





nlp自然语言处理应用
When building a data science project, one of the last tasks (but not last for importance) that needs to be done is the implementation of a front-end, which makes the model available to the end-users and abstracts them from all the machinery that lies below the user interface.
在构建数据科学项目时,需要完成的最后一项任务(但并非紧要重要)是实现前端,这使模型可供最终用户使用,并从所有机器中提取它们。位于用户界面下方。
The common ways of doing this are:
常用的方法是:
Building a user interface with Angular/React or whatever framework of your choice
使用Angular / React或您选择的任何框架构建用户界面
Relying on Dashboarding tools like Tableau, Power Bi, Qlik…
依赖于Tableau,Power Bi,Qlik等仪表板工具。
If you don’t really like messing with JS frameworks (like me) or want to be able to build a true end-to-end pipeline, then you must use Streamlit at least once.
如果您真的不喜欢像我这样的JS框架,或者想构建真正的端到端管道,则必须至少使用Streamlit一次。
Streamlit, as the website says, is the fastest way to build data apps. And, while it may sound arrogant, it could never be anything more than true.
正如网站所说,Streamlit是构建数据应用程序的最快方法。 而且,尽管这听起来很嚣张,但绝不可能是真实的。
To show how fast it can be to get hands dirty, I built a prototype with Streamlit and HuggingFace’s Transformers, using a pre-trained Question Answering model.
为了显示弄脏双手的速度,我使用预先训练好的问题回答模型,使用Streamlit和HuggingFace的Transformers构建了一个原型。
先决条件:安装Transformers和Streamlit (Prerequisites: Installing Transformers and Streamlit)
Yeah, I said ‘batteries included’, but you gotta buy them first!
是的,我说“包括电池”,但您必须先购买它们!
Open a terminal (or an Anaconda prompt, depending on your choice) and run:
打开一个终端(或Anaconda提示符,取决于您的选择)并运行:
pip install transformers
pip install streamlit代码和结果 (Code and Results)
Once the installation is done, grab your editor and first import the necessary packages:
安装完成后,抓住您的编辑器并首先导入必要的软件包:
import streamlit as st
from transformers import AutoTokenizer,AutoModelForQuestionAnswering
from transformers.pipelines import pipelineThis allows you to use pre-trained HuggingFace models as I don’t want to train one from scratch. Then, you can build a function to load the model; notice that I used the @st.cache() decorator to avoid reloading the model each time (at least it should help reducing some overhead, but I gotta dive deeper into Streamlit’s beautiful documentation):
这使您可以使用预先训练的HuggingFace模型,因为我不想从头开始训练一个模型。 然后,您可以构建一个函数来加载模型; 请注意,我使用@ st.cache()装饰器来避免每次都重新加载模型(至少它应该有助于减少一些开销,但是我必须更深入地研究Streamlit的精美文档):
st.cache(show_spinner=False)
def load_model():
tokenizer = AutoTokenizer.from_pretrained("twmkn9/distilbert- base-uncased-squad2")
model = AutoModelForQuestionAnswering.from_pretrained("twmkn9/distilbert-base-uncased-squad2")
nlp_pipe = pipeline('question-answering',model=model,tokenizer=tokenizer) return nlp_pipenpl_pipe = load_model()Add a header and some text to fill some white gaps together with a sidebar:
添加一个标题和一些文本以填充一些空白,并添加一个侧边栏:
t.header("Prototyping an NLP solution")
st.text("This demo uses a model for Question Answering.")add_text_sidebar = st.sidebar.title("Menu")
add_text_sidebar = st.sidebar.text("Just some random text.")Given the fact that I chose a question answering model, I have to provide a text cell for writing the question and a text area to copy the text that serves as a context to look the answer in. This can be done in two lines:
考虑到我选择了一个问题回答模型,我必须提供一个用于编写问题的文本单元格和一个文本区域来复制用作上下文的文本,以便在其中查找答案。这可以分两行完成:
question = st.text_input(label='Insert a question.')
text = st.text_area(label="Context")Now you can call the model to answer the deepest and hardest questions of the universe. To avoid errors when first loading the app, I wrapped the inference code inside an if statement (totally bad code, must admit it):
现在,您可以调用模型来回答宇宙中最深层和最困难的问题。 为了避免在首次加载应用程序时出现错误,我将推理代码包装在if语句内(完全错误的代码,必须承认):
if (not len(text)==0) and (not len(question)==0):
x_dict = npl_pipe(context=text,question=question)
st.text('Answer: ',x_dict['answer'])And this will output the answer to the question you asked about something in the text you provided.The full code here:
这将在您提供的文本中输出您对所问问题的答案。完整代码如下:
import streamlit as stfrom transformers import AutoTokenizer, AutoModelForQuestionAnswering
from transformers.pipelines import pipelinest.cache(show_spinner=False)
def load_model():
tokenizer = AutoTokenizer.from_pretrained("twmkn9/distilbert-base-uncased-squad2") model = AutoModelForQuestionAnswering.from_pretrained("twmkn9/distilbert-base-uncased-squad2") nlp_pipe = pipeline('question-answering',model=model,tokenizer=tokenizer) return nlp_pipenpl_pipe = load_model()st.header("Prototyping an NLP solution")
st.text("This demo uses a model for Question Answering.")add_text_sidebar = st.sidebar.title("Menu")
add_text_sidebar = st.sidebar.text("Just some random text.")question = st.text_input(label='Insert a question.')
text = st.text_area(label="Context")if (not len(text)==0) and not (len(question)==0):
x_dict = npl_pipe(context=text,question=question
st.text('Answer: ',x_dict['answer'])To run the script, just type: streamlit run script__name.py and it will run by default on localhost:8501, so open it in your browser.Here a screenshot of the output:
要运行该脚本,只需键入: streamlit run script__name.py ,它将默认在localhost:8501上运行,因此在浏览器中将其打开。
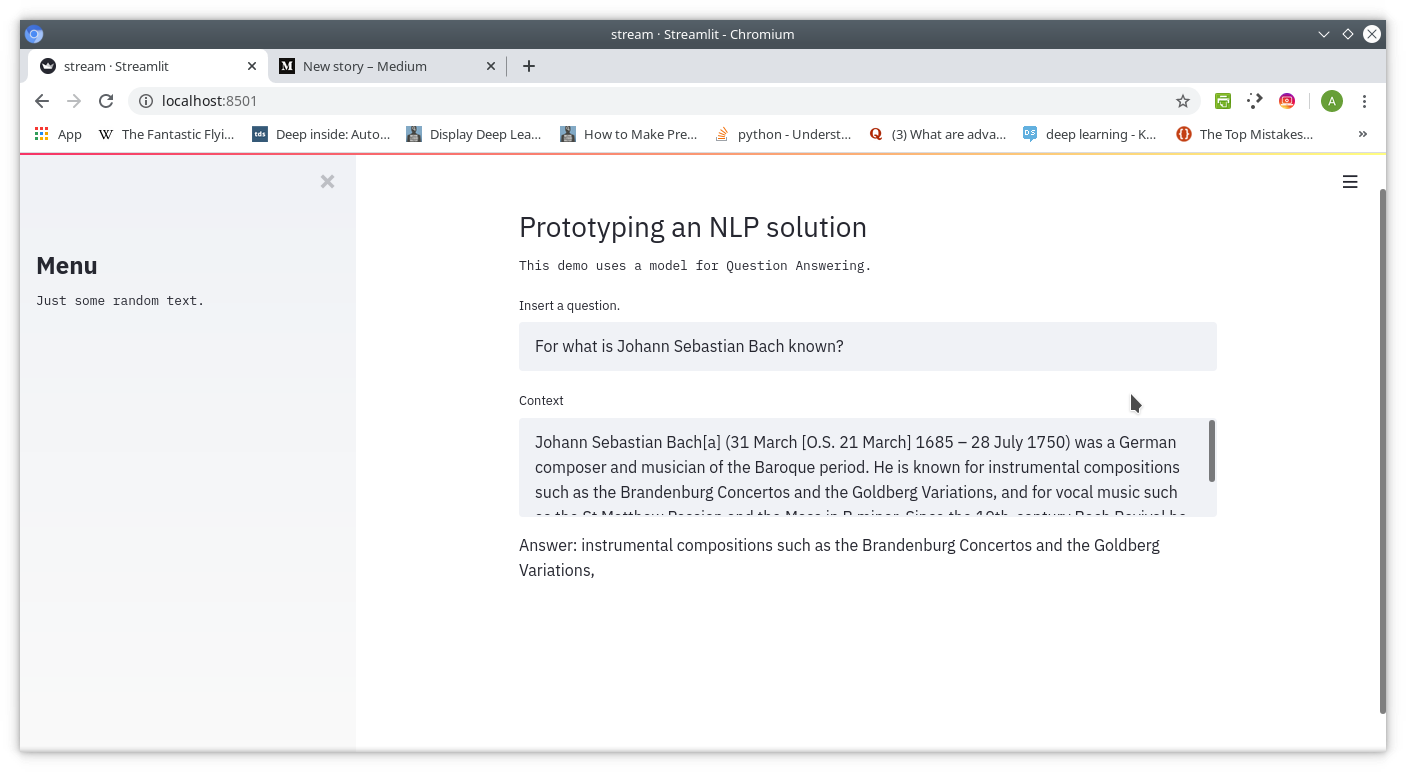
This is not meant of course to represent an exhaustive guide for every feature of Streamlit, but it’s just a way to let others know this great tool in the way I did, by experimenting.
当然,这并不是要代表Streamlit的每个功能的详尽指南,而仅仅是通过实验让其他人以我的方式了解这一出色的工具。
Thanks, and goodbye until next time!
谢谢,再见,直到下一次!
nlp自然语言处理应用

















 6967
6967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









