR as a simple Python library, reusing only a subset of the concepts or build your extension as a standalone Python package that depends on deepr. DeepR includes a few pre-made layers and preprocessors, as well as jobs to train models on yarn.
您可以将DeepR用作简单的Python库 ,仅重用概念的一部分,也可以将扩展构建为依赖于deepr的独立Python包。 DeepR包括一些预制层和预处理器,以及在纱线上训练模型的工作。
For a short introduction on DeepR, have a look at the quickstart (on Colab).
对于DeepR的简短介绍,请查看快速入门 (在Colab上)。
The submodule examples of deepr illustrates what packages built on top of DeepR would look like. It defines custom jobs, layers, preprocessors, macros as well as configs. Once your custom components are packaged in a library, you can easily run any pipeline, locally or on Yarn with
deepr的子模块示例说明了构建在DeepR之上的软件包的外观。 它定义了自定义作业,层,预处理器,宏以及配置。 将自定义组件打包到库中后,您可以轻松地在本地或在Yarn上运行任何管道
deepr run config.json macros.json关于Criteo的推荐系统的信息 (A word about recommender systems at Criteo)
Some of our recommendation systems adopt the following approach. Given a timeline of items represented as vectors, a model predicts another vector meant to capture the user’s interests in the same space. Recommendations are the nearest neighbors of that user’s embedding.
我们的某些推荐系统采用以下方法。 给定以矢量表示的项目的时间轴,模型会预测另一个矢量,该矢量旨在捕捉用户在相同空间中的兴趣。 建议是该用户嵌入的最近邻居 。
At training time, the model contains a lot of parameters: one embedding for each item as well as model parameters.
在训练时,模型包含许多参数:每个项目都嵌入一个参数以及模型参数。
At inference time, we cannot reasonably imagine scoring a user embedding against all possible products. Using fast neighbor search algorithms like HNSW we delegate the ranking step to another service. The model only predicts the user embedding.
在推论时, 我们无法合理地想象对所有可能产品进行嵌入的用户得分 。 使用HNSW之类的快速邻居搜索算法,我们将排名步骤委托给另一项服务。 该模型仅预测用户嵌入。
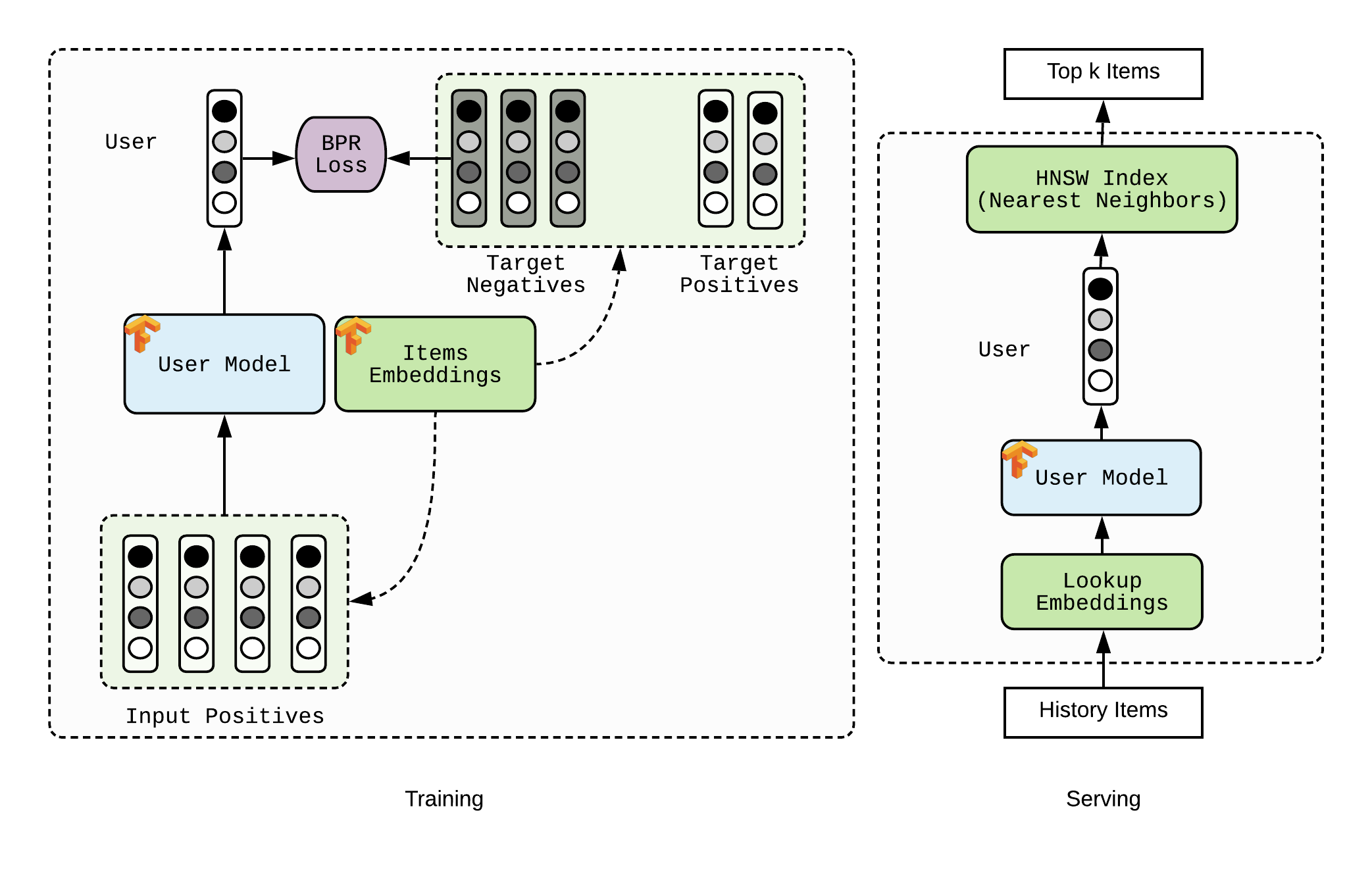
This use-case illustrates how much more complex real-life machine learning pipelines are. Not only do we need to define a graph and train the model, but we also have to support a different behavior at inference time, export some of the variables to other services (in this example, the items embeddings), etc.
该用例说明了现实生活中的机器学习管道要复杂得多。 我们不仅需要定义图并训练模型,而且还必须在推理时支持不同的行为 ,将一些变量导出到其他服务(在此示例中为项目嵌入),等等。
Such a formulation has the advantage of transparency, as you can easily retrieve similar products with nearest neighbors search. In this example, you can see that picking a very specific product from a Criteo partner (board games) returns very similar products in another partner completely, compared to other more standard approaches (Best Ofs, etc.)
这样的表述具有透明性的优势,因为您可以通过最近邻居搜索轻松检索相似的产品。 在此示例中,您可以看到,与其他更标准的方法(Best Ofs等)相比,从Criteo合作伙伴(棋盘游戏)中挑选非常特定的产品可以完全在另一个合作伙伴中返回非常相似的产品。

在MovieLens数据集上使用DeepR (Using DeepR on the MovieLens dataset)
MovieLens is a standard dataset for recommendation tasks. It consists of movie ratings, anonymously aggregated by users. For a given user with some viewing history, the goal is to make the best movie recommendations.
MovieLens是推荐任务的标准数据集。 它包含电影分级,由用户匿名汇总。 对于具有一定观看历史记录的给定用户,目标是提出最佳的电影推荐 。
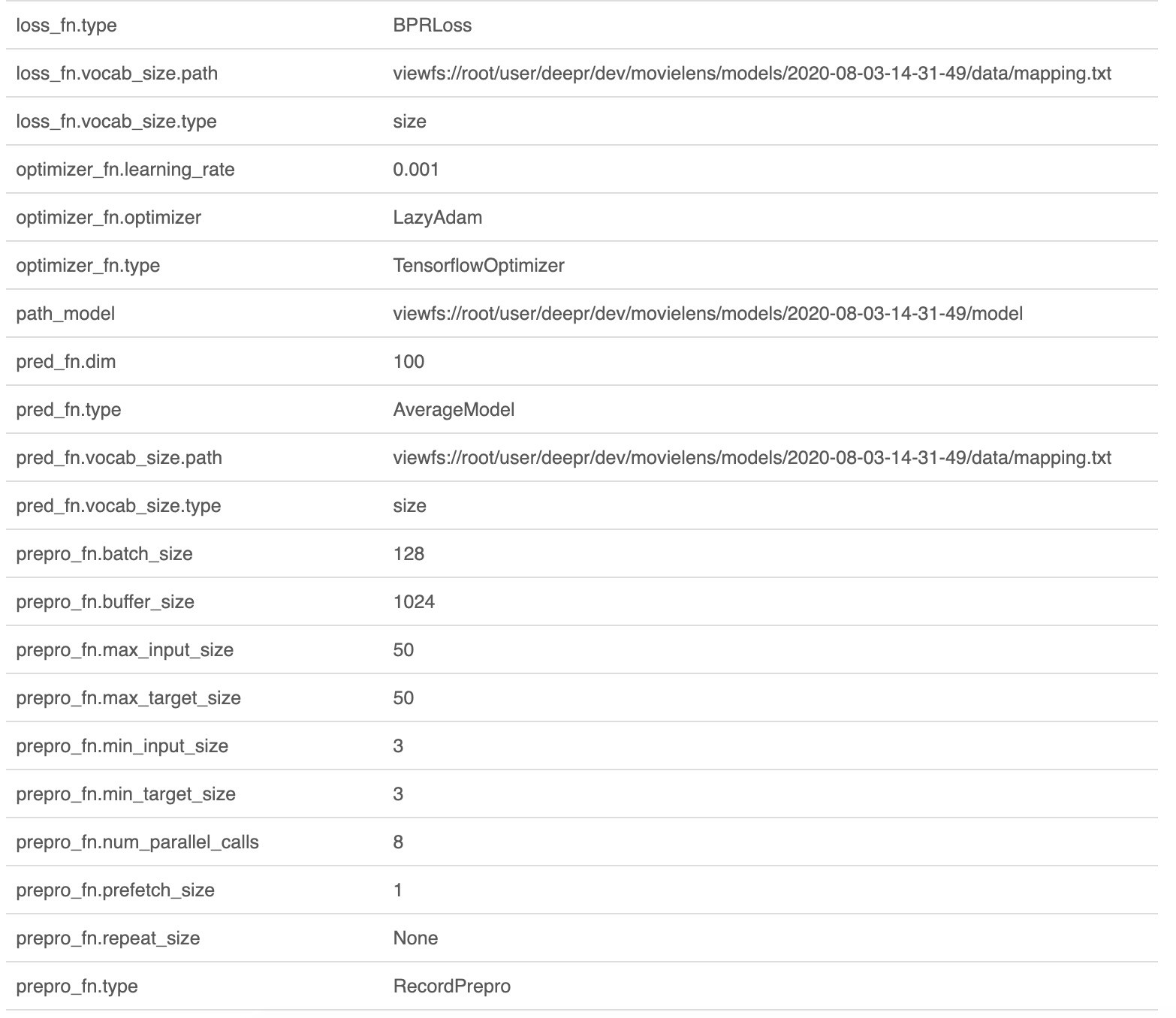
We implement a simple baseline. Each movie is associated with an embedding and a bias. Given a user, a representation is computed as the average of the embeddings of movies seen in the past. The score of any recommendable movie is the inner product of the user embedding with the movie’s embedding + the movie’s bias.
我们实现了一个简单的基准 。 每部电影都与嵌入和偏差相关联。 给定用户,表示形式将作为过去看过的电影嵌入的平均值进行计算。 任何推荐电影的得分都是用户嵌入的内积与电影的嵌入量+电影的偏见。
During training, we train the embeddings and the biases, optimizing a BPR loss that encourages “good” recommendations to get better scores than “bad” recommendations.
在训练期间,我们训练嵌入和偏差,优化BPR损失 ,鼓励“好”建议获得比“差”建议更好的分数。
It is also possible to use fancier models, like a Transformer, but we found it to be relatively unstable to train and not necessarily worth the effort from a production perspective.
也可以使用更高级的模型,例如Transformer ,但是我们发现它的训练相对不稳定,从生产的角度来看不一定值得付出努力。
You can have a look at the AverageModel as well as the corresponding BPRLoss implementations on Github, or train your model using either the config files or the Notebook on Google Colab.
您可以在Github上查看A verageModel以及相应的BPRLoss实现,或者使用config文件或Google Colab上的Notebook训练模型。
The pipeline is made of 4 steps
管道由4个步骤组成
Step 1: Given the MovieLens
ratings.csvfile, createtfrecordsfor the training, evaluation, and test sets.第1步:考虑到MovieLens
ratings.csv文件,创建tfrecords的培训,评估和测试集。Step 2: Train an
AverageModel(optionally, use tf-yarn to distribute training and evaluation on a cluster) and export the embeddings as well as the graph.步骤2:训练
AverageModel(可选,使用tf-yarn在群集上分配训练和评估),并导出嵌入以及图形。Step 3: Write predictions, i.e. for all the test timelines, compute the user representation.
步骤3:编写预测,即针对所有测试时间线,计算用户表示。
Step 4: Evaluate predictions, i.e. look how similar the recommendations provided by the model are to the actual movies seen by the user in the “future”
步骤4:评估预测,即查看模型提供的建议与用户在“未来”中看到的实际电影的相似程度
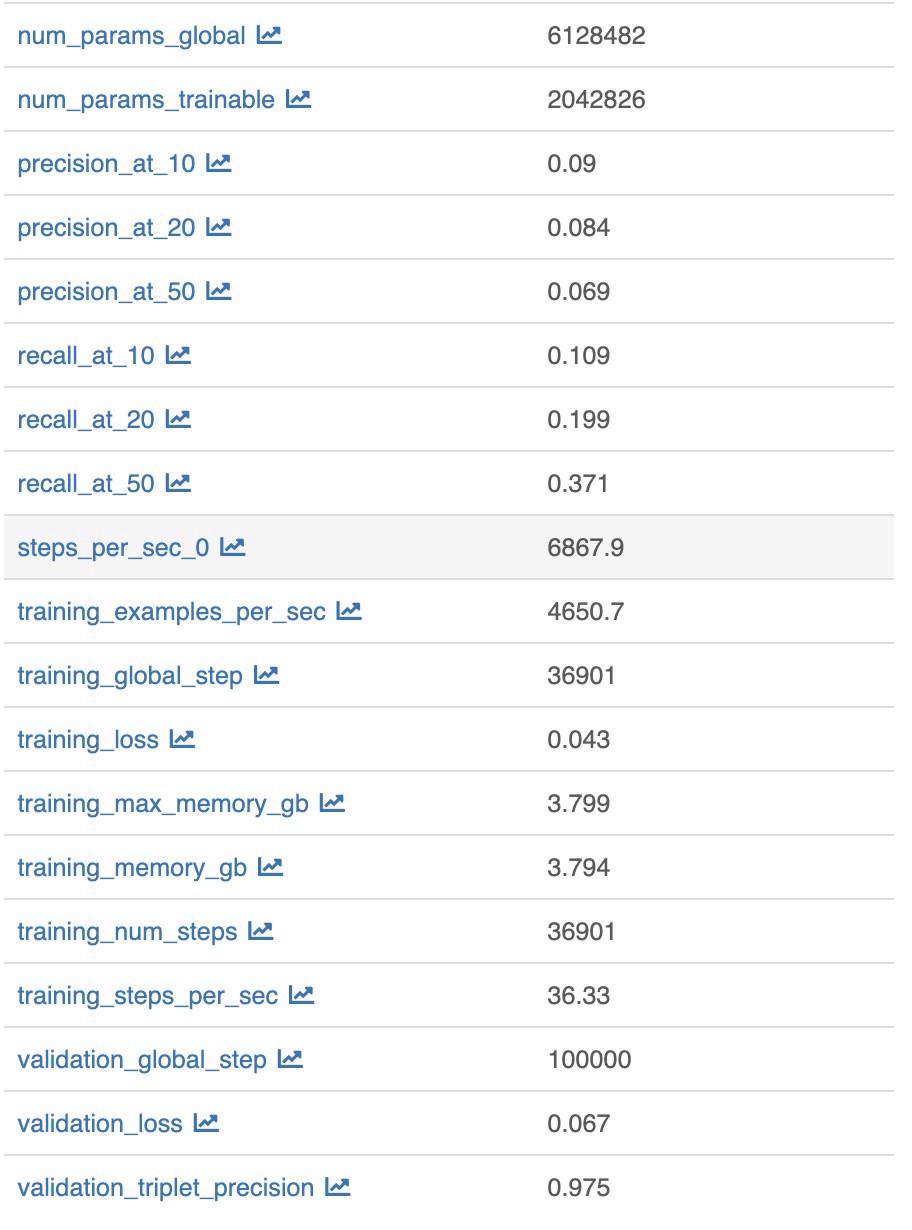
We run the pipeline on Yarn, monitoring progress with MlFlow, and then reload the embeddings to visualize their properties.
我们在Yarn上运行管道,使用MlFlow监视进度,然后重新加载嵌入以可视化其属性。

结论 (Conclusion)
Go ahead, start playing with the notebooks, and please report any feedback on issues!
继续,开始使用笔记本电脑,请报告对问题的任何反馈!
Links Github, Docs, Quickstart, MovieLens Example
链接 Github , 文档 , 快速入门 , MovieLens示例
翻译自: https://medium.com/criteo-labs/deepr-training-tensorflow-models-for-production-dda34a914c3b


















 3022
3022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









