





bert nlp
内置AI NLP365(INSIDE AI NLP365)
Project #NLP365 (+1) is where I document my NLP learning journey every single day in 2020. Feel free to check out what I have been learning over the last 262 days here. At the end of this article, you can find previous papers summary grouped by NLP areas :)
项目#NLP365(+1)是我记录我的NLP的学习之旅的每一天在2020年随时检查出什么,我一直在学习,在过去262天这里。 在本文的结尾,您可以找到按NLP领域分组的以前的论文摘要:)
Today’s NLP paper is Applying BERT to Document Retrieval with Birch. Below are the key takeaways of the research paper.
今天的NLP论文正在将BERT应用于Birch的文档检索中。 以下是研究论文的主要内容。
目标与贡献 (Objective and Contribution)
Birch, a proposed system that uses BERT for document retrieval. It is integrated with Anserini information retrieval toolkit to bring the full end-to-end document retrieval over large document collections.
Birch,使用BERT进行文档检索的建议系统。 它与Anserini信息检索工具包集成在一起,可以对大型文档集合进行完整的端到端文档检索。
Document retrieval is where given a large document collections D, the systems should return a set of ranked documents based on the user’s query Q. Lucene (and Solr and Elasticsearch) are the main platforms for building search engine in the industry. However, there exist a technical challenge when it comes to connecting the NLP with IR, whereby Lucene is implemented in Java, however, most deep learning techniques are implemented in Python with a C++ backend.
在有大量文档集合D的文档检索中,系统应基于用户的查询Q返回一组已排序的文档。Lucene(以及Solr和Elasticsearch)是构建行业搜索引擎的主要平台。 但是,在将NLP与IR连接时,存在一个技术挑战,即Lucene是在Java中实现的,但是,大多数深度学习技术是在带有C ++后端的Python中实现的。
桦木 (Birch)
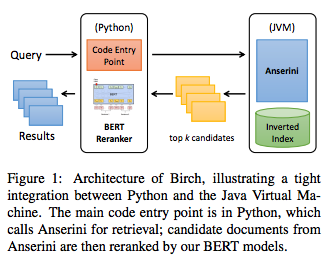
The architecture of Birch consists of two stages:
桦木的体系结构包括两个阶段:
- Retrieval using Anserini 使用Anserini进行检索
- Reranking using BERT-based model使用基于BERT的模型进行排名
Python is the code entry point and it’s integrated with Anserini using Pyjnuis library to access Java classes. Overall, the Python is the main development language, connecting to Java Virtual machine (JVM) backend for retrieval.
Python是代码的入口点,它使用Pyjnuis库与Anserini集成在一起以访问Java类。 总体而言,Python是主要的开发语言,它连接到Java虚拟机(JVM)后端进行检索。
We finetuned BERT for relevance classification over text. Given document D and query Q, we concatenated them into the following text sequence: [CLS] + Q + [SEP] + D + [SEP]. With each mini-batch, we pad the sequence to N tokens, where N is the maximum length token in the batch. As usual, the [CLS] token is feed into an one-layer neural network. One problem is that BERT is not designed for long document inference and so we decided to do inference at the sentence level for each document and aggregate the sentence-level inference for ranking documents. Previous work found that the best scoring sentence within a document provides a good proxy for document relevance.
我们针对文本的相关性分类对BERT进行了微调。 给定文档D和查询Q,我们将它们分为以下文本序列:[CLS] + Q + [SEP] + D + [SEP]。 对于每个小批量,我们将序列填充到N个令牌中,其中N是批次中的最大长度令牌。 与往常一样,[CLS]令牌被馈送到一层神经网络中。 一个问题是BERT不是为长文档推理而设计的,因此我们决定在每个文档的句子级别进行推理,并为排名文档汇总句子级别的推理。 先前的工作发现,文档中评分最高的句子可以很好地说明文档的相关性。
检索结果 (Retrieval Results)
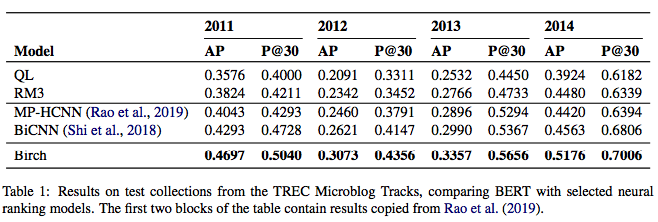
There are two evaluation datasets: TREC 2011–2014 Microblog Tracks and TREC 2004 Robust Track. For the microblog tracks, Birch is applied to a set of tweets. Query likelihood and RM3 relevance feedback was used to retrieve an initial set of candidates (around 100) and BERT was used to inference over the whole candidate document (since it’s short, BERT can cover the whole document rather than sentence-level aggregation). The results are as shown below. The two common evaluation metrics for retrieval are average precision (AP) and precision @ rank 30 (P@30). As shown, Birch yielded a strong improvement in each year over the baseline and advanced neural models.
有两个评估数据集:TREC 2011–2014微博跟踪和TREC 2004健壮跟踪。 对于微博,Birch应用于一组推文。 使用查询似然和RM3相关性反馈来检索初始候选集(大约100个),并使用BERT推断整个候选文档(因为简短,BERT可以覆盖整个文档而不是句子级聚合)。 结果如下。 用于检索的两个常见评估指标是平均精度(AP)和30级精度(P @ 30)。 如图所示,与基准和高级神经模型相比,伯奇每年都取得了很大的进步。
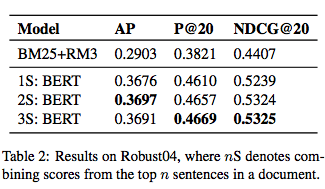
The robust track consists of newswire articles for document retrieval task. The additional challenge with this dataset is that there aren’t enough data to fine-tune our BERT models, since relevance labels are at the document level. The surprising finding of previous work is that BERT models fine-tuned with the microblog tracks work well with ranking the newswire articles despite both datasets are in different domains. BERT was able to learn to model relevance at the sentence-level across different domains and this has shown to be useful for ranking newswire articles. For the robust track, we fine-tune BERT with MS MARCO and then with microblog data and the results are shown below. We combine scores from BERT with document scores (BM25 + RM3). 1S — 3S refer to aggregating scores from top 1–3 sentences. Overall, the results show us that we can accurate rank documents by predicting its relevance at the sentence-level.
健壮的轨道由新闻专线文章组成,用于文档检索任务。 该数据集的另一个挑战是,由于相关性标签位于文档级别,因此没有足够的数据来微调我们的BERT模型。 先前工作的令人惊讶的发现是,尽管两个数据集都在不同的域中,但通过微博跟踪进行微调的BERT模型可以很好地对新闻专线文章进行排名。 BERT能够学习在不同领域的句子级别建立关联性建模,这对于对新闻专线文章进行排名非常有用。 对于健壮的轨道,我们先用MS MARCO对BERT进行微调,然后再对微博客数据进行微调,结果如下所示。 我们将BERT的分数与文档分数(BM25 + RM3)相结合。 1S — 3S指的是前1-3个句子的综合得分。 总体而言,结果表明我们可以通过预测句子级别的相关性来对文档进行排名。
结论与未来工作 (Conclusion and Future Work)
Through sentence-level inference and score aggregation, this system architecture uses BERT to rank documents. We have successfully integrated PyTorch with Java Virtual Machine backend to allow researchers to work on code development in an environment that they are familiar with.
通过句子级别的推理和分数聚合,该系统架构使用BERT对文档进行排名。 我们已经成功地将PyTorch与Java虚拟机后端集成在一起,使研究人员可以在他们熟悉的环境中进行代码开发。
资源: (Source:)
[1] Yilmaz, Z.A., Wang, S., Yang, W., Zhang, H. and Lin, J., 2019, November. Applying BERT to document retrieval with birch. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations (pp. 19–24).
[1] Yilmaz,ZA,Wang,S.,Yang,W.,Zhang,H.和Lin,J.,2019年11月。 将BERT应用于桦木文档检索。 在《 2019年自然语言处理经验方法会议》和第9届国际自然语言处理联合会议(EMNLP-IJCNLP)的会议记录中:系统演示(第19-24页)。
Originally published at https://ryanong.co.uk on May 1, 2020.
最初于2020年5月1日发布在https://ryanong.co.uk 。
方面提取/基于方面的情感分析 (Aspect Extraction / Aspect-based Sentiment Analysis)
总结 (Summarisation)
其他 (Others)
bert nlp


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









