





“It works on my machine”. That’s great. But now how do you make sure it runs in production, repeatedly and reliably? Here we share our lessons learned from deploying many analytics solutions at clients.
“它可以在我的机器上工作”。 那很棒。 但是,现在您如何确保它可以重复可靠地投入生产? 在这里,我们分享在客户中部署许多分析解决方案的经验教训。
By the way, what do we mean with “Analytics workloads”? It’s any workload where you send data to an algorithm and you create some kind of insight. That can be an ML algorithm, that can be a data cleaning job, data integration, NLP processing, … Any piece of the data pipeline really.
顺便说一句,“分析工作负载”是什么意思? 在任何工作量中,您都将数据发送到算法并创建某种见解。 那可以是ML算法,也可以是数据清理工作,数据集成,NLP处理等等……实际上是数据管道的任何部分。
部署是您最重要的事情 (Deployments are the most important thing you do)
A typical development lifecycle looks like this:
典型的开发生命周期如下所示:

In this cycle, deploying your code is the most important thing you do, because it’s only then that a client can get access to your work. Everything that goes before that is Work In Progress. Everything that comes after that is Business Value (hopefully).
在此周期中,部署代码是您最重要的事情,因为只有这样,客户端才能访问您的工作。 之前进行的所有工作都在进行中。 之后的一切都是商业价值(希望如此)。
This is often forgotten in data analytics projects. A lot of time is spent on improving the model, ingesting more data, building more features. But as long as you don’t bring your insights to your clients, you are not delivering any value.
在数据分析项目中通常会忘记这一点。 花大量时间在改进模型,获取更多数据,构建更多功能上。 但是,只要您不将见解带给客户,就不会带来任何价值。
Well, how often should you deploy then? We always promote the notion of doing 10 deploys per day (based on the great book The Phoenix Project). That means that your data team pushes 10 new valuable things to downstream consumers every single day. This is unattainable for a lot of companies that still do quarterly releases or monthly releases. If that is the case, try to bring it down to weekly releases, or maybe even daily releases. You will discover roadblocks along the way. Removing those roadblocks will make your team more efficient and will allow you to deliver results to customers faster. And it will also to learn faster from the feedback of customers and you can adjust course quicker.
那么,您应该多久部署一次? 我们始终提倡每天进行10次部署的想法(基于出色的《凤凰计划》)。 这意味着您的数据团队每天都会向下游消费者推送10项新的有价值的东西。 对于许多仍按季度发布或按月发布的公司而言,这是无法实现的。 如果是这种情况,请尝试将其降低到每周发布,甚至每天发布。 您将一路发现路障。 消除这些障碍将使您的团队更有效率,并使您更快地将结果交付给客户。 它还可以从客户的反馈中更快地学习,并且您可以更快地调整课程。
您有什么选择? (What are your options?)
There are several ways that we see analytics workloads being deployed, and we would like to evaluate them on two axes:
我们可以通过多种方式查看分析工作负载的部署情况,我们希望在两个方面对其进行评估:
Effectiveness: How good are your deployments?
有效性:您的部署有多好?
Are there limitations in what you can deploy? How often can I do deploys?Are the deployments high quality? Can they be stable / easy to monitor?
您可以部署的内容是否有限制? 我可以多久进行一次部署?部署的质量高吗? 它们可以稳定/易于监视吗?
Feasibility: How easy is it to get started with this?Do you have to learn new technologies? Will you have to spend a lot of time building the deployment pipeline? Can I have one deployment mechanism for multiple processing frameworks?
可行性:开始这个过程有多容易? 您需要学习新技术吗? 您是否需要花费大量时间来构建部署管道? 我可以为多个处理框架提供一种部署机制吗?
If you plot the different deployment options on a 2x2 matrix, along these axes, you get the following image:
如果沿着这些轴在2x2矩阵上绘制不同的部署选项,则会得到以下图像:
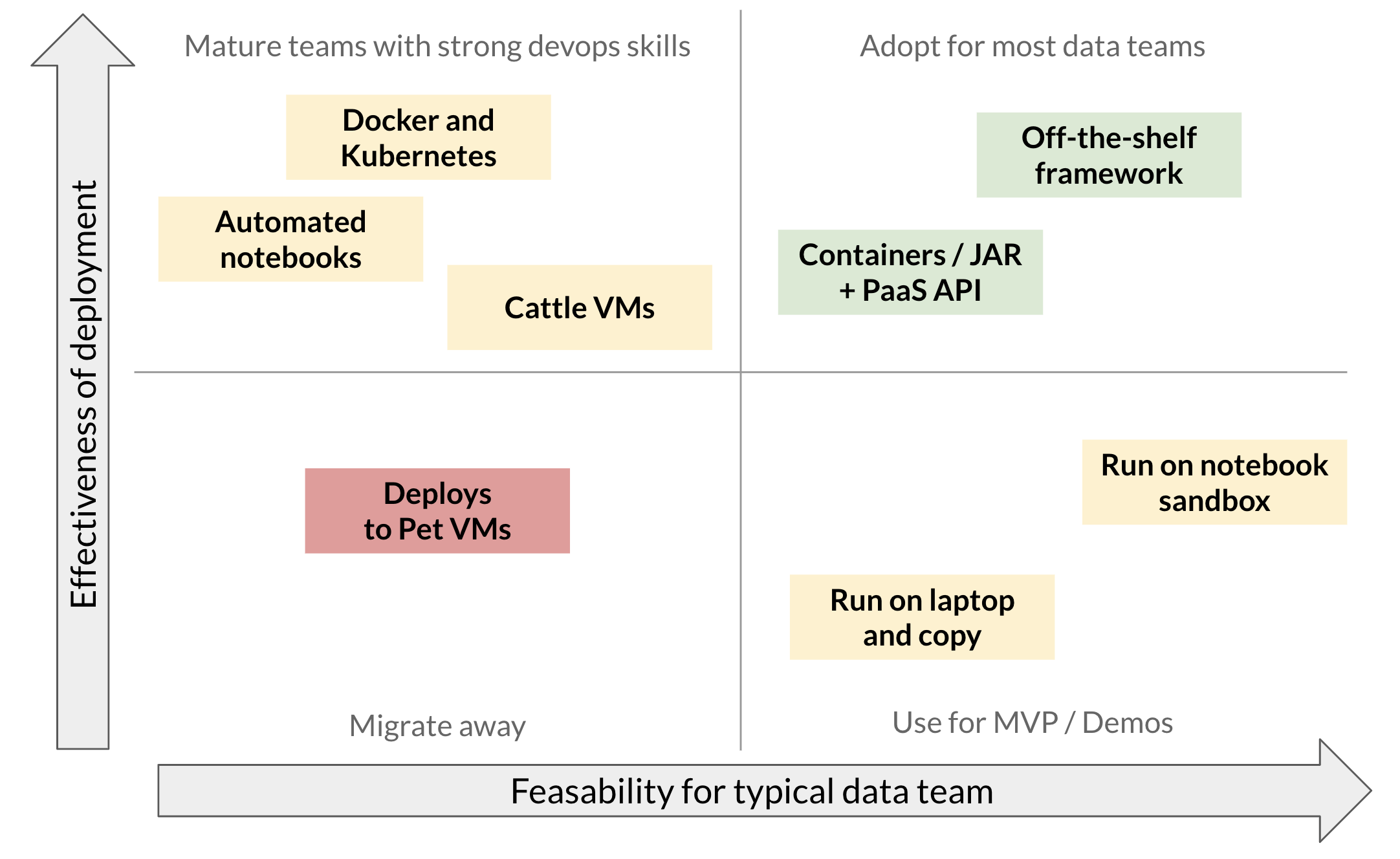
This is of course not 100% correct or the complete picture. But these are the deployment mechanisms we’ve seen a lot at clients and we think this framework helps in making the right decisions for which deployment option is right for your use case.
当然,这不是100%正确或完整的图片。 但是这些是我们在客户中经常看到的部署机制,我们认为该框架有助于做出正确的决策,以决定哪种部署选项适合您的用例。
Let’s go over them one by one:
让我们一一介绍它们:
Deploys to Pet VMs (Low feasibility / low effectiveness)Use when: Never. Avoid at all cost. Sometimes it’s impossible to avoid.
部署到Pet VM(可行性低/效率低) 在以下情况下使用:永不。 不惜一切代价避免。 有时是不可避免的。

A Pet VM is a machine you name and you really care about. It’s precious and you manually make sure it stays alive. The good thing about Pet VMs is that it’s probably a technology you know and sometimes the only option. The downsides are that the yearly license cost of a Pet is expensive, maintaining a Pet takes a lot of your time, deployments are manual and error-prone and it’s hard to recover when it goes south.
Pet VM是您真正喜欢的机器。 它很珍贵,您可以手动确保它仍然存在。 Pet VM的优点在于,它可能是您所了解的技术,有时是唯一的选择。 缺点是,宠物的年度许可费用昂贵,维护宠物需要花费大量时间,部署是手动且容易出错,并且在向南移动时很难恢复。
Run on Laptop and Copy (High feasibility / low effectiveness)Use when: MVPs and Demos
在笔记本电脑上运行并复制(可行性高/效率低) 在以下情况下使用:MVP和演示

You do all calculations locally and you upload the resulting model, calculations, insights, … to a central server. It’s relatively easy to do and you have full control of your own tooling. But, it’s hard to scale, limited by the capacity of your laptop, and of course it comes with its security issues. It is also very error prone.
您可以在本地进行所有计算,然后将结果模型,计算,见解等信息上传到中央服务器。 这样做相对容易,您可以完全控制自己的工具。 但是,它很难扩展,受笔记本电脑容量的限制,当然,它还存在安全性问题。 这也很容易出错。
Run on Notebook Sandbox (High feasibility / low effectiveness)Use when: MVPs and Demos
在笔记本沙箱上运行(高可行性/低效率) 在以下情况下使用:MVP和演示
What is it? You open a cloud notebook with connection to production data. You build your data pipelines right then and there and then you schedule your notebook. Finally, you cry while you do support on this thing.
它是什么? 您打开一个与生产数据连接的云笔记本。 您随即建立数据管道,然后再安排笔记本。 最后,您在对此事表示支持时会哭泣。
This works because it is relatively easy to do, a notebook in the cloud can scale, and multiple people can work on the same notebook.
之所以可行,是因为它相对容易做到,云中的笔记本可以扩展,并且可以在同一笔记本上同时工作多个人。
But, having multiple people on the same notebook also brings some chaos in your system. There is no version control, poor error handling and poor testing. Often this leads to infinite spaghetti code, no modularity, and limited visibility on what is in production.
但是,将多个人放在同一笔记本上也会给您的系统带来混乱。 没有版本控制,差的错误处理和不良的测试。 通常,这将导致无限的意大利面条代码,没有模块化以及对生产中产品的可见性有限。
=> This is a way of running production systems that we see way too much and is actively being promoted by some vendors. In software engineering, that’s the equivalent of manually updating the PHP files of a live website. Great for a hobby project. No serious company would work this way.
=>这是一种运行生产系统的方法,我们认为这种方法太多了,并且某些供应商正在积极推广。 在软件工程中,这等效于手动更新实时网站PHP文件。 非常适合爱好项目。 没有认真的公司会以这种方式工作。
Automated notebooks (Low feasibility / High effectiveness)Use when: Mature teams with strong devops skills
自动化笔记本(可行性低/效率高) 在以下情况下使用:具有强大开发能力的成熟团队
When we challenge the notebook approach, people often push back and point to systems like Netflix where they automated the entire notebook experience, structured the code, implemented a scheduler, have a logging solution and so forth…
当我们挑战笔记本方法时,人们经常退后一步,指向诸如Netflix之类的系统,在该系统中,他们可以使整个笔记本体验自动化,结构化代码,实现调度程序,拥有日志记录解决方案等等。
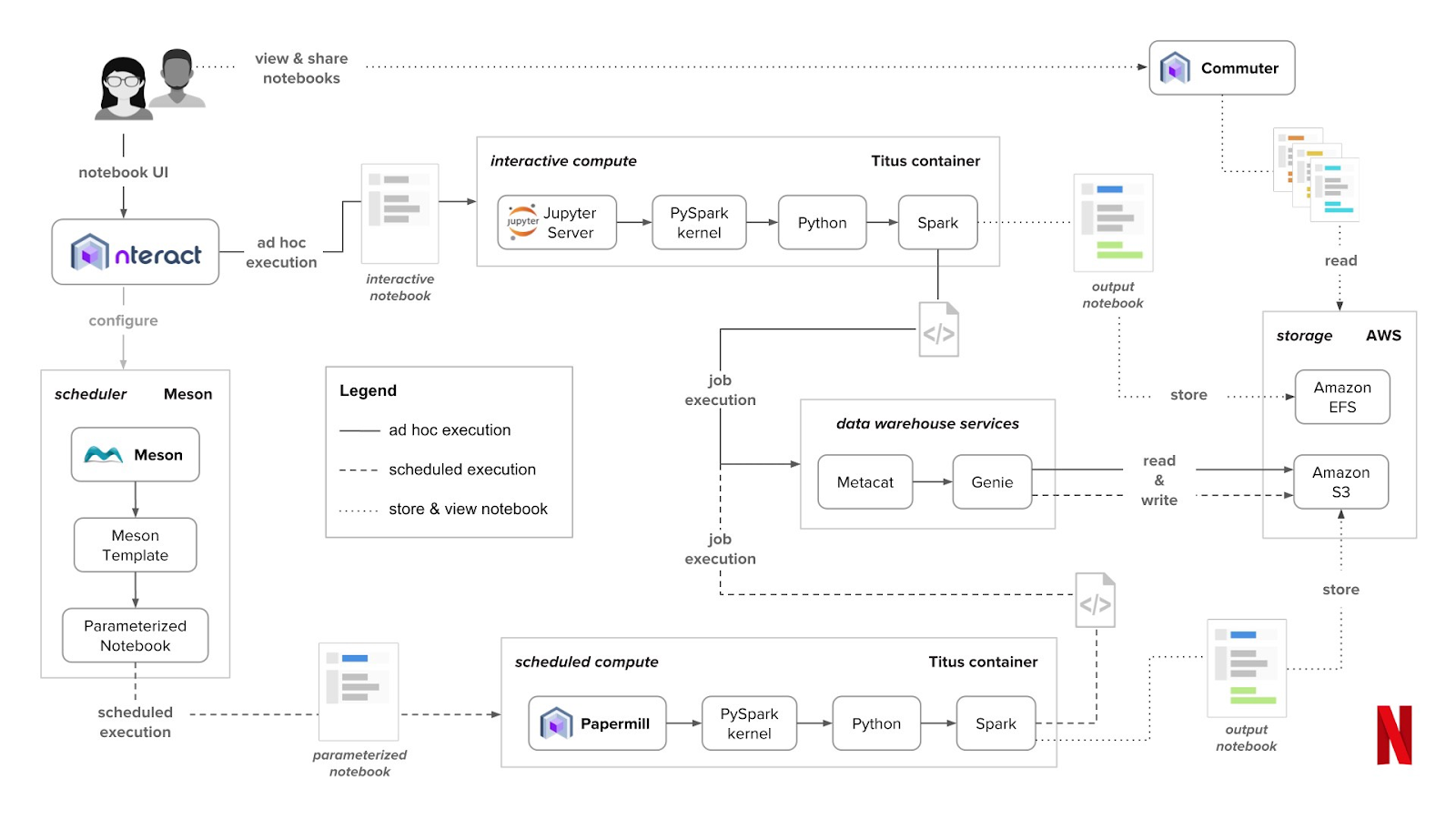
As you can see it sounds easy but to do it well you still need to build a lot. They recommend you to build an actual application when your notebook is too big. Then, they install your library in the notebook environment and from the notebook you can then just call your library main function/functions and schedule those.
如您所见,这听起来很容易,但是要做好,您仍然需要做很多工作。 他们建议您在笔记本太大的情况下构建实际的应用程序。 然后,他们将您的库安装在笔记本环境中,然后您可以从笔记本中调用库的主要功能并安排它们。
What is also very interesting is the fact that they store notebook runs as immutable traces of your application, so you can always check the notebook of a certain run for errors and launch it from there to debug.
有趣的是,它们将笔记本运行记录存储为应用程序的不变痕迹,因此您始终可以检查特定运行的笔记本记录是否存在错误,然后从那里启动以进行调试。
All in all you can see that making a proper scheduled notebook environment requires a lot of work and engineering. And what works for Netflix might not work for you or be complete overkill.
总而言之,您可以看到制作适当的预定笔记本电脑环境需要大量的工作和工程。 而且,适用于Netflix的内容可能对您不起作用,或者完全被矫kill过正。
Docker and Kubernetes (Low feasibility / High effectiveness)Use when: Mature teams with strong devops skills
Docker和Kubernetes(可行性低/效率高) 使用时间:成熟的团队,具有较强的发展能力
Kubernetes is a container platform that allows you to build platforms at scale. It’s born in 2014 out of Google and it’s a great building block for your data platform. On top, it has a large and growing ecosystem.
Kubernetes是一个容器平台,可让您大规模构建平台。 它于2014年从Google诞生,对于您的数据平台来说是一个很好的构建块。 最重要的是,它拥有一个庞大且不断发展的生态系统。

Most software integrates or is integrating with kubernetes. It probably is the platform of the future. And you have fast startup for your applications. The downside is that the future is not there yet. It’s a great building block but deep knowledge of kubernetes is needed to build a data platform. And there are not a lot of people have this knowledge currently.
大多数软件都集成或正在与kubernetes集成。 它可能是未来的平台。 而且您可以快速启动应用程序。 不利的一面是未来还不存在。 这是一个很好的构建基块,但是需要建立Kubernetes的深厚知识才能构建数据平台。 而且目前没有多少人知道这些知识。
Containers or Jars + PaaS API (High feasibility / High effectiveness)Use when: Adopt for most data teams
容器或罐子+ PaaS API(高可行性/高效率) 在以下情况下使用:适用于大多数数据团队
In this approach you basically take what the cloud vendors offer you and you rely on that as much as possible. Examples are Google Cloud Dataflow, Amazon EMR, Azure Batch, …
通过这种方法,您基本上可以采用云供应商为您提供的服务,并且您将尽可能地依靠它。 示例包括Google Cloud Dataflow,Amazon EMR,Azure Batch等。

This approach works because a lot of the complex work is done for you. These services are stable and can be used at scale. And they often come with metrics and monitoring integrated.
这种方法之所以有效,是因为为您完成了许多复杂的工作。 这些服务是稳定的,可以大规模使用。 而且它们通常带有集成的指标和监控。
The downsides are that not everything comes out of the box. You still have to do a lot of work yourself, and you need to add a lot of glue to get going. There is always a risk of vendor lock-in if you rely too much on their tooling. And autoscaling and alerting is something you need to often build yourself.
不利之处在于,并非所有东西都是开箱即用的。 您仍然必须自己做很多工作,并且需要添加很多胶水才能开始。 如果您过于依赖供应商的工具,则始终存在供应商锁定的风险。 自动缩放和警报是您经常需要建立的东西。
Use frameworks (High feasibility / High effectiveness)Use when: Adopt for most data teams
使用框架(高可行性/高有效性) 在以下情况下使用:适用于大多数数据团队
You’re not the first one in this situation. Deployment patterns emerge and frameworks help you automate the production-grade deployment of code. Tooling like Netlify and Serverless.com are examples of this approach. We have recently launched Datafy, a data engineering framework for building, deploying and monitoring analytics workloads at scale.
在这种情况下,您不是第一个。 出现了部署模式,框架帮助您自动化了生产级代码的部署。 像Netlify和Serverless.com这样的工具就是这种方法的示例。 我们最近启动了Datafy ,这是一个用于大规模构建,部署和监视分析工作负载的数据工程框架。
The good thing about these frameworks is that most of the complex work is done for you. You follow industry best practices. And monitoring and scaling comes out of the box. It makes sure you’re up and running in no time.
这些框架的好处是,大多数复杂的工作都为您完成。 您遵循行业最佳实践。 开箱即用的监视和扩展功能。 它可以确保您立即启动并运行。
The downside of a framework is that it is always tailored to specific needs so you are always constrained to what the framework offers. So it’s a matter of choosing the right framework for you.
框架的缺点是,它总是针对特定需求量身定制,因此您总是受制于框架所提供的功能。 因此,为您选择正确的框架是一个问题。
Datafy如何运作? (How does this work at Datafy?)
Deployments are the most important thing you do. That’s why we make it super easy and quick to do at least 10 deploys per day, through the use of the CLI:
部署是您最重要的事情。 这就是为什么我们通过使用CLI使得每天至少进行10次部署变得超级容易和快捷:
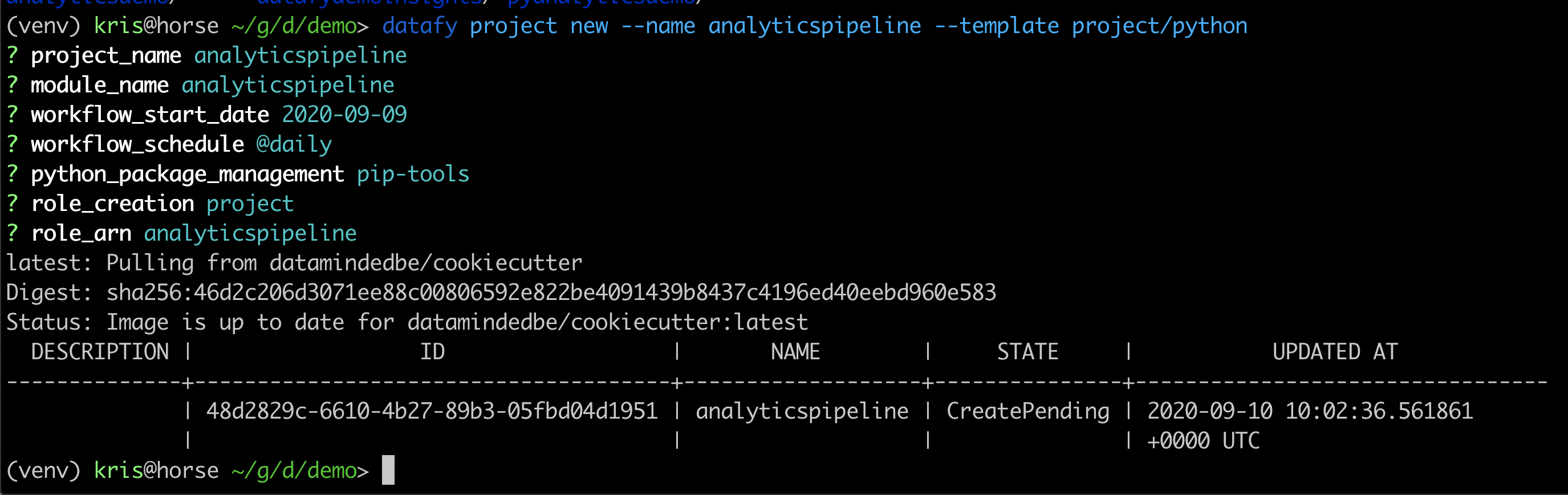
Create a new project
创建一个新项目
datafy project new — name analyticspipeline --template project/pythonThis will set up a code structure, create a data pipeline with a sample job in it plus a unit test, add a Dockerfile, configure a Python virtualenv and basically do all the scaffolding for you.
这将建立一个代码结构,创建一个带有示例作业以及单元测试的数据管道,添加一个Dockerfile,配置一个Python virtualenv并基本上为您做所有的脚手架。

Build the project
建立项目
That’s also a single command-line:
这也是一个命令行:
datafy project build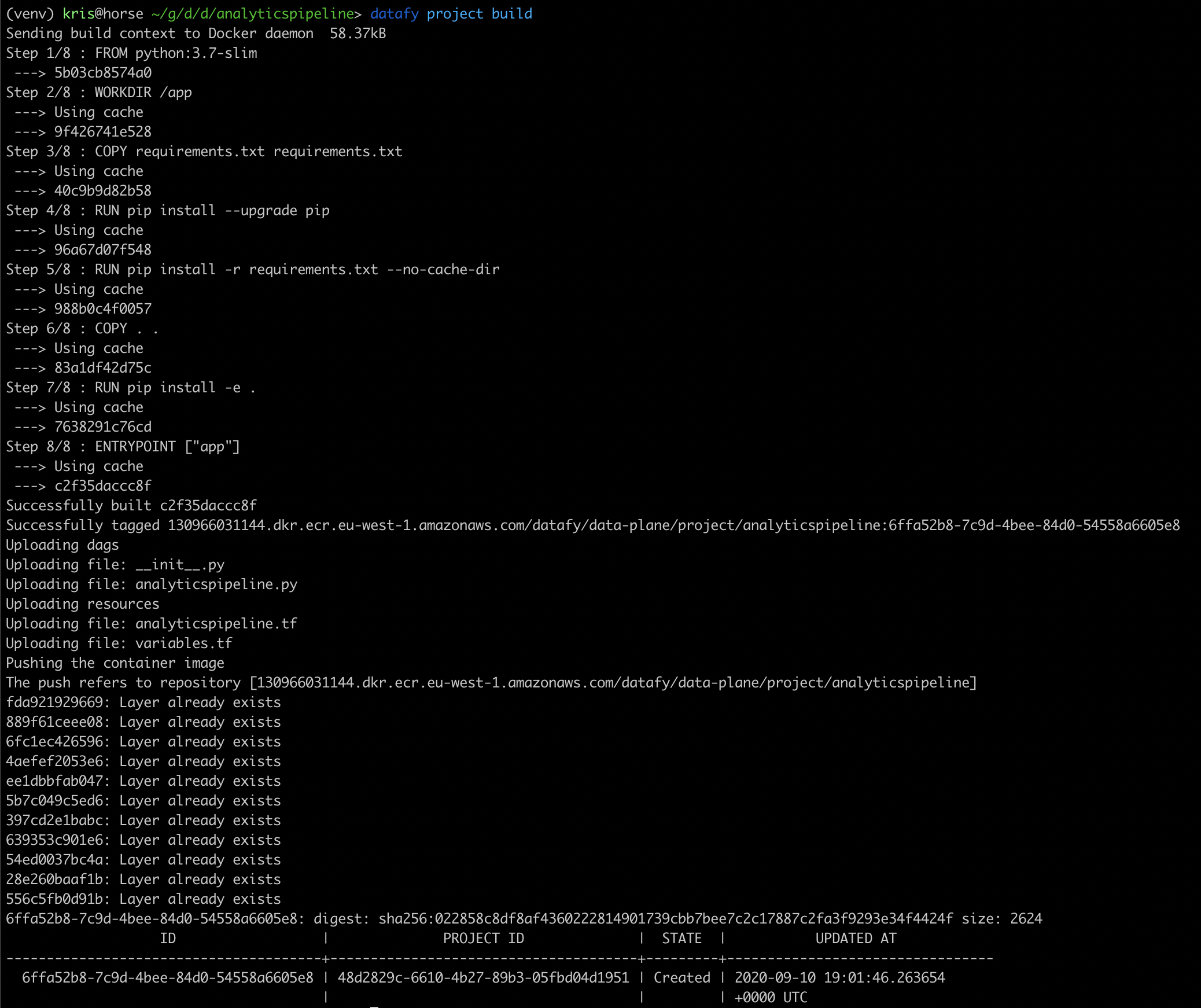
What this will do is wrap your code in a docker container, and push that container to a Container Registry in your cloud, in this case ECR.
这样做是将代码包装在Docker容器中,然后将该容器推送到您云中的Container Registry,在本例中为ECR。
Deploy your project
部署项目
That’s as you guessed it, another single command-line:
就像您猜到的那样,这是另一个命令行:
datafy project deploy --env dev --wait
And about 2 min later, you’re done. Your analytics pipeline is live.
大约2分钟后,您就完成了。 您的分析管道是实时的。
所以呢? (So what?)
Why is this important again? Whether you use Datafy, take something else off the shelves, or build your own system, it is important to be able to deploy 10x per day. Organisations who do this, are able to deliver results to customers faster, have higher ROI on their data investments and, most importantly, learn from feedback of their customers.
为什么这又很重要? 无论您是使用Datafy,其他产品还是构建自己的系统,每天能够部署10倍,这一点都很重要。 这样做的组织能够更快地向客户提供结果,其数据投资具有更高的投资回报率,最重要的是,可以从客户的反馈中学习。
This blog a is a written version of a webinar we hosted earlier which you can rewatch on youtube here:
此博客是我们先前举办的网络研讨会的书面版本,您可以在youtube上重新观看:
翻译自: https://medium.com/datamindedbe/how-to-deploy-analytics-workloads-563279bc9694


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}