





What is AWS CloudFormation
什么是AWS CloudFormation
CloudFormation(CF) is a service, which allows you to set up and manage AWS resources via a template. This allows you to spend more time in developing your application than on managing & provisioning your resources.
CloudFormation(CF)是一项服务,使您可以通过模板设置和管理AWS资源。 这使您比在管理和供应资源上花费更多的时间来开发应用程序。
So if you want to set up the following infrastructure;
因此,如果您想建立以下基础架构;
- A security group 一个安全小组
- An EC2 instanceEC2实例
- A volume一卷
- A Managed database (like Amazon RDS)托管数据库(如Amazon RDS)
AWS CF will provision all the resources in the right order with the correct configuration
AWS CF将使用正确的配置以正确的顺序配置所有资源
Some benefits of AWS Cloudformation:
AWS Cloudformation的一些好处:
It’s Infrastructure as Code
基础架构即代码
- Since resources are not manually created, you can establish version control through git. Changes to infrastructure can now be controlled through code. 由于资源不是手动创建的,因此可以通过git建立版本控制。 现在可以通过代码控制对基础结构的更改。
- Once a template is created, you can find out the monthly costs via the estimate cost option! 创建模板后,您可以通过估算费用选项找出每月费用!
- Its also easy to deploy or destroy any resources, by creating a stack or deleting it. 通过创建堆栈或删除堆栈,还很容易部署或破坏任何资源。
What we will learn in this post?
我们将从这篇文章中学到什么?
In this post we will create a CloudFormation stack to provision the following resources:
在本文中,我们将创建一个CloudFormation堆栈来配置以下资源:
- An ElasticSearch domain: for storing & querying tweets ElasticSearch域:用于存储和查询推文
- A S3 bucket: stores tweets which failed to processS3存储桶:存储未能处理的推文
- Kinsesis firehose: for streaming covid19 tweetsKinsesis firehose:用于流式传输covid19 tweets
- Lambda function: for processing tweets Lambda函数:用于处理推文
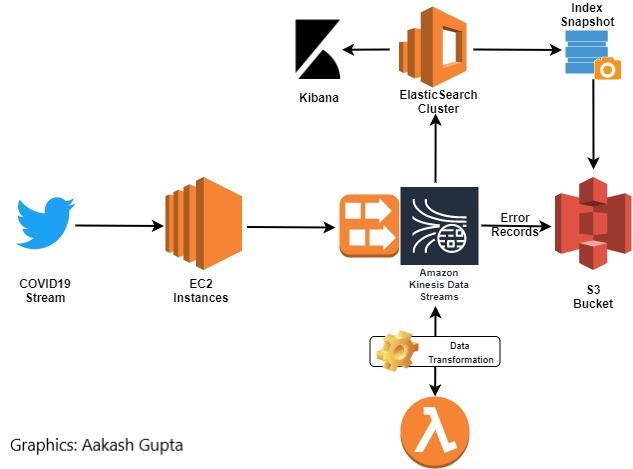
First let’s understand the data that we are processing, and then we will understand the ingestion pipeline.
首先,让我们了解正在处理的数据,然后了解获取管道。
COVID-19 Twitter Stream
COVID-19 Twitter流
Twitter has released a streaming end-point into their Twitter Developer Labs. The streaming endpoint will return Tweets based on their internal COVID19 annotations. The endpoint is configured with a set of filters which delivers a comprehensive view of the conversation about this topic.
Twitter已将流式传输端点发布到其Twitter开发人员实验室。 流媒体端点将基于其内部COVID19注释返回推文。 端点配置有一组过滤器,这些过滤器提供有关此主题的对话的全面视图。
The tweets were collected from the streaming endpoint by a team from the University of Southern California. This dataset is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License (CC BY-NC-SA 4.0). By using this dataset, you agree to abide by the stipulations in the license, remain in compliance with Twitter’s Terms of Service, and cite the following manuscript:
这些推文是由南加州大学的一个团队从流媒体端点收集的。 此数据集已根据知识共享署名-非商业性-相同方式共享4.0国际公共许可证( CC BY-NC-SA 4.0 )进行了许可。 使用此数据集,即表示您同意遵守许可证中的规定,并遵守Twitter的服务条款,并引用以下原稿:
Chen E, Lerman K, Ferrara E Tracking Social Media Discourse About the COVID-19 Pandemic: Development of a Public Coronavirus Twitter Data Set JMIR Public Health Surveill 2020;6(2):e19273 DOI: 10.2196/19273 PMID: 32427106
Chen E,Lerman K,Ferrara E追踪关于COVID-19大流行的社交媒体报道:开发冠状病毒公共Twitter数据集JMIR Public Health Surveill 2020; 6(2):e19273 DOI:10.2196 / 19273 PMID:32427106
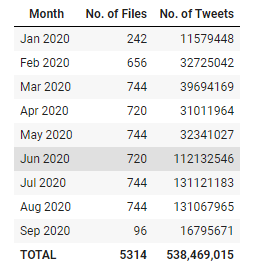
As of 14th September 2020, the dataset had more than 538mn tweets!
截至2020年9月14日,数据集的推文数量超过5.38亿!
Data Ingestion Pipeline
数据提取管道
Due to the ToS with Twitter developer API, only the tweet IDs are stored in the github repo. This is known as dehydrating the tweet.
由于使用了带有Twitter开发人员API的ToS,因此仅将tweet ID存储在github存储库中。 这被称为使鸣叫脱水。
Hydrating the tweet is when we use the tweet ID and call the twitter API, to populate the other fields (dictionary keys) The hydrated tweet is then put into a datastream which writes to a Kinesis firehose.
对推文进行水化处理是指使用推文ID并调用twitter API,以填充其他字段(字典键)。然后将水化的推文放入写入Kinesis firehose的数据流中。
A Lambda function is used to process the tweets in batches of 5MiB.
Lambda函数用于按批处理5MiB的推文。
Lambda function is used to select only a certain set of keys from the Tweet object.
Lambda函数用于从Tweet对象中选择一组特定键。
The processed tweets are then stored in the ElasticSearch domain. If the process fails, they are routed to a S3 bucket. The S3 bucket can also be used to store a snapshot of the ES index.
然后,已处理的推文将存储在ElasticSearch域中。 如果该过程失败,则将它们路由到S3存储桶。 S3存储桶还可以用于存储ES索引的快照。
Hydrating the tweet IDs
充实推文ID
I have uploaded the python code and other files for this project in the following github repo. Feel free to use, share & star it:
我已经在以下github存储库中上传了该项目的python代码和其他文件。 随时使用,共享和加注星标:
https://github.com/skyprince999/Data-Engineering-Covid19-ETL
https://github.com/skyprince999/Data-Engineering-Covid19-ETL
We will now create the stack for provisioning the resources.
现在,我们将创建用于配置资源的堆栈。
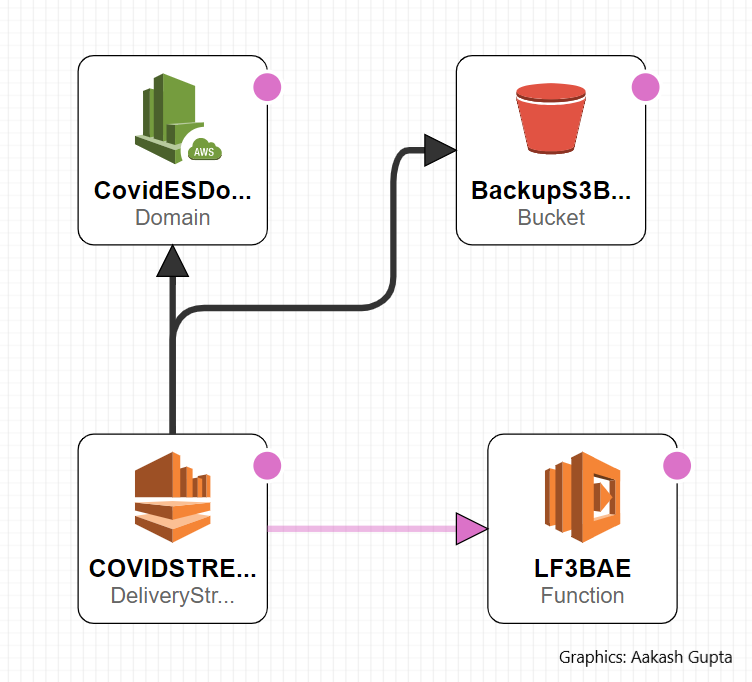
CloudFormation template for S3 Bucket
S3存储桶的CloudFormation模板
AWSTemplateFormatVersion: "2010-09-09"
Resources:
BackupS3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: "es-covidtweets-err"This is the simplest template in our stack. In fact you don’t even need to specify the bucket-name!
这是我们堆栈中最简单的模板。 实际上,您甚至不需要指定存储桶名称!
CloudFormation template for ElasticSearch domain
ElasticSearch域的CloudFormation模板
CovidESDomain:
Type: AWS::Elasticsearch::Domain
Properties:
DomainName: "covidtweets"
ElasticsearchClusterConfig:
DedicatedMasterEnabled: false
InstanceCount: 4
ZoneAwarenessEnabled: false
InstanceType: "t2.small.elasticsearch"
EBSOptions:
EBSEnabled: true
Iops: 0
VolumeSize: 35
VolumeType: "gp2"
ElasticsearchVersion: "7.7"
SnapshotOptions:
AutomatedSnapshotStartHour: "0"
DomainEndpointOptions:
EnforceHTTPS: trueWe will use the template to provide the configuration for ES domain. We have 4 data nodes in the cluster (InstanceCount) each of type t2.small (InstanceType)
我们将使用模板为ES域提供配置。 集群中有4个数据节点( InstanceCount ),每个数据节点的类型均为t2.small ( InstanceType )
All nodes have 35GiB of EBS volume (VolumeSize)
所有节点都有35GiB的EBS卷( VolumeSize )
The ElasticSearch version is the latest (7.7) (ElasticsearchVersion)
ElasticSearch版本是最新的( 7.7 )( ElasticsearchVersion )
AccessPolicies:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
AWS: "*"
Action: "es:*"
Resource: !Sub "arn:aws:es:us-east-1:$(AWS::AccountId):domain/covidtweets/*"
Condition:
IpAddress:
aws:SourceIP: "*"
AdvancedOptions:
rest.action.multi.allow_explicit_index: "true"The next gist provides the access policy for the ES domain. We allow all actions to be performed on the domain. There is also no restrictions on the SourceIP (*) That means, you can access the domain from any IP address.
下一个要点提供了ES域的访问策略。 我们允许在域上执行所有操作。 SourceIP(*)也没有限制,这意味着您可以从任何IP地址访问域。
This is not the best practice for configuring the access policy. You can change the access policy to be more restrictive.
这不是配置访问策略的最佳实践。 您可以将访问策略更改为更具限制性。
CloudFormation template for Kinesis Firehose
Kinesis Firehose的CloudFormation模板
COVIDSTREAM:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: "covid-stream"
DeliveryStreamType: "DirectPut"
ElasticsearchDestinationConfiguration:
BufferingHints:
IntervalInSeconds: 300
SizeInMBs: 5
DomainARN: !GetAtt CovidESDomain.Arn
IndexName: "covidtweets"
RoleARN: <Replace with RoleARN>
S3BackupMode: "FailedDocumentsOnly"
S3Configuration:
BucketARN: !GetAtt BackupS3Bucket.Arn
BufferingHints:
IntervalInSeconds: 300
SizeInMBs: 5
RoleARN: <Replace with RoleARN>The cloudformation template is used to configure a Kinesis Firehose. The stream is of type DirectPut. The buffering of the data is for an interval of 300sec or until the size is 5MiB!
cloudformation模板用于配置Kinesis Firehose。 流的类型为DirectPut。 数据的缓冲时间为300秒或直到大小为5MiB!
The processed data is stored in an ElasticSearch domain, while the failed data is stored in a S3 bucket. Since the ES domain & the S3 bucket were created via the CF stack. We can access their domain names by using the Fn::GetAtt function
处理后的数据存储在ElasticSearch域中,而失败的数据存储在S3存储桶中。 由于ES域和S3存储桶是通过CF堆栈创建的。 我们可以使用Fn :: GetAtt函数访问其域名
Check the complete CloudFormation template in my public github repo:
在我的公共github存储库中检查完整的CloudFormation模板:
The template file can be uploaded through the CloudFormation console.
可以通过CloudFormation控制台上传模板文件。
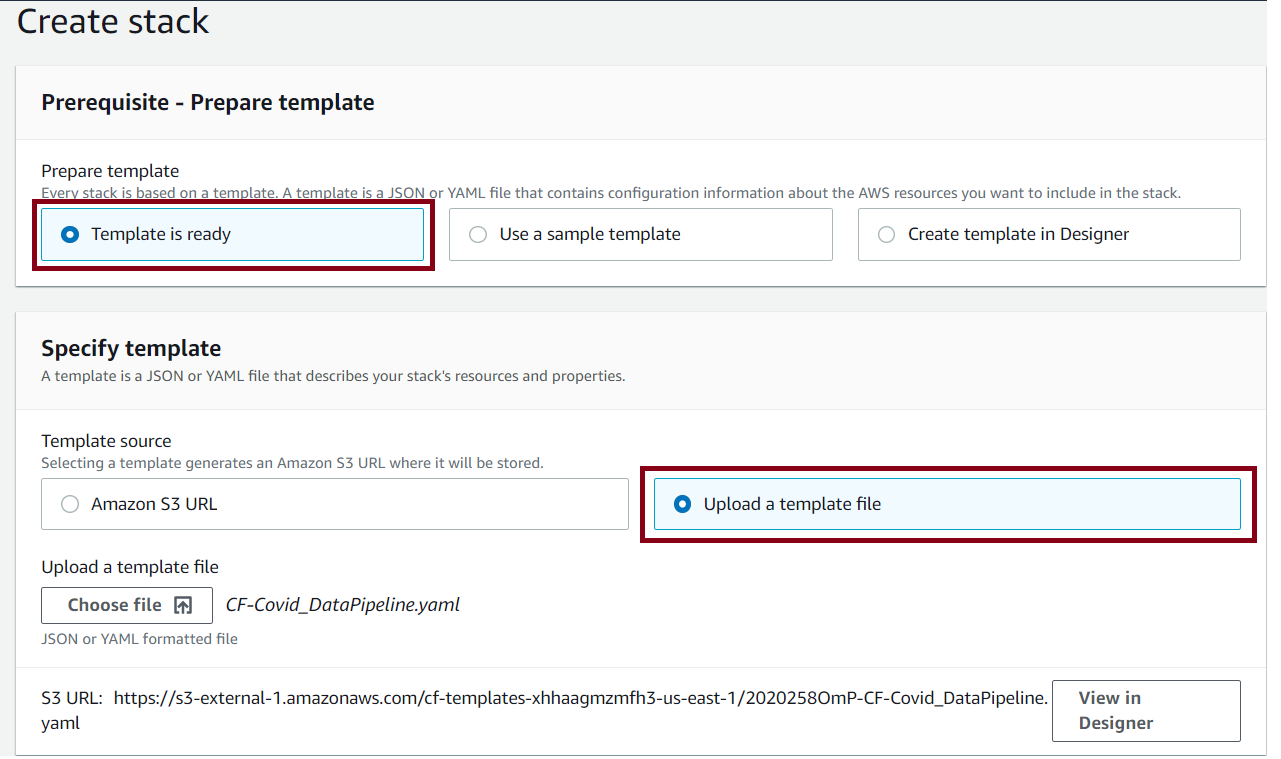
Review the template in the designer & then upload it to a S3 bucket.
在设计器中查看模板,然后将其上传到S3存储桶。
Provide a name to the stack and then review the configuration. You can use the AWS estimator, to calculate the cost of the resources.
为堆栈提供一个名称,然后查看配置。 您可以使用AWS估计器来计算资源成本。
The total cost for our configuration is around 2,300 USD (annual); with a monthly payout of ~200 USD
我们的配置总费用约为2,300美元(每年); 每月支出约200美元

翻译自: https://towardsdatascience.com/building-a-cloudformation-stack-from-scratch-691ea3a71571

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









