





 本文介绍了如何在RL算法中利用动作屏蔽技术提高学习效率和优化策略。通过在背包问题(KP环境)中应用动作屏蔽,可以避免无效的随机尝试,加快学习过程。文章详细展示了如何在RLlib中构建自定义模型来实现动作屏蔽,从而在训练过程中强制执行约束,防止代理执行非法动作。实验表明,动作屏蔽能有效地帮助代理跳出局部最优解,找到更好的策略。
本文介绍了如何在RL算法中利用动作屏蔽技术提高学习效率和优化策略。通过在背包问题(KP环境)中应用动作屏蔽,可以避免无效的随机尝试,加快学习过程。文章详细展示了如何在RLlib中构建自定义模型来实现动作屏蔽,从而在训练过程中强制执行约束,防止代理执行非法动作。实验表明,动作屏蔽能有效地帮助代理跳出局部最优解,找到更好的策略。
RL algorithms learn via trial and error. The agent searches the state space early on and takes random actions to learn what leads to a good reward. Pretty straightforward.
RL算法通过反复试验学习。 代理尽早搜索状态空间,并采取随机动作以了解导致良好奖励的原因。 非常简单。
Unfortunately, this isn’t terribly efficient, especially if we already know something about what makes a good vs. bad action in some states. Thankfully, we can use action masking — a simple technique that sets the probability of bad actions to 0 — to speed learning and improve our policies.
不幸的是,这并不是非常有效,特别是如果我们已经知道在某些州什么是好事还是坏事的事。 值得庆幸的是,我们可以使用行为屏蔽 (一种将不良行为的概率设置为0的简单技术)来加快学习速度并改善我们的政策。
TL; DR (TL;DR)
We enforce constraints via action masking for a knapsack packing environment and show how to do this using RLlib.
我们针对背包包装环境通过动作屏蔽强制实施约束,并展示如何使用RLlib做到这一点 。
强制约束 (Enforcing Constraints)
Let’s use the classic knapsack problem to develop a concrete example.
让我们使用经典的背包问题来开发一个具体的例子。
The knapsack problem (KP) asks you to pack a knapsack to maximize the value in the bag without overloading it. If you have a collection of items like we have shown below, the optimal packing is going to contain three of the yellow boxes and three of the gray boxes for a total of $36 and 15kg (this is the unbounded knapsack problem because you have no limit on how many boxes you can choose).
背包问题(KP)要求您打包一个背包以使袋子中的物品价值最大化而又不会使背包过载。 如果您有如下所示的物品集合,则最佳包装将包含三个黄色盒子和三个灰色盒子,总计36美元和15公斤(这是无限制背包问题,因为您没有限制)您可以选择多少个盒子)。
Typically, this problem is solved using dynamic programming or math programming. If we set it up following a math program, we can write out the model as follows:
通常,使用动态编程或数学编程可以解决此问题。 如果按照数学程序进行设置,则可以按如下所示编写模型:

In this case, x_i is can be any value ≥0 and symbolizes the number of items i we place into the knapsack. v_i and w_i, are the values and weights of the items respectively.
在这种情况下, x_i可以是≥0的任何值,并表示我放入背包的物品数量。 v_i和w_i分别是项目的值和权重。
In plain language, this small model is saying we want to maximize the value in the knapsack (which we call z). We do this by finding the largest number of items (x_i) and their values (v_i) without exceeding the weight limit of the knapsack (W). This formulation is known as an Integer Program (IP) because we have integer decision variables (we can’t pack parts of items, just full, integer values) and is solved using a solver like CPLEX, Gurobi, or GLPK (the last one is free and open source).
用简单的语言来说,这个小模型表示我们要最大化背包(我们称之为z )中的值。 我们寻找项目的数量最多(X_I)和它们的值(V-I)不超过限重的背包(W)的做到这一点。 这种公式称为整数程序(IP),因为我们有整数决策变量(我们不能打包部分项目,而只能打包完整的整数值),并使用CPLEX,Gurobi或GLPK之类的求解器进行求解(最后一个是免费和开源的)。
Enforcing those constraints are built into the model, but it’s not naturally built into RL. The RL model may need to pack the green, 12kg box a few times before learning that it can’t pack that and the yellow, 4kg box, by getting hit with a large, negative reward a few times. The negative reward for over packing is a “soft constraint” because we aren’t explicitly forbidding the algorithm from making these bad decisions. But, if we use action masking, we can ensure that the model doesn’t make dumb choices, which will also help it learn better policies, faster.
强制将这些约束内置于模型中,但是自然不会内置于RL中。 RL模型可能需要包装几次绿色的12公斤重的盒子,然后才知道它不能包装它,而黄色的4千克重的盒子会受到几次较大的负面奖励的打击。 过度打包的负面奖励是“软约束”,因为我们没有明确禁止算法做出这些错误的决定。 但是,如果我们使用动作屏蔽,则可以确保模型不会做出愚蠢的选择,这也将帮助它更快地学习更好的策略。
KP环境 (The KP Environment)
Let’s put this into action by packing a knapsack using the or-gym library, which contains some classic environments from the operations research field that we can use to train RL agents. If you’re familiar with OpenAI Gym, you’ll use this in the same way. You can install it with pip install or-gym.
让我们通过使用or-gym库打包背包来实施此操作,该库包含运筹学领域的一些经典环境,可用于训练RL代理。 如果您熟悉OpenAI Gym,将以相同的方式使用它。 您可以使用pip install or-gym安装它。
Once that’s installed, import it and build the Knapsack-v0 environment, which is the unbounded knapsack problem we described above.
安装完成后,将其导入并构建Knapsack-v0环境,这是我们上面描述的无限的背包问题。
import or_gym
import numpy as np
env = or_gym.make('Knapsack-v0')The default settings for this environment has 200 different items to choose from and has a maximum weight capacity of 200kg.
该环境的默认设置有200种不同的项目可供选择,最大承重量为200kg。
print("Max weight capacity:\t{}kg".format(env.max_weight))
print("Number of items:\t{}".format(env.N))[out]
Max weight capacity: 200kg
Number of items: 200This is fine, but 200 items are a little much to see clearly, so we can pass an env_config dictionary to change some of these parameters to match the example above. Additionally, we can turn action masking on and off by passing mask: True or mask: False to the configuration dictionary.
很好,但是要看清楚200个项目,因此我们可以传递env_config字典来更改其中一些参数以匹配上面的示例。 另外,我们可以通过向配置字典传递mask: True或mask: False来打开和关闭动作屏蔽。
env_config = {'N': 5,
'max_weight': 15,
'item_weights': np.array([1, 12, 2, 1, 4]),
'item_values': np.array([2, 4, 2, 1, 10]),
'mask': True}env = or_gym.make('Knapsack-v0', env_config=env_config)print("Max weight capacity:\t{}kg".format(env.max_weight))
print("Number of items:\t{}".format(env.N))[out]
Max weight capacity: 15kg
Number of items: 5Now our environment matches the example above. Let’s look at our state briefly.
现在我们的环境与上面的示例匹配。 让我们简要地看一下我们的状态。
env.state[out]
{'action_mask': array([1, 1, 1, 1, 1]),
'avail_actions': array([1., 1., 1., 1., 1.]),
'state': array([ 1, 12, 2, 1, 4, 2, 4, 2, 1, 10, 0])}When we set the action mask option to True, we get a dictionary output as the state that contains three entries, action_mask, avail_actions, and state. This is the same format for all environments in the or-gym library. The mask is a binary vector where 1 indicates an action is allowed and 0 indicates it is going to break some constraint. In this case, our only constraint is the weight, so if a given item would push the model over weight, it is going to receive a large, negative penalty.
当将action mask选项设置为True ,我们将得到一个字典输出作为包含三个条目的状态,分别是action_mask , avail_actions和state 。 对于or-gym库中的所有环境,这都是相同的格式。 掩码是一个二进制向量,其中1表示允许执行操作,0表示将要打破某些约束。 在这种情况下,我们的唯一约束是权重,因此,如果给定的项目会使模型超过权重,则它将收到较大的负惩罚。
The available actions correspond to each of the five items the agent can select for packing. The state is the input that gets passed to the neural network. In this case, we have a vector that has concatenated the item weights and values, and has the current weight tacked on the end (0 when you initialize the environment).
可用操作对应于代理可以选择打包的五个项目中的每一个。 状态是传递到神经网络的输入。 在这种情况下,我们有一个向量,该向量已将项目的权重和值连接在一起,并在最后加上了当前权重(初始化环境时为0)。
If we go ahead and select the 12kg item to pack, we should see that action mask update to eliminate packing any other item that puts the model over the weight limit.
如果继续并选择要包装的12kg物品,则应该看到防毒面具已更新,可以消除包装使模型超出重量限制的任何其他物品。
state, reward, done, _ = env.step(1)
state{'action_mask': array([1, 0, 1, 1, 0]),
'avail_actions': array([1., 1., 1., 1., 1.]),
'state': array([ 1, 12, 2, 1, 4, 2, 4, 2, 1, 10, 12])}If you look at the action_mask, that's exactly what we see. The environment is returning information that we can use to prevent the agent from selecting either the 12kg or the 4kg item because it will violate our constraint.
如果您看一下action_mask ,那正是我们所看到的。 环境返回的信息可用于阻止代理选择12kg或4kg物品,因为这将违反我们的约束。
The concept here is really straightforward to apply. After you complete the forward pass through your policy network, you use the mask to update the values for the illegal actions so that they become large, negative numbers. That way, when you pass it through the softmax function, the probabilities associated with these are going to be 0.
这里的概念确实很容易应用。 在通过策略网络完成前向传递之后,您可以使用掩码来更新非法操作的值,以使它们变为大的负数。 这样,当您将其传递给softmax函数时,与此相关的概率将为0。
Now, let’s turn to using RLlib to train a model to respect these constraints.
现在,让我们转向使用RLlib训练模型以遵守这些约束。
RLlib中的动作屏蔽 (Action Masking in RLlib)
Action masking in RLlib requires building a custom model that handles the logits directly. For a custom environment with action masking, this isn’t as straightforward as I’d like, so I’ll walk you through it step-by-step.
RLlib中的操作屏蔽要求构建一个直接处理logit的自定义模型。 对于具有动作遮罩的自定义环境,这并不是我想要的那么简单,因此,我将逐步指导您完成操作。
There are a lot of pieces we’re going to need to import first. ray and our ray.rllib.agents should be obvious if you're familiar with the library, but we'll also need tune, gym.spaces, ModelCatalog, a Tensorflow or PyTorch model (depending on your preference, for this I'll just stick to TF), and a utility in the or_gym library called create_env that we wrote to make this a bit smoother.
我们首先需要导入很多零件。 如果您熟悉该库, ray和ray.rllib.agents应该很明显,但是我们还需要tune , gym.spaces , ModelCatalog ,Tensorflow或PyTorch模型(取决于您的偏好,为此,坚持使用TF),然后在or_gym库中创建一个名为create_env的实用程序,我们对此进行了编写以使其更加流畅。
import ray
from ray.rllib import agents
from ray import tune
from ray.rllib.models import ModelCatalog
from ray.rllib.models.tf.tf_modelv2 import TFModelV2
from ray.rllib.models.tf.fcnet import FullyConnectedNetwork
from ray.rllib.utils import try_import_tf
from gym import spaces
from or_gym.utils import create_envtf = try_import_tf()建立自定义模型 (Building a Custom Model)
We need to tell our neural network explicitly how to handle the different values in our state dictionary. For this, we’ll build a custom model based on the TFModelV2 module from RLlib. This will enable us to build a custom model class and add a forward method to the model in order to use it. Within the forward method, we apply the masks as shown below:
我们需要明确地告诉神经网络如何处理状态字典中的不同值。 为此,我们将基于TFModelV2模块构建自定义模型。 这将使我们能够构建自定义模型类,并向模型添加一个forward方法以使用它。 在forward方法中,我们应用如下所示的蒙版:
class KP0ActionMaskModel(TFModelV2):
def __init__(self, obs_space, action_space, num_outputs,
model_config, name, true_obs_shape=(11,),
action_embed_size=5, *args, **kwargs):
super(KP0ActionMaskModel, self).__init__(obs_space,
action_space, num_outputs, model_config, name,
*args, **kwargs)
self.action_embed_model = FullyConnectedNetwork(
spaces.Box(0, 1, shape=true_obs_shape),
action_space, action_embed_size,
model_config, name + "_action_embedding")
self.register_variables(self.action_embed_model.variables()) def forward(self, input_dict, state, seq_lens):
avail_actions = input_dict["obs"]["avail_actions"]
action_mask = input_dict["obs"]["action_mask"]
action_embedding, _ = self.action_embed_model({
"obs": input_dict["obs"]["state"]})
intent_vector = tf.expand_dims(action_embedding, 1)
action_logits = tf.reduce_sum(avail_actions * intent_vector,
axis=1)
inf_mask = tf.maximum(tf.log(action_mask), tf.float32.min)
return action_logits + inf_mask, state def value_function(self):
return self.action_embed_model.value_function()To walk through this, we first initialize the model and pass our true_obs_shape, which is going to match the size of the state. If we stick with our reduced KP, that will be a vector with 11 entries. The other value we need to provide is the action_embed_size, which is going to be the size of our action space (5). From here, the model initializes a FullyConnectedNetwork based on the input values we provided and registers these values.
为了解决这个问题,我们首先初始化模型并传递true_obs_shape ,它将与state的大小匹配。 如果我们坚持降低的KP,那将是一个包含11个条目的向量。 我们需要提供的另一个值是action_embed_size ,它将是我们的操作空间(5)的大小。 在此,模型根据我们提供的输入值初始化FullyConnectedNetwork并注册这些值。
The actual masking takes place in the forward method where we unpack the mask, actions, and state from the observation dictionary provided by our environment. The state yields our action embeddings which gets combined with our mask to provide logits with the smallest value we can provide. This will get passed to a softmax output which will reduce the probability of selecting these actions to 0, effectively blocking the agent from ever taking these illegal actions.
实际的掩蔽发生在forward方法中,在此方法中,我们从环境提供的观察字典中解压缩了掩蔽,动作和状态。 该状态产生我们的动作嵌入,该嵌入与我们的掩码结合在一起,以提供可以提供的最小值的logit。 这将传递到softmax输出,该输出将把选择这些动作的可能性降低为0,从而有效地阻止代理执行这些非法动作。
Once we have our model in place, we need to register it with the ModelCatalog so RLlib can use it during training.
放置好模型后,我们需要在ModelCatalog注册它,以便RLlib可以在培训期间使用它。
ModelCatalog.register_custom_model('kp_mask', KP0ActionMaskModel)Additionally, we need to register our custom environment to be callable with RLlib. Below, I have a little helper function called register_env which we use to wrap our create_env function and tune's register_env function. Tune needs the base class, not an instance of the environment like we get from or_gym.make(env_name) to work with. So we need to pass this to register_env using a lambda function as shown below.
另外,我们需要注册我们的自定义环境,以便可以使用RLlib进行调用。 在下面,我有一个名为register_env的小帮手函数,该函数用于包装create_env函数和调优的register_env函数。 Tune需要基类,而不是环境的实例,就像我们从or_gym.make(env_name)获得的or_gym.make(env_name) 。 因此,我们需要使用lambda函数将此函数传递给register_env ,如下所示。
def register_env(env_name, env_config={}):
env = create_env(env_name)
tune.register_env(env_name, lambda env_name: env(env_name, env_config=env_config))
register_env('Knapsack-v0', env_config=env_config)Finally, we can initialize ray, and pass the model and setup to our trainer.
最后,我们可以初始化ray,并将模型和设置传递给我们的培训师。
ray.init(ignore_reinit_error=True)trainer_config = {
"model": {
"custom_model": "kp_mask"
},
"env_config": env_config
}
trainer = agents.ppo.PPOTrainer(env='Knapsack-v0', config=trainer_config)To demonstrate that our constraint works, we can mask a given action by setting one of the values to 0.
为了证明我们的约束有效,我们可以通过将值之一设置为0来屏蔽给定的动作。
env = trainer.env_creator('Knapsack-v0')
state = env.state
state['action_mask'][0] = 0We masked action 0, so we shouldn’t see the agent select 0 at all.
我们屏蔽了动作0,因此我们根本不会看到代理选择0。
actions = np.array([trainer.compute_action(state) for i in range(10000)])
any(actions==0)[out]
FalseAnd there we have it! We’ve successfully restricted our output with a custom model in RLlib to enforce constraints. You can use this same setup with tune as well to constrain the action space and provide parametric actions.
我们终于得到它了! 我们已经使用RLlib中的自定义模型成功限制了输出,以强制执行约束。 您也可以将同一设置与tune ,以约束动作空间并提供参数动作。
口罩工作 (Masks Work)
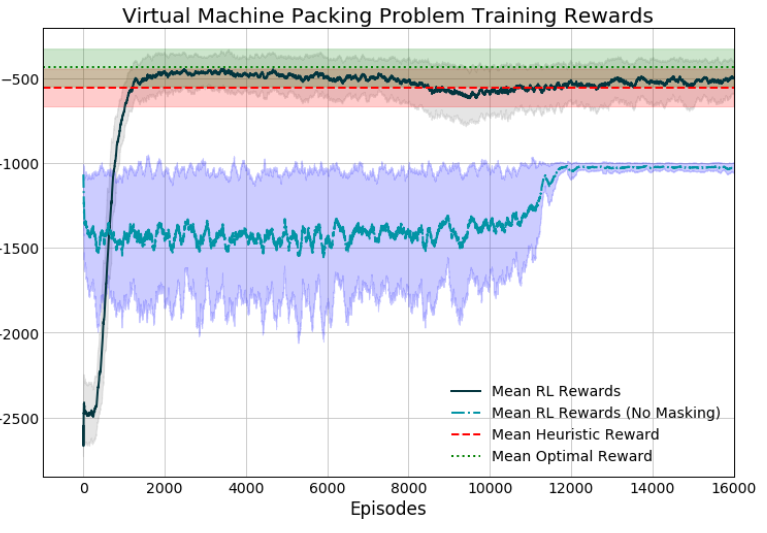
Masking can work very effectively to free an agent from pernicious local minima. Here, we built a virtual machine assignment environment for or-gym where the model with masking quickly found an excellent policy, while the model without masking got stuck in a local optima. We tried a lot with the reward function first to get it out of that rut, but nothing worked until we applied a mask!
屏蔽可以非常有效地使代理摆脱有害的本地最小值。 在这里,我们为 or-gym 构建了一个虚拟机分配环境,在该环境中,具有掩码的模型很快找到了一个很好的策略,而没有掩码的模型陷入了局部最优状态。 我们首先使用奖励功能进行了很多尝试,以使它脱离车辙,但是直到应用了遮罩,任何方法都无济于事!
翻译自: https://towardsdatascience.com/action-masking-with-rllib-5e4bec5e7505

















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









