





 本文探讨了物联网设备采集的数据如何进行大数据分析,重点关注不同类型的存储解决方案。原文来源于Medium,内容涉及物联网数据的处理和利用,是物联网数据分析系列的第一部分。
本文探讨了物联网设备采集的数据如何进行大数据分析,重点关注不同类型的存储解决方案。原文来源于Medium,内容涉及物联网数据的处理和利用,是物联网数据分析系列的第一部分。
物联网采集数据的大数据分析
介绍(Intro)
There is no need to explain how IoT solutions are growing right now and the reasoning behind that. Let’s take it as a fact and from the data architecture perspective consider the following two challenges:
无需解释IoT解决方案现在如何发展以及其背后的原因。 让我们将其视为事实,并从数据架构角度考虑以下两个挑战:
- what kind of storage to select to store the data 选择哪种存储来存储数据
- how to model the data in a way to serve the data analytics needs in the best possible way如何以最佳方式满足数据分析需求的方式对数据建模
问题陈述。 健身追踪范例 (Problem Statement. Fitness Tracking Example)
Let’s consider a domain that should be easy to understand for everyone since it something related to everyday life — fitness tracking.
让我们考虑一个应该让每个人都容易理解的领域,因为它与日常生活相关-健身跟踪。
业务要求(主题领域) (Business Requirements (Subject Area))
In the area of fitness tracking there are the following parties involved:
在健身跟踪方面,涉及以下各方:
- A human. This is a user who wants to track his/her fitness activities, different kinds of health metrics 一个人。 这是一个想要跟踪他/她的健身活动,各种健康指标的用户
- A fitness tracker — a device with a different level of complexity, features, and capacities健身追踪器-复杂性,功能和容量不同的设备
- An intermediate device that usually serves as a connection bridge or gateway between the fitness tracker and the external world. In the majority of cases, this is a smartphone. 中间设备,通常用作健身追踪器和外部世界之间的连接桥或网关。 在大多数情况下,这是智能手机。
使用场景 (Usage Scenarios)
Let’s consider the 2 most popular scenarios of FT(Fitness Tracker) usage:
让我们考虑FT(健身追踪器)使用的两种最流行的方案:
Continuous health metrics monitoring. The fitness tracker continuously monitors the key health metrics like heart rate or stress level of the person as well as the number of steps with certain recurrence bases which is usually every minute or so.
持续的健康指标监控。 健身追踪器持续监控关键的健康指标,例如人的心率或压力水平,以及具有一定复发率的步数(通常每分钟左右)。
Activities Tracking. A user has the ability to track separately the activities or workouts he or she is doing. An activity has a fixed start and end date, during the activity the extended number of metrics, such as pace, strokes per minute, elevation, etc, are gathered usually in a more frequent way, such as every second or so.
活动跟踪。 用户可以单独跟踪他或她正在进行的活动或锻炼。 活动具有固定的开始和结束日期,在活动期间,通常以更频繁的方式(例如,每秒一次)收集扩展的度量标准,例如速度,每分钟的笔触,海拔等。
分析要求 (Analytics Requirements)
Let’s consider the data analytics scenarios
让我们考虑数据分析方案
Simple Descriptive analytics (answering the question of what happened to me/my relatives?):
简单描述性分析(回答我/我的亲戚发生了什么问题?):
- as a FT user, I want to analyze my everyday’s health metrics, such as heart rate, number of steps 作为FT用户,我想分析我的日常健康指标,例如心率,步数
- as a parent, I want to analyze health metrics of my children in real-time (this requirement might sound a little bit weird, but it is well projected to typical use cases of other types of IoT solutions, like monitoring of all the vehicles by the owner of transportation company)作为父母,我想实时分析我孩子的健康指标(这个要求听起来有些怪异,但可以很好地预测到其他类型的物联网解决方案的典型用例,例如通过监控所有车辆运输公司的所有者)
- as a FT user, I want to analyze my activities, aggregated metrics such as min and max pace, velocity, calories, etc for a certain period of time 作为FT用户,我想分析一段时间内的活动,汇总指标,例如最小和最大步速,速度,卡路里等
Advanced Diagnostic Analytics/Ad-Hoc Queries (answering the question why did it happen)
高级诊断分析/临时查询(回答为什么会发生的问题)
- as a FT user, I want to analyze how is my performance among other users with my age, living in my location 作为FT用户,我想分析居住在我所在位置的其他用户在同年龄段的表现如何
- as a FT manufacturer, I want to analyze what types of activities are most used, in which locations作为英国《金融时报》的制造商,我想分析最常用的活动类型,在哪些位置
- as a Data analyst, I want to analyze how other external variables such as weather influences the activities done by different people. What is the correlation between average running pace and peoples age/weight/height? 作为数据分析师,我想分析天气等其他外部变量如何影响不同人的活动。 平均跑步速度与人们的年龄/体重/身高之间有什么关系?
解决方案愿景。 储存选择 (Solution Vision. Storage Selection)
大图景(Big Picture)
The detailed analysis of the solution from an architecture standpoint and its decomposition into the components is out of the scope of this article. Nevertheless, we would need to understand at least at the high level, what kind of storage we are selecting and where they gonna leave in relation to the data source.
从体系结构的角度对解决方案进行详细分析,并将其分解为组件,超出了本文的范围。 但是,我们至少需要在较高层次上了解我们正在选择哪种存储以及它们与数据源之间的关系。
So, at the very high level the solution would be built using the following 3 layers reflected at the picture below:
因此,在很高的层次上,解决方案将使用下面的三层构建,如下图所示:
The role of Edge in our example plays the fitness tracker, Fog is a smartphone and a Cloud is a central place where all the data flows are sunk, central data storage(s) where all the personas interested in the data analysis could access the data.
在我们的示例中,Edge扮演着健身追踪器的角色,Fog是智能手机,而Cloud是所有数据流沉没的中央位置,所有对数据分析感兴趣的人员都可以访问数据的中央数据存储。
Edge is not talking directly to the cloud but is in sync with an intermediary more sophisticated device in the Fog, which can send data directly to the cloud.
Edge并非直接与云对话,而是与Fog中的一个中间端更为复杂的设备同步,该设备可以将数据直接发送至云。
Important Note: Both Edge and Fog layers have also their own embedded databases, which cover the part of basic operational analytics needs. But let’s leave the embedded database selection out of the scope and concentrate on the selection of the database engines in the cloud for the broader analytics needs.
重要说明: Edge和Fog层也都有自己的嵌入式数据库,这些数据库满足基本运营分析需求的一部分。 但是,让我们将嵌入式数据库的选择放在范围之外,而将精力集中在云中为更广泛的分析需求而选择数据库引擎上。
选择的关键驱动力 (Key Drivers for the Selection)
In order to select the best storage covering our analytics need, let’s translate our analytics requirements into a representation that would drive the actual selection. Let’s also add the non-functional requirements which play an important role in engine selection.
为了选择最能满足我们分析需求的存储,让我们将分析需求转换成能够推动实际选择的表示形式。 我们还添加非功能性需求,这些需求在引擎选择中起着重要作用。
Here there is a translated version, a list of required abilities:
这里有一个翻译版本,必备功能列表:
简单的描述性分析: (Simple Descriptive analytics:)
Random data access using the particular FT user, time criteria, and proper health metric
使用特定的FT用户,时间标准和适当的健康指标进行随机数据访问
Range scans using the time range as a base limited to the particular FT user or couple of predefined users (kids of a person), and particular metric or couple of metrics
使用时间范围作为基础的范围扫描仅限于特定的FT用户或几个预定义的用户(一个人的孩子),以及特定的指标或几个指标
Aggregation on small data ranges using the time range as a bases
使用时间范围作为基础在小数据范围上进行聚合
高级诊断分析/即席查询(Advanced Diagnostic Analytics/Ad-Hoc Queries)
Aggregations on big data ranges
大数据范围上的聚合
Filtering and Grouping on different dimensional attributes ( person, tracker, location, activity type attributes)
根据不同的维度属性(人员,跟踪者,位置,活动类型属性)进行过滤和分组
Correlation analysis: analyzing of different metrics by the common axes/dimensions
相关分析:通过公共轴/维度分析不同指标
非功能要求(Non-Functional Requirements)
Besides the functional requirements which we covered by the data analytics needs lets add a couple more non-functional ones which are pretty standard in the modern IoT world:
除了数据分析需求所涵盖的功能需求之外,我们还可以添加一些在现代物联网世界中非常标准的非功能需求:
big data scale: this is a pretty obvious requirement considering an ambitious FT manufacturer with dozens of thousands of users, having the devices, which could generate each second a set of different metrics, so potentially data volume could be really big
大数据规模:考虑到一个雄心勃勃的FT制造商,该制造商拥有成千上万的用户,并且拥有可以每秒产生一组不同指标的设备,因此这是一个非常明显的要求,因此潜在的数据量可能真的很大
real-time data access to the most important metrics, let say all the simple descriptive analytics is required to be accessible in real-time
实时数据访问最重要的指标,可以说所有简单的描述性分析都需要实时访问
analytics queries response time should be reasonably short — a couple of second for simple descriptive queries and up to 20–30 seconds for all other sophisticated analytical queries.
分析查询的响应时间应相当短-简单描述性查询的响应时间为几秒钟,而其他所有复杂分析查询的响应时间则为20-30秒。
解 (Solution)
There is no single storage capable to meet all the architecturally significant requirements at once, there is no silver bullet type of storage which would be able at the same time:
没有单个存储可以一次满足所有对体系结构的重要要求,也没有可以同时满足以下条件的银弹式存储:
- handle fast random reads and writes and flexible grouping abilities at the big data scale 在大数据规模上处理快速的随机读写操作和灵活的分组能力
- be row- and column-oriented simultaneously (row- orientation allows faster writes, while column- orientation allows fast aggregations on bigger data ranges)同时面向行和列(行方向允许更快的写入,而列方向允许在更大的数据范围上快速聚合)
Note: someone can argue that some of the so-called NewSQL engines like Exasol, MemSQL, SAP HANA, etc. can handle different query patterns efficiently, and that might be true for many cases, but it is important to keep in mind that at the really big scale (i.e.: dozens of terabytes) they becoming crazy-expensive
注意:有人可能会争辩说,某些所谓的NewSQL引擎(例如Exasol,MemSQL,SAP HANA等)可以有效地处理不同的查询模式,这在许多情况下可能是正确的,但请务必记住真正大的规模(即:数十兆字节),它们变得疯狂昂贵
So, having stated that, it is proposed to have 2 types of storages to handle different types of analytics scenarios:
因此,尽管如此,建议具有两种类型的存储来处理不同类型的分析方案:
1. NoSQL storage capable to handle fast random reads and writes. Preferably this type of storage would be able to perform efficiently the short-range scans based on timing. The set of data engines positioning themselves as time-series databases would fit here well.
1. NoSQL存储能够处理快速的随机读写。 优选地,这种类型的存储将能够基于定时有效地执行短距离扫描。 将自己定位为时间序列数据库的一组数据引擎非常适合此处。
- This type of storage would satisfy in the best possible way the requirements related to real-time simple descriptive analytics at the big data scale 这种类型的存储将以最佳的方式满足大数据规模上与实时简单描述性分析有关的需求
- This type of storage is also treated as “hot” meaning the real-time data which is just created/prepared and is already ready to be consumed.这种类型的存储也被视为“热”,这意味着刚刚创建/准备好并且已经可以使用的实时数据。
2. Analytics/Data Warehouse type of engine with the support of the relational data model. The proper star schema data model design pattern assures the maximum flexibility, efficient data aggregations, and is well scaled.
2.带有关系数据模型支持的引擎的Analytics / Data Warehouse类型。 正确的星型模式数据模型设计模式可确保最大的灵活性,有效的数据聚合并具有良好的可伸缩性。
- This type of storage would satisfy in the best possible way the requirements related to the efficient and flexible data analysis on the big data scale. 这种类型的存储将以最大可能的方式满足与大数据规模上高效而灵活的数据分析相关的要求。
- Referred to as “warm” or “cold” meaning the data is not as fresh and hot as in real-time scenarios which from another hand gives time to prepare it better for more delicious and deeper analysis 称为“暖”或“冷”,意味着数据不像实时场景中的那么新鲜和热,这从另一方面可以给您腾出时间来准备更好地进行更美味和更深入的分析的数据。
The high level separation of the data and its usage by the end users is depicted below:
最终用户对数据及其使用的高级分离如下所示:
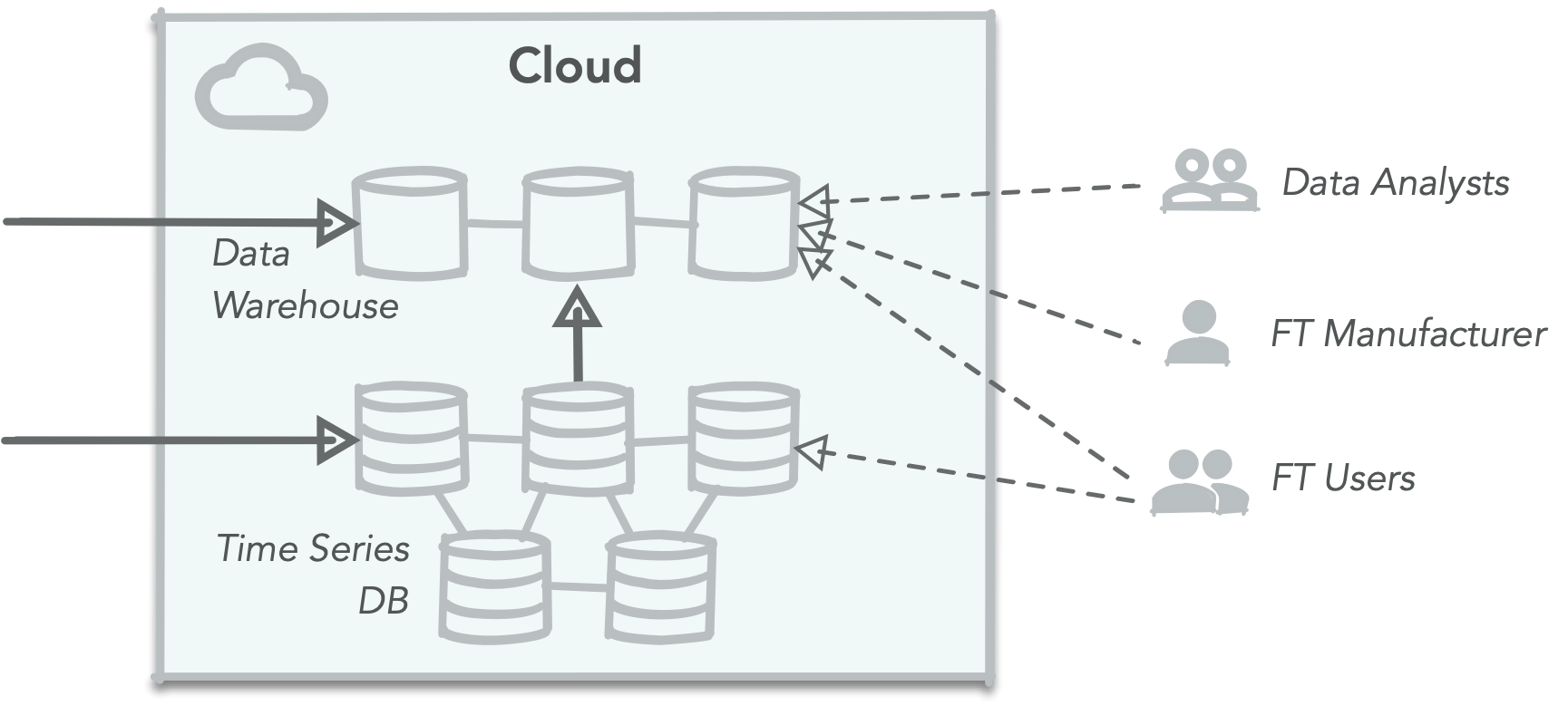
技术选择(Technology Selection)
There are plenty of different database engines that would match the descriptions for both options described above. The actual selection depends on many things, like existing licenses, cost limitations, cloud provider used, team’s skillset, etc. Each engine has its own pros and cons which is a topic of many subjective comparison articles.
有许多不同的数据库引擎可以与上述两个选项的描述相匹配。 实际的选择取决于许多因素,例如现有许可证,成本限制,使用的云提供商,团队的技能等等。每个引擎都有自己的优缺点,这是许多主观比较文章的主题。
But to name a few examples you could consider the following options:
但仅举几个例子,您可以考虑以下选项:
NoSQL storage with time-series capabilities: InfluxDB and OpensTSDB and many others. From the cloud provider’s offerings: Azure CosmosDB, AWS Dynamo DB or GCP BigTable
具有时间序列功能的NoSQL存储:InfluxDB和OpensTSDB等。 来自云提供商的产品:Azure CosmosDB,AWS Dynamo DB或GCP BigTable
Scalable Data Warehouse: Plenty of great options here like Vertica DB, SnowFlake DB, Azure Synapse(Data Warehouse), AWS Redshift, or GCP BigQuery.
可扩展的数据仓库:这里有很多不错的选择,例如Vertica DB,SnowFlake DB,Azure Synapse(数据仓库),AWS Redshift或GCP BigQuery。
数据模型注意事项 (Data Model Considerations)
The proper data model plays one of the crucial roles in efficient data analysis. It worth another article. So the next part will be dedicated to the data model. Stay tuned )
适当的数据模型在有效的数据分析中起着至关重要的作用之一。 值得另一篇文章。 因此,下一部分将专门介绍数据模型。 敬请关注 )
Update: the data model part2 is published here:
更新:数据模型第2部分发布在这里:
结论 (Conclusion)
We introduced an interesting challenge of building the IoT solution from the data architecture, in particular from the storage selection, point of view. We identified a pair of database types of storages that are required to cover all the requirements and explained the reasoning behind it. The next step would be the preparation of the most efficient data model.
我们从数据架构,尤其是从存储选择的角度出发,提出了构建物联网解决方案的有趣挑战。 我们确定了满足所有需求所需的一对存储数据库类型,并解释了其背后的原因。 下一步将是准备最有效的数据模型。
翻译自: https://medium.com/@andriy.zabavskyy/iot-data-analytics-part1-types-of-storages-677b8a24657d
物联网采集数据的大数据分析


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









