





Condos have always fascinated me and in the city, I live, they are perhaps the first (or realistic) option that comes to the mind of many first-time home-buyers. Unless you have been living under a rock, you would be aware that house prices in Toronto have jumped manyfold over the last decade, and more so in the last 5 years. More recently, it has been the condo market that is on fire. So if you, like me, are looking for a condo to buy, you are in the right place.
公寓一直使我着迷,在我居住的城市中,它们也许是许多首次购房者想到的第一个(或现实的)选择。 除非您一直生活在一块岩石上,否则您会意识到多伦多的房价在过去十年中上涨了很多倍,在过去五年中上涨得更多。 最近,公寓市场火爆。 因此,如果您像我一样,正在寻找公寓购买,那么您来对地方了。
Being a highly data-driven person, I built a web-scraper tool that helps me analyze the condo prices in Toronto. My go-to website is Condos.ca. It has a good user interface and provides market intelligence (which I thought would be useful in validating my results). At the time of writing this article, it has listings spanning over 80 web pages, and I shall extract data from the first 50 pages as described later in the article.
作为一个高度数据驱动的人,我构建了一个网络爬虫工具,可以帮助我分析多伦多的公寓价格。 我的网站是Condos.ca 。 它具有良好的用户界面并提供市场情报(我认为这对验证我的结果很有用)。 在撰写本文时,它的清单跨越80个网页,我将按照本文后面所述从前50个页面中提取数据。
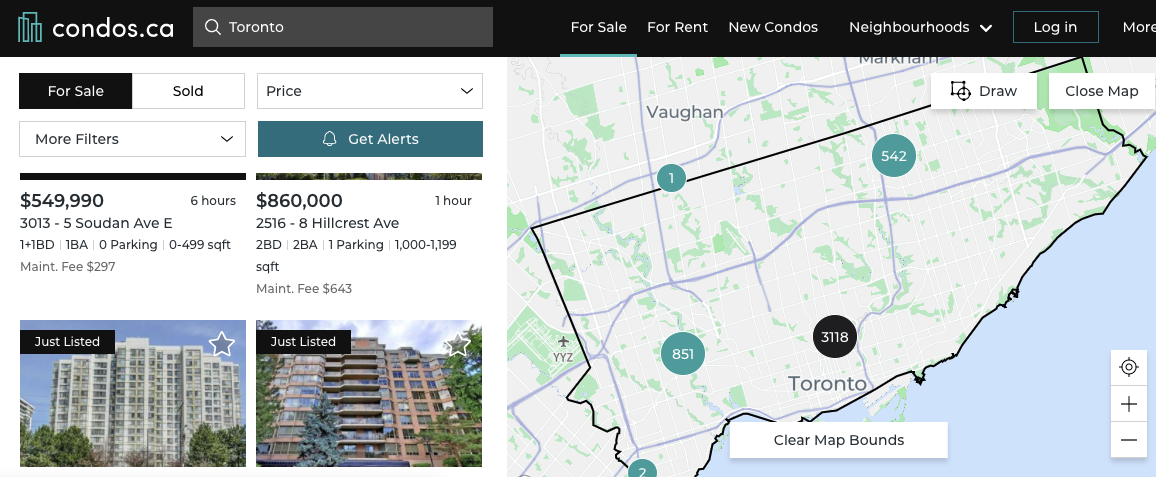
The objective of this undertaking was 2-fold:
该任务的目标是两个方面:
- To scrape essential data on relevant parameters from the website to build a benchmark database 从网站上刮取有关参数的基本数据以建立基准数据库
- To conduct market research by performing some exploratory EDA on the database such as average price per bedroom, average maintenance costs, average condo size, etc.通过在数据库上执行一些探索性EDA来进行市场研究,例如每间卧室的平ASP格,平均维护成本,平均公寓大小等。
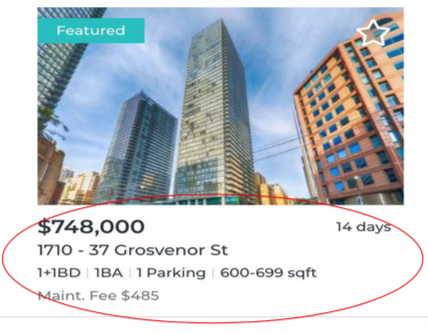
I extracted the information displayed on every listing such as the price, the street address, the number of bedrooms, bathrooms, whether it has parking or not, the size range and, the maintenance fees. (Note: Many other parameters affect condo prices such as the age of the building, property tax, Floor number, images, etc., but I have left these for simplicity)
我提取了每个清单上显示的信息,例如价格,街道地址,卧室,浴室的数量,是否有停车位,大小范围和维护费用。 (注意:许多其他参数会影响公寓价格,例如建筑物的使用期限,物业税,楼层编号,图像等,但为简单起见,我将其保留下来)
It’s worth mentioning here that I had limited to no experience with HTML before performing this exercise. But here lies the beauty of web scraping. You don’t need an advanced understanding of HTML. I simply learned how to extract the required value from the waterfall of tags within the HTML code. And the rest is all python! Here is a useful resource on how to scrape websites.
在这里值得一提的是,在进行本练习之前,我没有接触HTML的经验。 但是,这就是网页抓取的美妙之处。 您不需要对HTML有深入的了解。 我只是简单地学习了如何从HTML代码中的标签瀑布中提取所需的值。 其余的全部是python! 这是有关如何抓取网站的有用资源。
So let’s get started!
因此,让我们开始吧!
We begin by importing the necessary modules.
我们首先导入必要的模块。
from bs4 import BeautifulSoup # For HTML parsingfrom time import sleep # To prevent overwhelming the server between connectionsimport pandas as pd # For converting results to a dataframe and bar chart plots# For Visualizations
import matplotlib.pyplot as plt
import plotly.offline as py
import plotly.graph_objs as go%matplotlib inlineAs soon as I made the request to scrape the website, I ran into an error. This is because many websites try to block users from scraping any data and it may be illegal depending on what one plans to do with the data (I had however obtained permission from condos.ca). To navigate through this issue, I used an API called Selenium. It’s an API that allows you to programmatically interact with a browser the way a real user would. Although Selenium is primarily used to help test a web application, it can be used for any task where you need browser automation.
当我提出要求删除该网站的请求时,我遇到了一个错误。 这是因为许多网站试图阻止用户抓取任何数据,并且视一个人打算对数据进行何种处理,这可能是非法的(但是我已经获得condos.ca的许可)。 为了解决这个问题,我使用了一个称为Selenium的API。 这是一个API 允许您像真实用户一样通过编程方式与浏览器进行交互。 尽管Selenium主要用于帮助测试Web应用程序,但是它可以用于需要浏览器自动化的任何任务。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver.get(“https://condos.ca")Working with filters
使用过滤器
Running the previous code opens up a new browser and loads the website, and helps you interact with the website as if a real user would. For example, instead of manually clicking on the website to select filters such as the no. of bedrooms, or home type, or provide a price range, Selenium does that easily by passing in a couple of lines of command. The model gives the user the ability to select multiple filters.For example, to get 2 bedroom options, I use the following code to click on the button:
运行前面的代码将打开一个新的浏览器并加载网站,并像真实用户一样帮助您与网站进行交互。 例如,与其手动单击网站以选择诸如“否”之类的过滤器,不如单击它。 Selenium可以通过传递几行命令来轻松实现这一目标,例如卧室,家庭类型或价格范围。 该模型使用户能够选择多个过滤器。例如,要获得2个卧室的选项,我使用以下代码单击该按钮:
two_bed = driver.find_element_by_css_selector( ‘insert_css_path’)two_bed.click()Similarly, to get all the results with Gym, I simply use the following code:
同样,要使用Gym获得所有结果,我只需使用以下代码:
Gym = driver.find_element_by_css_selector('insert_css_path')
Gym.click()Defining a function to iterate over multiple pages
定义迭代多个页面的函数
Because I want to be able to do this analysis for other cities, I define a function that creates a beautiful soup object using parameters of ‘city’, ‘mode’, and ‘page no’. Here, the ‘mode’ parameter takes in ‘Sale’ or ‘Rent’ as values, giving the user the ability to analyze rental prices as well!
因为我希望能够对其他城市进行此分析,所以我定义了一个函数,该函数使用' city' ,' mode'和' page no'参数创建漂亮的汤对象。 在这里,“ mode”参数将“ Sale”或“ Rent”作为值,使用户也能够分析租金价格!
def get_page(city, mode, page):
url= f'https://condos.ca/{city}/condos-for-{mode}?mode= {mode}&page={page}'
driver.get(url)
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
return soupThe function utilizes the module called BeautifulSoup and returns an object called soup for a given webpage. It also loads up the requested webpage. (Later I shall iterate over all the webpages to extract the soup object for all pages)
该函数利用名为BeautifulSoup的模块,并为给定的网页返回一个称为汤的对象。 它还会加载请求的网页。 (稍后我将遍历所有网页以提取所有页面的汤对象)
Now that we have the soup object, we can extract some useful information such as the total number of listings, total listings per page, etc., by parsing through the webpage HTML. It’s not as difficult as it sounds! We use soup.find() to obtain the relevant tags. A useful approach is to start by extracting the data on the first page. If you can do that successfully, rest is simply iterating the process over all the pages!
现在我们有了汤对象,我们可以通过解析网页HTML来提取一些有用的信息,例如清单的总数,每页的清单总数等。 这并不像听起来那么困难! 我们使用soup.find()获得相关标签。 一种有用的方法是从提取第一页上的数据开始。 如果您可以成功完成此任务,那么剩下的就是简单地遍历所有页面的过程!
#Defining soup object for page 1
soup = get_page('toronto', 'Sale',1)Extracting some relevant information on listings from the first page.
从首页提取一些有关列表的信息。
- Total listings in Toronto : 多伦多的全部房源:
#The total number of Condo Listings in Torontosoup.find(‘div’,class_ = ‘sc-AxjAm dWkXrE’).find(‘span’,class_ = _5FYo1’).get_text() #no. of listings : 3560- The number of listings on the first page : 第一页上的列表数:
len(soup.find_all(‘div’,class_ = ‘_3O0GU’)) #43Now that we are a little comfortable with this, we can be a bit more ambitious and extract all the prices on page 1.
现在我们对此有所适应,我们可以更加雄心勃勃,并提取第1页上的所有价格。
prices=[]
for tag in soup.find_all(‘div’,class_ = ‘_2PKdn’):
prices.append(tag.get_text())
prices[:5]['$450,000',
'$649,900',
'$399,999',
'$599,900',
'$780,000']To make things simpler, I defined a variable called condo_container that would hold all the relevant data (price, location, size, etc.) of all the listings on a page
为简化起见,我定义了一个名为condo_container的变量,该变量将保存页面上所有列表的所有相关数据(价格,位置,大小等)。
condo_container = soup.find_all('div','_3SMhd')Now, all we have to do is extract price and other data from this condo_container. See the example below:
现在,我们要做的就是从此condo_container中提取价格和其他数据。 请参阅以下示例:
#Obtaining Location of all listings on page 1Location_list=[]
for i in range(len(condo_container)):
for tag in condo_container[i].find('span',class_='_1Gfb3'):
Location_list.append(tag)
Location_list[:5]['1001 - 19 Four Winds Dr',
'306 - 2 Aberfoyle Cres',
'911 - 100 Echo Pt',
'524 - 120 Dallimore Circ',
'1121 - 386 Yonge St']Rinse and repeat the above process for all variables and we got all the lists that we would need to construct a data-frame (see sample code below). The process gets a little bit tricky while trying to extract parameters such as bathrooms, size, and parking, etc owing to the HTML structure but with a little bit of effort, it can be done! (I am not sharing the complete code on purpose so as to avoid the reproduction of code).
冲洗并对所有变量重复上述过程,我们得到了构造数据框所需的所有列表(请参见下面的示例代码)。 由于HTML结构,在尝试提取参数(例如浴室,大小和停车位等)时,该过程有些棘手,但是可以花一点精力! (我不是故意共享完整的代码,以免复制代码)。
最终数据集 (Final Dataset)
Now that we have all the lists, we simply append them onto a dictionary called data defined below. Some of the tags get a little confusing but that’s because they have been formatted from string type to integer wherever required.
现在我们有了所有列表,我们只需将它们添加到下面定义的名为data的字典中。 有些标记有些混乱,但这是因为它们在需要时已从字符串类型格式化为整数。
data = {'Prices':[],
'Location':[],
'Date_listed':[],
'Bedrooms':[],
'Bathrooms':[],
'Maint_Fees':[],
'Size':[],
'Parking':[]
}final_list=[]
for page in range(50):
soup = get_page('toronto', 'Sale',page)
condo_container = soup.find_all('div','_3SMhd')
sleep(random())
print(page) for i in range(len(condo_container)):
listing = [] price_tag = condo_container[i].find('div',class_= '_2PKdn').get_text()
formatted_tag = int(price_tag.split('$')[1].replace(',',''))
data['Prices'].append(formatted_tag)
location_tag = condo_container[i].find('span',class_='_1Gfb3').get_text() data['Location'].append(location_tag) if maint_tag != '':
Maintenance_Fees = int(maint_tag.split('$') [1].replace(',',''))
data['Maint_Fees'].append(Maintenance_Fees)
else:
data['Maint_Fees'].append('error') for info_tag in condo_container[i].find('div',class_='_3FIJA'):
listing.append(info_tag)
final_list.append(listing)Once we have the dictionary ready, we convert it into a pandas data-frame for further processing and EDA. The resulting data-frame has 2031 rows.
准备好字典后,我们将其转换为熊猫数据框,以进行进一步处理和EDA。 产生的数据帧有2031行。
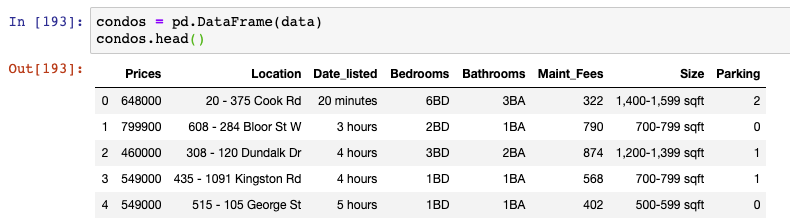
A quick look at the dataset tells us that Bedrooms, Bathrooms, Maintenance fees, and Size are object type variables because they had been stored as string type in the HTML.
快速浏览数据集可以发现,卧室,浴室,维护费和大小是对象类型变量,因为它们已作为字符串类型存储在HTML中。
These variables were cleaned and converted into an integer or float type. Moreover, I created a variable, Avg_Size from the Size variable. Through further data inspection, I found error values which I replaced with the mean of the respective columns. I also engineered a Street Address variable from the Location variable in case I want to perform some kind of location analysis later on. The dataset was treated for outliers, which were skewing my averages (expensive condos can get well expensive! ). The missing values were imputed with average or most occurring values in their respective columns.
这些变量被清除并转换为整数或浮点类型。 此外,我从Size变量创建了一个变量Avg_Size 。 通过进一步的数据检查,我发现了错误值,然后将其替换为各列的平均值。 我还从Location变量设计了Street Address变量,以防稍后要执行某种位置分析。 对数据集进行了离群值处理,这些值偏离了我的平均值(昂贵的公寓可能非常昂贵!)。 缺失值将在其各自的列中以平均值或大多数出现的值来估算。
Now, that our dataset looks nice and clean, we can go ahead with some basic exploratory analysis!
现在,我们的数据集看起来很干净,我们可以进行一些基本的探索性分析!
分析结果 (Analysis / Results)
I was curious, how the average price and size varied by the number of bedrooms, which I think would be the first thing on the mind of any buyer! So I created some plots using Plotly (see sample code below).
我很好奇,平ASP格和面积如何随卧室数量的变化而变化,我认为这将是任何买家的第一要意! 因此,我使用Plotly创建了一些图(请参见下面的示例代码)。
price_by_bed = condos.groupby(['Bedrooms']['Prices'].mean()data = go.Bar(
x=price_by_bed.index,
y=price_by_bed.values,
)layout = go.Layout(
title='Average Condo Price',
xaxis_title="No. of Beds",
yaxis_title="Value in $M"
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig)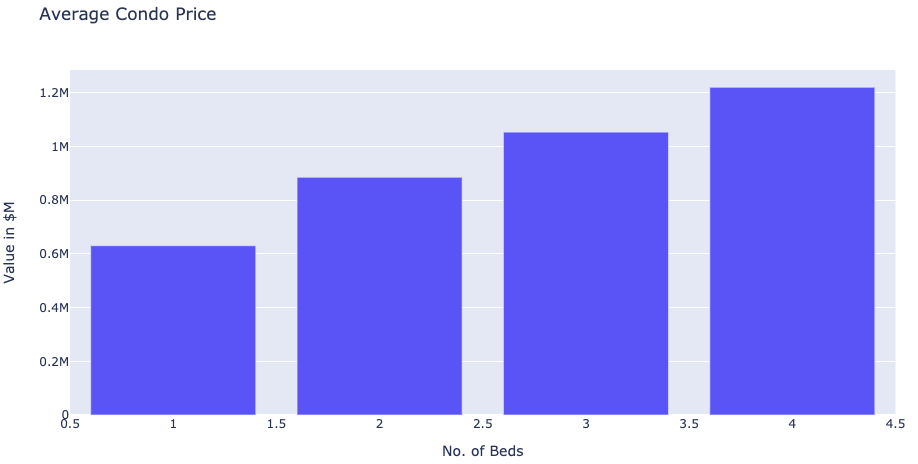
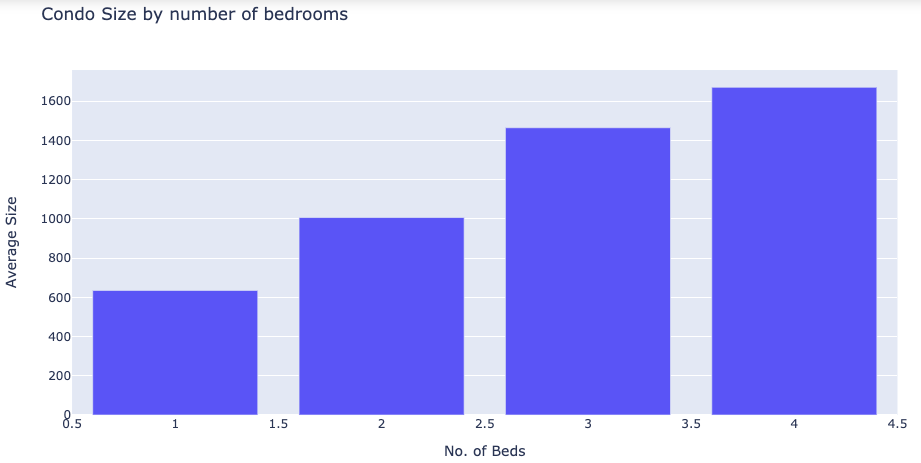
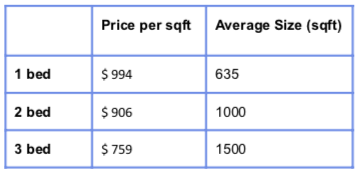
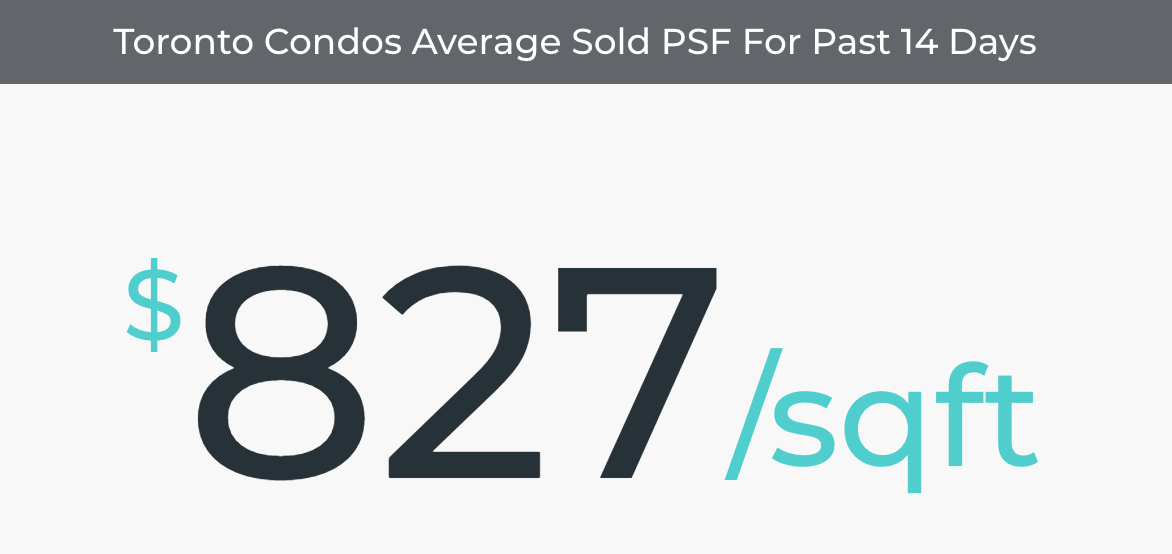
The average price per square foot (taking in only 1,2 and 3 bedrooms in the subset) was calculated at $ 897, a little higher than the quoted average of $827/sq. ft on the day of my analysis (Note: There has been a gradual decline in average prices since the onset of COVID so the values shown here may be different from the current values).
计算得出的每平方英尺平ASP格(仅在子集中的1,2和3卧室中使用)为897美元,略高于报价ASP827美元/平方英尺。 在我分析的当天(注意:自COVID出现以来,平ASP格已逐渐下降,因此此处显示的值可能与当前值不同)。
I was also able to analyze average maintenance values by the number of bedrooms. An interesting insight was that maintenance fees can make or break your investment in a condo since it could account for almost 25% of your monthly mortgage value! (something to keep in mind and not just focus on that hefty price tag)
我还能够按卧室数量分析平均维护价值。 一个有趣的见解是,维护费可以赚钱或破坏您在公寓上的投资,因为这可能占您每月按揭价值的近25%! (请注意一些事项,而不仅仅是关注高昂的价格)
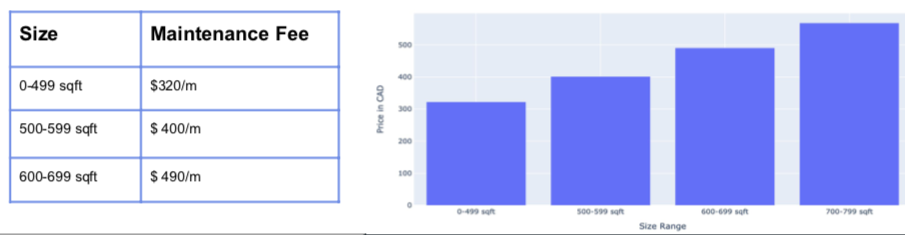
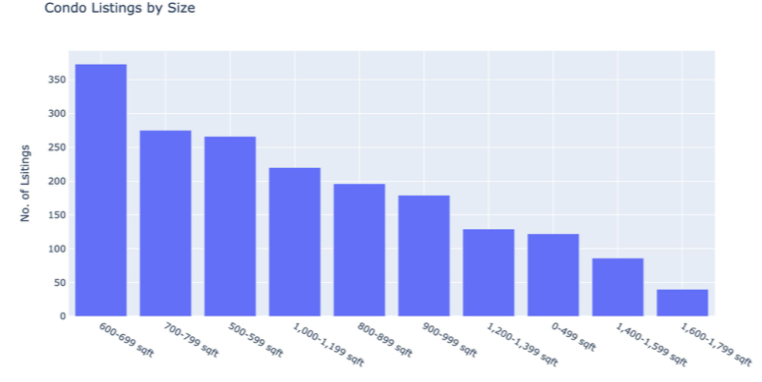
Below, I analyzed the number of listings by average sizes and found that most condos on sale fall in the 600–699 sq. ft category.
下面,我按平均大小分析了房源数量,发现出售的大多数公寓都属于600–699平方英尺类别。
These were some of the interesting insights I derived from this web scraping exercise. I am sure that armed with this knowledge now, I would fall into the category of an ‘informed buyer’’.
这些是我从此网络抓取练习中获得的一些有趣的见解。 我相信现在有了这些知识,我会属于“知情买家”类别。
If you have any interesting points to share, I would love to hear your comments down below.
如果您有任何有趣的观点要分享,我想听听您的评论。
Thanks to the team at condos.ca for giving me permission to carry out this interesting and valuable exercise!
感谢condos.ca的团队允许我进行这项有趣且有价值的练习!
Disclaimer: Please note that the views, thoughts, and opinions expressed in the text belong solely to the author, and not necessarily to the author’s employer, organization, committee, or other group or individual. This is not investment advice and the author does not intend to use the data for any commercial purposes but for personal reasons only.
免责声明:请注意,本文中表达的观点,思想和观点仅属于作者,不一定属于作者的雇主,组织,委员会或其他团体或个人。 这不是投资建议,作者不打算将数据用于任何商业目的,而仅出于个人原因。

















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









