





 本文介绍了一种使用词嵌入概念来计算项目相似度的方法,主要应用于推荐系统中。通过生成项目语料库和项目嵌入,利用Item2vec生成非零向量表示项目,最后采用余弦相似度计算项目间相似度。
本文介绍了一种使用词嵌入概念来计算项目相似度的方法,主要应用于推荐系统中。通过生成项目语料库和项目嵌入,利用Item2vec生成非零向量表示项目,最后采用余弦相似度计算项目间相似度。
相似度计算计算
As a keen learner of Machine Learning, I’ve always been curious about different approaches of building an intelligent system. I firmly do believe that ‘Machine Learning as a field’ expects us to explore and try different approaches that might not have gained any recognition before. Since my areas of interest are Recommendation System, NLP(Natural Language Processing) and Programming, I’ve got to coalesce these areas and come up with some unique approaches.
作为机器学习的敏锐学习者,我一直对构建智能系统的不同方法感到好奇。 我坚信“机器学习作为一个领域”期望我们探索并尝试以前未获得任何认可的不同方法。 由于我感兴趣的领域是推荐系统,NLP(自然语言处理)和编程,因此我必须合并这些领域并提出一些独特的方法。
There are various methods for building a recommendation system and when we get along with building one, we’ll eventually find that items need to be compared at some point. Since finding items similarities with Item based collaborative filtering has probably been hackneyed, I’ve tied the concept of NLP & Recommendation System to find items similarities.
建立推荐系统的方法多种多样,当我们与推荐系统建立关系时,我们最终会发现需要对项目进行比较。 由于使用基于项目的协作过滤来查找项目相似性可能是很老套的,因此,我将NLP和推荐系统的概念用于查找项目相似性。
使用词嵌入作为基本概念 (Using word embeddings as a base concept)
I assume that you’re familiar with word embeddings, if not click on the link below or else be ok with lifting a burden of regret your entire life.
我假设您熟悉单词嵌入,如果不单击下面的链接,或者可以减轻一生的负担。
If you’ve read the article, you can see that word embeddings are generated by training a neural network on a corpus (sequence of words). Aligning this very concept, we can find item embeddings in the same way. I will be explaining the approach below.
如果您已阅读本文,则可以看到单词嵌入是通过在语料库(单词序列)上训练神经网络而生成的。 结合这个概念,我们可以以相同的方式找到项目嵌入。 我将在下面解释该方法。
如何生成项目嵌入? (How item embeddings are generated?)
Step 1:- Generation of Item Corpus
步骤1:生成项目语料库
A user interaction forms a sequence over time, which is indicated by Hn = {X1, X2, . . . , Xn}. Xn denotes the items. So, the combination of interaction patterns of different users forms a long sequence (item corpus), denoted by S = {H1, H2, H3, . . . , Hn }, where n indicates the number of users.
用户交互随时间形成序列,由Hn = {X1,X2,.. 。 。 ,Xn} 。 Xn表示项目。 因此,不同用户的交互模式的组合形成了一个长序列( 项目语料库 ),表示为S = {H1,H2,H3,...。 。 。 ,Hn} ,其中n表示用户数。
Let us take a video streaming website like YouTube as a reference. Consider a user visits the site and certainly over time the interaction of the user forms a sequence of videos. Likewise many users form many sequences. Eventually upon broader projection, we can retrieve many such sequences and the merger of these sequences gives ‘item corpus’ like ‘word corpus’ in word embeddings.
让我们以YouTube之类的视频流网站作为参考。 考虑到用户访问该站点,并且随着时间的流逝,用户的互动肯定会形成一系列视频。 同样,许多用户形成许多序列。 最终,在更广泛的预测下,我们可以检索到许多这样的序列,并且这些序列的合并在单词嵌入中提供了“项目语料库”,例如“单词语料库” 。
Step 2:- Generation of item embeddings
步骤2:-生成项目嵌入
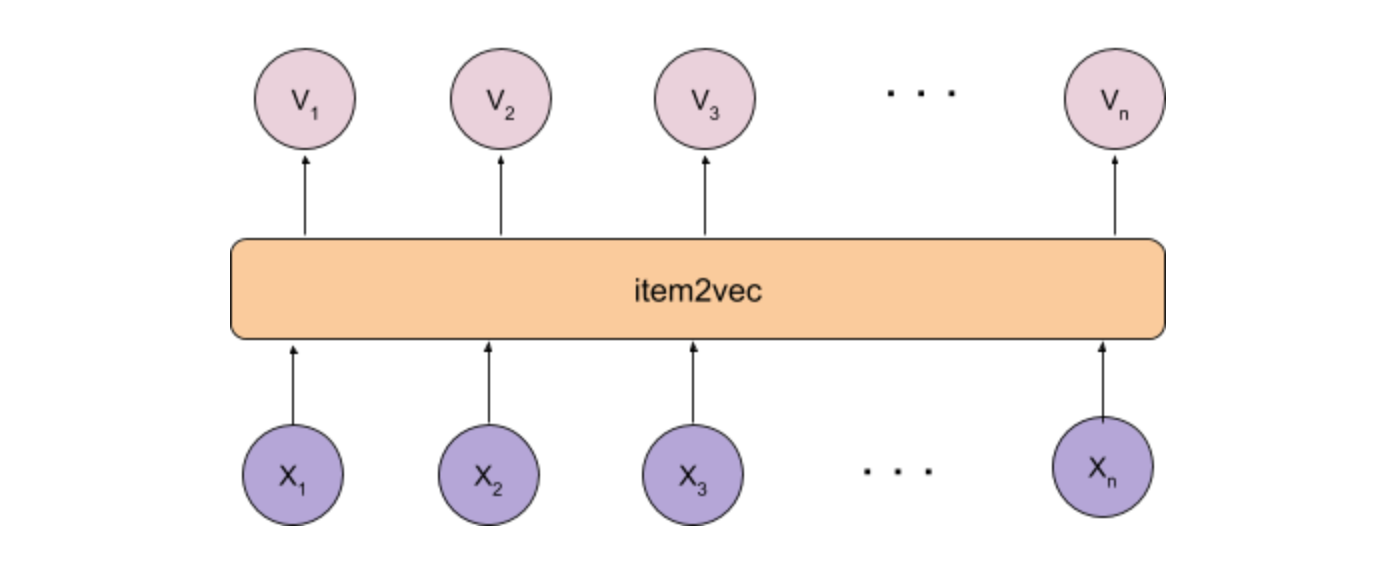
So, we have item corpus like word corpus for word embeddings. Assuming that the above mentioned article has been read, I hope you’re clear about how word embeddings are generated from the word corpus.
因此,我们有词库,例如词库,用于词嵌入。 假设已经阅读了上面提到的文章,希望您对从语料库中生成词嵌入的情况有所了解。
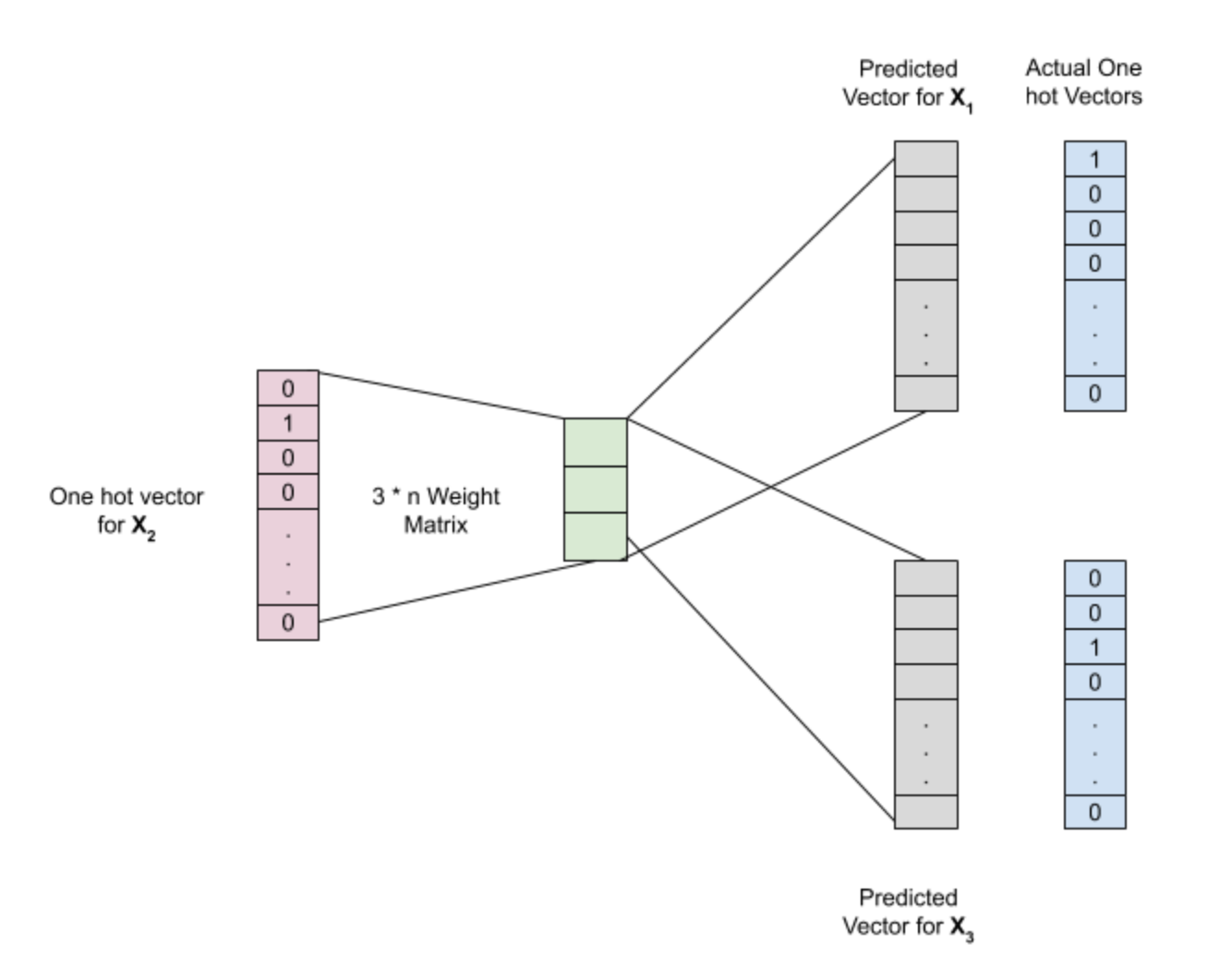
To generate item embeddings, the items are initially represented as one-hot vectors. But, one-hot vectors do not define the similarities between items. To find similarity between any two items, the items have to be represented as non-zero vectors. Item2vec is used to generate those non-zero vectors.
为了生成项目嵌入,最初将项目表示为单热点向量。 但是,一键向量无法定义项目之间的相似性。 为了找到任何两个项目之间的相似性,这些项目必须表示为非零向量。 Item2vec用于生成那些非零向量。
项目之间的相似度如何计算? (How similarity between items is calculated?)
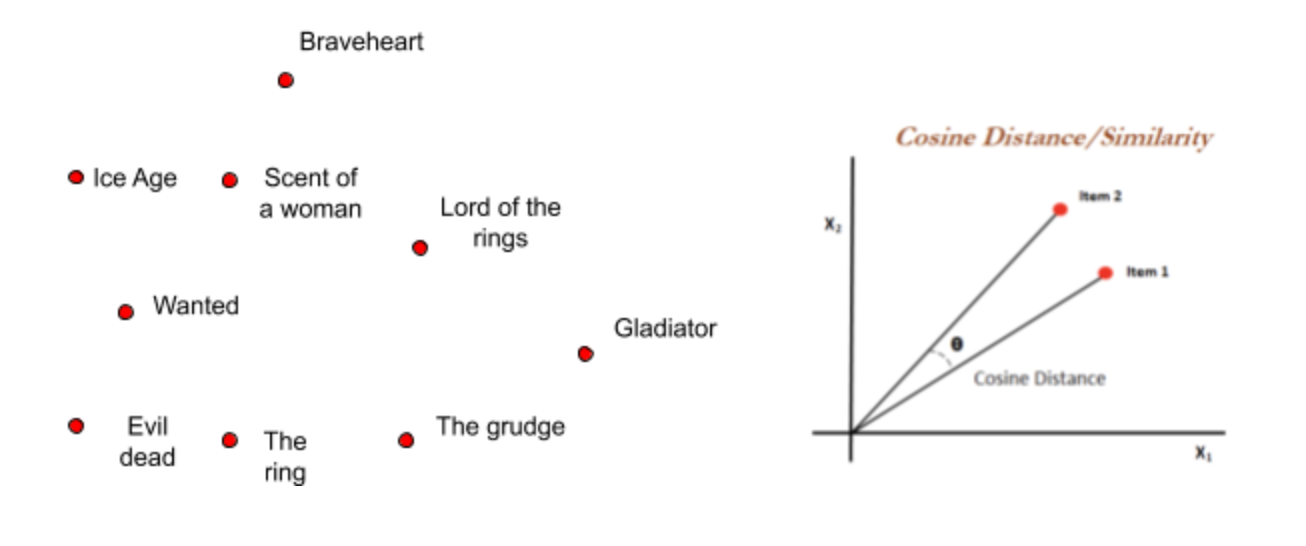
After item embeddings are calculated, we have to use them in various ways. We’re not leading them to a desolation for sure. So, how do we calculate similarity between any two items? The magic word is ‘Cosine Similarity’.
计算项目嵌入后,我们必须以各种方式使用它们。 我们不能肯定会导致他们荒凉。 那么,我们如何计算任意两个项目之间的相似度? 神奇的词是“余弦相似度” 。
Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space
余弦相似度是内积空间的两个非零向量之间相似度的度量
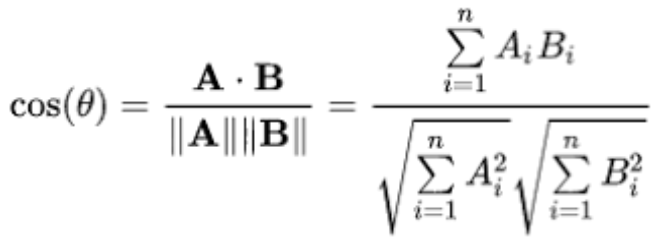
结论 (Conclusion)
One of the approaches for finding items similarities is using the concept of word embeddings as a base concept. There are probably a lot of other methods which certainly are unique and unfamiliar to people like us. So the optimal thing we can do is read different resources and share them on a platform 😁.
查找项目相似性的方法之一是使用词嵌入的概念作为基本概念。 可能还有很多其他方法对于像我们这样的人当然是独特且不熟悉的。 因此,我们可以做的最佳事情是读取不同的资源并在平台上共享它们。
Keep Learning, Keep Sharing!
不断学习,不断分享!
翻译自: https://medium.com/swlh/calculate-item-similarity-d7a6255c912d
相似度计算计算

















 9403
9403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









