





模型偏差和方差
Have you ever wondered if there is a more systematic way of tuning your model, than blindly guessing the hyperparameters or using a grid search?
您是否曾经想过,是否有比盲目猜测超参数或使用网格搜索更系统的模型调整方法?
As data scientists, we often face a lot of decisions when building a model, such as which model to use, how big it should be, how much data is needed, how many features to add or whether to use or not use regularization. While some decisions can be evaluated relatively quickly, others such as gathering more data may take months, just to find out that it did not help.
作为数据科学家,我们在构建模型时经常面临很多决策,例如使用哪种模型,应该使用多大的模型,需要多少数据,要添加多少个功能或是否使用正则化。 尽管可以相对快速地评估某些决策,但是发现其他决策(例如收集更多数据)可能要花费几个月的时间,只是发现它没有帮助。
In this article, I would like to practically demonstrate an approach of making these decisions by looking at bias and variance, which changed the way I proceed in almost every project.
在本文中,我想通过观察偏见和差异来实际演示做出这些决策的方法,这改变了我在几乎每个项目中进行的方式。
实践中的偏差和方差 (Bias and Variance in Practice)
What many people do wrong when tuning their models, is they look solely on their validation error. While this is in the end the most important number (except for test error), looking simultaneously at the training error might give you several hints of where to go with your model.
许多人在调整模型时做错了什么,就是他们只看他们的验证错误。 虽然这是最重要的数字(测试错误除外),但同时查看训练错误可能会给您一些提示,说明使用模型的方法。
There might be different and more formal definitions of bias and variance, but what it practically comes to is that:
偏差和方差可能有不同且更正式的定义,但实际上是:
Bias is an error rate on your training set (1-training accuracy)
偏差是您的训练集上的错误率(1个训练精度)
Variance is a rate of how much worse is the model on validation set compared to training set (training accuracy-validation accuracy)
方差是验证集上的模型与训练集相比(训练准确性-验证准确性)差多少的比率
I will demonstrate the importance of these concepts with a practical example.
我将通过一个实际的例子来说明这些概念的重要性。
创建数据集 (Creating Dataset)
Let’s first create a dataset that we will use to train and evaluate our models.
首先,我们创建一个数据集,以用于训练和评估我们的模型。
I will do that using sklearn’s make_classification, and afterwards split the dataset into training and validation set.
我将使用sklearn的make_classification进行此操作,然后将数据集分为训练和验证集。
x, y = make_classification(n_samples=50000, n_features=100, n_redundant=0, n_informative=100,
n_clusters_per_class=1, n_classes=10, class_sep=0.5, flip_y=0.05)
train_x, val_x, train_y, val_y = train_test_split(x, y, test_size=0.1)方案1:高偏差,低方差(Scenario #1: High Bias, Low Variance)
Next, we will start off by creating a relatively small Neural Network using Keras, and training it on our dataset.
接下来,我们将使用Keras创建一个相对较小的神经网络,并在我们的数据集中对其进行训练。
model = Sequential()
model.add(Dense(16, input_dim=train_x.shape[1], activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_x, train_y, epochs=500, batch_size=512, validation_data=(val_x, val_y))The trained model gets the following result:
经过训练的模型获得以下结果:
Training accuracy: 62.83%
Validation accuracy: 60.12%
Bias: 37.17%
Variance: 2.71%We can see that our model has a very high bias, while having a relatively small variance. This state is commonly known as underfitting.
我们可以看到我们的模型具有很高的偏差,而方差相对较小。 这种状态通常称为欠拟合。
There are several methods to reduce bias, and get us out of this state:
有几种方法可以减少偏见,并使我们摆脱这种状态:
Increase model’s size
增加模型的尺寸
Add more features
添加更多功能
Reduce regularization
减少正则化
方案2:低偏差,高方差(Scenario #2: Low Bias, High Variance)
Let’s try the method of increasing model’s size to reduce bias, and see what will happen.
让我们尝试增加模型大小以减少偏差的方法,然后看看会发生什么。
In order to do that, I increased the number of neurons in every hidden layer.
为了做到这一点,我增加了每个隐藏层中神经元的数量。
model = Sequential()
model.add(Dense(256, input_dim=train_x.shape[1], activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_x, train_y, epochs=500, batch_size=512, validation_data=(val_x, val_y))Our bigger model gets the following result:
我们更大的模型得到以下结果:
Training accuracy: 100.0%
Validation accuracy: 89.82%
Bias: 0.0%
Variance: 10.18%As you can see, we have successfully reduced the model’s bias. Actually, we have completely eliminated it, however, the variance has increased now. This state is commonly known as overfitting.
如您所见,我们已经成功减少了模型的偏差。 实际上,我们已经完全消除了它,但是现在差异增加了。 这种状态通常称为过拟合。
The methods to reduce variance of the model are:
减少模型方差的方法是:
Decrease model’s size
减小模型尺寸
Decrease number of features
减少功能数量
Add regularization
添加正则化
Add more data
添加更多数据
方案3:低偏差,低方差(Scenario #3: Low Bias, Low Variance)
Let’s this time try to reduce variance by introducing some regularization to our model.
这次让我们尝试通过对模型引入一些正则化来减少方差。
I added the regularization to every layer in a form of Dropout (randomly ignoring a set of neurons during training).
我以Dropout的形式在每一层中添加了正则化(在训练过程中随机忽略了一组神经元)。
model = Sequential()
model.add(Dense(256, input_dim=train_x.shape[1], activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_x, train_y, epochs=500, batch_size=512, validation_data=(val_x, val_y))The result of our new model is:
我们新模型的结果是:
Training accuracy: 98.62%
Validation accuracy: 95.16%
Bias: 1.38%
Variance: 3.46%Perfect! We are now very close to an optimal state with relatively low bias as well as relatively low variance, which is exactly what we were aiming for. If we now look at our validation error (1-validation accuracy or bias+variance), it is the lowest it has been so far.
完善! 现在,我们非常接近具有相对较低的偏差以及相对较低的方差的最佳状态,这正是我们的目标。 现在,如果我们查看验证错误(1-验证准确性或偏差+方差),则它是迄今为止的最低值。
Maybe you have noticed that in the last scenario, the bias has increased a bit again, compared to the scenario #2. You can also see that the methods for reducing bias and reducing variance are the exact opposites. This property is called Bias–Variance Tradeoff, and is demonstrated in the following graph:
也许您已经注意到,在第二种情况下,与第二种情况相比,偏差再次增加了一点。 您还可以看到,减少偏差和减少方差的方法正好相反。 此属性称为“偏差-偏差权衡” ,并在下图中进行了演示:
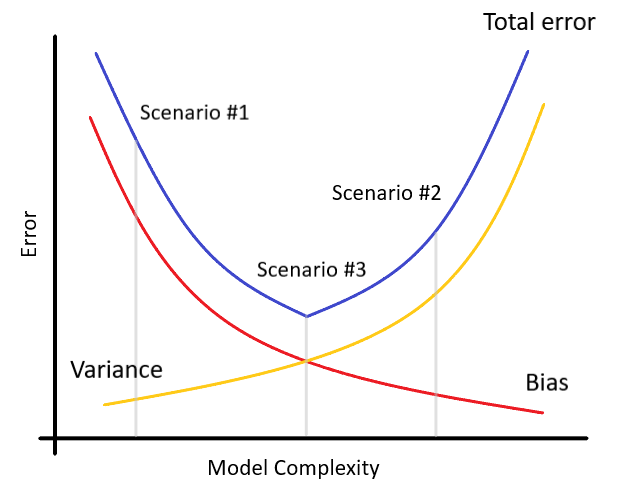
Basically, we are trying find a balance between bias and variance, that minimizes the total error.
基本上,我们试图在偏差和方差之间找到一个平衡点,以使总误差最小。
结论 (Conclusion)
We went through 3 different scenarios of tuning the model based on bias and variance, and the corresponding steps that could be taken.
我们经历了3种不同的基于偏差和方差调整模型的场景,以及可以采取的相应步骤。
There potentially exists a 4th scenario of having both high bias and high variance, which has not been covered. However, this usually means that there is something wrong with your data (training and validation distribution mismatch, noisy data etc.), and therefore, it is difficult to give you an exact guideline.
可能存在同时具有高偏差和高方差的第四种情况,但尚未涵盖。 但是,这通常意味着您的数据有问题(训练和验证分布不匹配,嘈杂的数据等),因此很难为您提供准确的指导。
I hope that this approach will help you with prioritizing tasks in your projects, and in the end save you some time.
我希望这种方法将帮助您确定项目中任务的优先级,并最终节省您一些时间。
All the code that I used can be found on GitHub.
Inspired by Machine Learning Yearning by Andrew Ng.
模型偏差和方差

















 2723
2723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









