





 本文介绍了如何对推文进行预处理,以供BERT模型进行情感分析的预训练。内容涉及数据来源和翻译自Medium的文章链接。
本文介绍了如何对推文进行预处理,以供BERT模型进行情感分析的预训练。内容涉及数据来源和翻译自Medium的文章链接。
bert 情感分析 预训练
When doing any Natural Language Processing (NLP) you will need to pre-process your data. In the following example I will be working with a Twitter dataset that is available from CrowdFlower and hosted on data.world.
在进行任何自然语言处理(NLP)时,您需要预处理数据。 在以下示例中,我将使用Twitter数据集,该数据集可从CrowdFlower获得,并托管在data.world上。
查看数据 (Review the data)
There are many things to consider when choosing how to preprocess your text data, but before you do that you will need to familiarize yourself with your data. This dataset is provided in a .csv file; I loaded it into a dataframe and proceeded to review it.
选择如何预处理文本数据时,需要考虑很多事情,但是在进行此操作之前,您需要熟悉数据。 该数据集以.csv文件形式提供; 我将其加载到数据框中,然后进行了审查。
dataframe = pd.read_csv(data_file)
dataframe.head()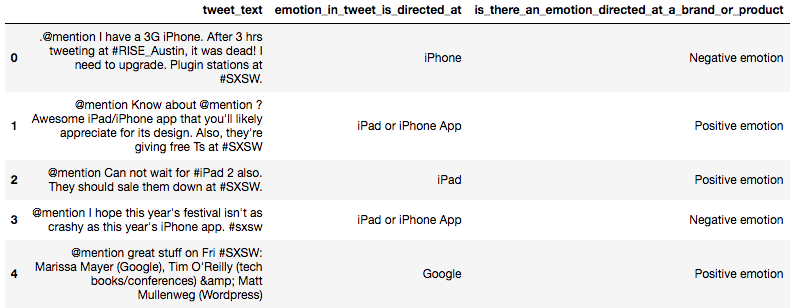
Just looking at the first five rows, I can notice several things:* In these five tweets the Twitter handles have been replaced with @mention* They all have the hashtag #SXSW or #sxsw* There is an html character reference for ampersand &* There are some abbreviations: hrs, Fri* There are some people’s real names, in this case public figures
仅查看前五行,我会注意到几件事:*在这五条推文中,Twitter句柄已替换为@mention *它们都带有#SXSW或#sxsw的井号标签*对于&符,有一个html字符引用。 *有些缩写:hrs,Fri *有些人的真实姓名,在这种情况下为公众人物
This dataset contains about 8500 tweets, I won’t be able to review them all, but by reviewing segments of the dataset I was able to find other peculiarities to the data.* There are some url links, some with http or https, and some without* There are some url links that have been changed to a reference of {link}* There are some other html characters besides &* References to a video have been replaced with [video]* There were many non-english characters* There were many emoticons
该数据集包含大约8500条tweet,我无法全部查看它们,但是通过查看数据集的各个部分,我可以找到该数据的其他特性。*有些URL链接,有些带有http或https,并且一些不带*的URL链接已更改为对{link}的引用*除&之外还有一些其他html字符。 *对视频的引用已替换为[video] *有很多非英语字符*有很多表情符号
决定时间(Decision Time)
Now that the data has been reviewed, it’s time to make some decisions about how to process it.
既然已经对数据进行了审查,那么现在该就如何处理数据做出一些决定了。
Lowercase? It’s common when doing NLP to lowercase all the words so that a “Hello” is the same as “hello” or “HELLO”. When dealing with tweets, which are not going to follow standard capitalization rules, you should pause before lowercaseing everything. For example, it’s common to use all caps for emphasis in a tweet when you would rarely do that when writing a formal sentence. For my dataset I chose to just change all the letters to lowercase because I didn’t think I had a large enough dataset that enough additional information would be gained by keeping more than one version of a word. Converting all the letters is easily done using a Python string function.
小写? 在执行NLP时,将所有单词都小写以使“ Hello”与“ hello”或“ HELLO”相同是很常见的。 在处理不遵循标准大写规则的推文时,应暂停操作,然后再小写所有内容。 例如,通常在推文中使用所有大写字母来强调重点,而在写正式句子时很少这样做。 对于我的数据集,我选择仅将所有字母更改为小写字母,因为我认为我没有足够大的数据集,无法通过保留一个单词的多个版本来获得足够的附加信息。 使用Python字符串函数可以轻松完成所有字母的转换。
df_clean['tweet_text'] = dataframe.tweet_text.str.lower()URL links I didn’t think URLs would help with sentiment analysis so I wanted to remove them. Removing URLs is not as simple as changing letters to lowercase, it involved using regular expressions (regex). I used two expressions, one for URLs with http or https, and a second for URLs without them, but with or without www.
URL链接我认为URL不会有助于情绪分析,因此我想删除它们。 删除URL并不像将字母更改为小写字母那样简单,而是使用正则表达式(regex)。 我使用了两个表达式,一个用于带有http或https的URL,第二个用于不带它们但带或不带www的URL。
df_clean.tweet_text = df_clean.tweet_text.apply(lambda x: re.sub(r'https?:\/\/\S+', '', x))df_clean.tweet_text.apply(lambda x: re.sub(r"www\.[a-z]?\.?(com)+|[a-z]+\.(com)", '', x))Writing regular expressions can be tricky; I use regexr.com to test mine out.
编写正则表达式可能很棘手。 我使用regexr.com进行测试。
Placeholders Some text cleaning was already done on the dataset which replaced some links with {link} and all the videos with [video]. They don’t seem to be of any value when doing sentiment analysis so I will remove them with regex.
占位符已经对数据集进行了一些文本清理,用{link}替换了某些链接,并用[video]替换了所有视频。 在进行情感分析时,它们似乎没有任何价值,因此我将使用正则表达式将其删除。
df_clean.tweet_text = df_clean.tweet_text.apply(lambda x: re.sub(r'{link}', '', x))df_clean.tweet_text = df_clean.tweet_text.apply(lambda x: re.sub(r"\[video\]", '', x))HTML reference characters I don’t think these are of any value to the analysis so they also should be removed.
HTML参考字符我认为这些对分析没有任何意义,因此也应将其删除。
df_clean.tweet_text = df_clean.tweet_text.apply(lambda x: re.sub(r'&[a-z]+;', '', x))Non-Letter characters I decided to get rid of all the characters that weren’t letters, punctuation that is commonly used in emojis, or hash marks. There were a few non-english characters in the tweets. I didn’t think they would add to the analysis so I wanted to remove them. Numbers typically don’t add much if any information so I wanted to remove them. Punctuation that isn’t usually associated with an emoji needed to be removed too because it didn’t add anything. I did all this with one regex.
非字母字符我决定删除所有不是字母的字符,表情符号中常用的标点符号或井号。 推文中有一些非英语字符。 我认为它们不会添加到分析中,所以我想删除它们。 如果有任何信息,数字通常不会增加太多,所以我想删除它们。 通常不与表情符号相关的标点也需要删除,因为它没有添加任何内容。 我用一个正则表达式完成了所有这一切。
df_clean.tweet_text = df_clean.tweet_text.apply(lambda x: re.sub(r"[^a-z\s\(\-:\)\\\/\];='#]", '', x))Twitter handles Prior the text pre-processing stage, I changed all the twitter handles to @mention in acknowledgement of the need for protecting people’s privacy. Because this dataset has been public for years I wasn’t adding much protection, but when creating new datasets, an attempt to anonymize the data should be made. Since I had already changed them all to @mention it was easier to remove all of them; again because they added little information.
Twitter句柄在文本预处理阶段之前,我承认需要保护人们的隐私,因此我将所有Twitter句柄都更改为@mention 。 由于该数据集已经公开多年,因此我并没有增加太多保护,但是在创建新数据集时,应尝试使数据匿名化。 由于我已经将它们全部更改为@mention,因此将它们全部删除更容易; 再次因为他们添加了很少的信息。
df_clean.tweet_text = df_clean.tweet_text.apply(lambda x: re.sub(r'@mention', '', x))Real Names They are another privacy issue. If this was a brand new dataset, I think they should be removed prior to publishing the data. In this case where the data has been public for years, I left them in the dataset.
实名他们是另一个隐私问题。 如果这是一个全新的数据集,我认为应在发布数据之前将其删除。 在这种情况下,数据已经公开多年,我将它们留在数据集中。
Abbreviations Depending on your analysis you may want to deal with abbreviations vs. full words. From above there is hrs and Fri. You may want to keep them as is or may want hrs to be considered the same as hours when doing sentiment analysis. For my analysis I used the WordNetLemmatizer within the NLTK package. It does not deal with these abbreviations and I didn’t think it would add enough value to create a function to search for and convert abbreviations to the full version of the words. This would be a very large undertaking given all the existing abbreviations.
缩写根据您的分析,您可能需要处理缩写与完整单词。 从上面有小时和星期五。 您可能希望保留他们作为是或可能想要小时,做情感分析时应该考虑的一样小时。 为了进行分析,我使用了NLTK软件包中的WordNetLemmatizer。 它不处理这些缩写,并且我认为它不会增加足够的值来创建一个函数来搜索缩写并将其转换为单词的完整版本。 考虑到所有现有的缩写,这将是一项非常大的任务。
标记文本 (Tokenize the text)
Now to tokenize the pre-processed tweets. There are a variety of ways to do this but I chose to use the TweetTokenizer from NLTK. It knows to keep emojis together as a token and to keep hashtags together. I already removed all the Twitter handles, but if I hadn’t it would tokenize them as @ plus the handle.
现在将标记化预处理的推文。 有多种方法可以执行此操作,但是我选择使用NLTK中的TweetTokenizer。 它知道将表情符号放在一起作为标记,并将标签标签放在一起。 我已经删除了所有Twitter句柄,但是如果没有,它将把它们标记为@加上句柄。
from nltk.tokenize import TweetTokenizertknzr = TweetTokenizer()df_clean['tokens'] = df_clean['tweet_text'].apply(tknzr.tokenize)Let’s compare the cleaned tweet_text with the tokenized version of a segment of the data.
让我们将清除的tweet_text与数据段的标记化版本进行比较。

The tokenizer returned a list of strings for each tweet. You can see that the hashtags are kept, ie. #sxsw, words with dashes or apostrophes within them are kept, ie. pop-up, other punctuation is tokenized as individual tokens, ie. the colon at the end of tweet #515, and emojis are kept intact, ie. :) in tweet #514.
令牌生成器为每个推文返回一个字符串列表。 您可以看到标签被保留,即。 #sxsw,其中带有破折号或撇号的单词将保留,即。 弹出窗口,其他标点符号化为单独的标记,即515号推文结尾处的冒号,并且表情符号保持完整,即。 :)在Twitter#514中。
更多清洁 (More Cleaning)
Because I didn’t remove punctuation that is commonly used for emojis earlier, now that the emojis have been tokenized, it’s time to remove it.
因为我没有删除较早用于表情符号的标点符号,所以既然表情符号已被标记化了,是时候将其删除了。
I first created a punctuation list and then applied a filter to each tokenized list, keeping only the tokens that are not in the punctuation list. Using this method will leave all the punctuation that is part of a word or an emoji.
我首先创建了一个标点符号列表,然后将过滤器应用于每个标记化列表,仅保留不在标点符号列表中的标记。 使用此方法将保留作为单词或表情符号一部分的所有标点符号。
PUNCUATION_LIST = list(string.punctuation)def remove_punctuation(word_list):
"""Remove punctuation tokens from a list of tokens"""
return [w for w in word_list if w not in PUNCUATION_LIST]df_clean['tokens'] = df_clean['tokens'].apply(remove_punctuation)更多决定 (More Decisions)
Do you want to keep the stop words? According to a study, removing stop words from tweets when doing sentiment analysis degrades classification performance. I decided to trust this study’s findings and didn’t remove the stop words.
您要保留停用词吗? 根据一项研究,在进行情感分析时从推文中删除停用词会降低分类性能。 我决定相信这项研究的发现,并且没有删除停用词。
- Do you want to stem or lemmatize the words? For some of the models I ran, I used the WordNetLemmatizer mentioned above and for some I didn’t. I got mixed results when lemmatizing the words in the tweets, but that may be due to the contents or size of my dataset. 您是否要阻止或限制单词的使用? 对于我运行的某些模型,我使用了上面提到的WordNetLemmatizer,而对于某些我没有使用的模型。 对推文中的单词进行词素化时,结果参差不齐,但这可能是由于数据集的内容或大小所致。
模特时间 (Model Time)
I don’t go through the modeling steps here, but after the above text pre-processing I was ready to train some classifiers.
我在这里不进行建模步骤,但是在对文本进行了上述预处理之后,我准备训练一些分类器。
If you would like to check out my full project and additional code, it’s hosted on github here.
如果您想查看我的完整项目和其他代码,它托管在github here上。
翻译自: https://medium.com/@merb92/pre-processing-tweets-for-sentiment-analysis-a74deda9993e
bert 情感分析 预训练

















 2177
2177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









