





 本文介绍如何利用Python抓取Spotify上最受欢迎的歌曲,详细解析爬虫实现过程。
本文介绍如何利用Python抓取Spotify上最受欢迎的歌曲,详细解析爬虫实现过程。
抓取spotify歌单
Spotify is one of the most popular music streaming services in the world, with nearly 300 million users as of 2020. It is also a data analyst’s dream, with publicly available metrics on everything from broad topics such as the top songs in the past month, to minutiae like the “speechiness” (how many words are in a track) of your favorite song. Today, we’ll be looking at how to scrape the Top 200 songs on Spotify for every day for the past year using Python’s Beautiful Soup and Pandas. This is the first part of my “Know the Vibes Animation” series, in which we explore how the mood of top songs on Spotify has shifted over the past year.
Spotify是全球最受欢迎的音乐流媒体服务之一,截至2020年拥有近3亿用户。这也是数据分析师的梦想,它提供了有关广泛主题的公开可用指标,例如上个月的热门歌曲,就像您喜欢的歌曲的“语音”(音轨中有多少个单词)一样。 今天,我们将研究如何使用Python的Beautiful Soup和Pandas在过去一年中每天在Spotify上刮取前200首歌曲。 这是我的“了解共鸣动画”系列的第一部分,在其中,我们探讨了Spotify上顶级歌曲的情绪在过去一年中如何变化。
To start, we’ll be using Anaconda, a platform consisting of popular data science tools. To install the free version of Anaconda, click here.
首先,我们将使用Anaconda,该平台由流行的数据科学工具组成。 要安装Anaconda的免费版本,请单击此处 。
Great! Now that Anaconda’s up and running, we’ll be using its JupyterLab interface. JupyterLab will allow us to get immediate feedback on our Python script.
大! 现在Anaconda已启动并运行,我们将使用其JupyterLab界面。 JupyterLab将使我们能够立即获得有关Python脚本的反馈。
Now, we’re going to import some helpful packages and libraries.
现在,我们将导入一些有用的软件包和库。
from bs4 import BeautifulSoup
import pandas as pd
import requests
from time import sleep
from datetime import date, timedelta(Note for beginners: To run the script, press “shift” and “enter.”)
(初学者注意:要运行脚本,请按“ Shift”和“ Enter”。)
To review what these do:
要查看这些功能:
Beautiful Soup helps us to extract data from HTML files.
Beautiful Soup帮助我们从HTML文件提取数据。
Pandas will help us transform our array of data (one-dimensional, hard to read, disorganized) into a nice data-frame (two-dimensional, easy-to read).
熊猫将帮助我们将数据数组(一维,难于阅读,杂乱无章)转换成一个不错的数据框(二维,易读)。
Requests allows us to send HTTP requests, allowing us to get relevant info from the webpages, such as content, encoding, etc.
请求使我们能够发送HTTP请求,从而使我们能够从网页获取相关信息,例如内容,编码等。
Sleep makes sure that we don’t overwhelm the server by sending too many requests at once. It puts a pause in our code. This also helps to make sure our page is fully loaded before proceeding.
睡眠可确保我们不会一次发送太多请求而使服务器不知所措。 它使我们的代码暂停了。 这也有助于确保在继续操作之前,我们的页面已完全加载。
Date will help us tack on dates to our base URL so that we can get top daily song data. Timedelta will help us to get data for each day in the duration which we’re studying.
日期将帮助我们将日期附加到我们的基本URL,以便我们获取每日的热门歌曲数据。 Timedelta将帮助我们在学习期间每天获取数据。
We’ll then define some empty arrays so that we can store the data which we’ll collect.
然后,我们将定义一些空数组,以便我们可以存储要收集的数据。
dates=[]
url_list=[]
final = []The next part of scraping multiple pages is mapping the pages which we want to scrape. We do this by identifying a base URL. Since we’ll be looking at daily data from Spotify Charts for the US, our base URL would be “https://spotifycharts.com/regional/us/daily/” . Next, we want to define the range of dates which we’ll be studying. I decided to study the past year in music, but you can adjust the dates accordingly. We also define delta as the difference between these two dates, which will help with iteration later.
抓取多个页面的下一部分是映射我们要抓取的页面。 我们通过识别基本URL来实现。 由于我们将查看来自美国Spotify图表的每日数据,因此我们的基本URL为“ https://spotifycharts.com/regional/us/daily/”。 接下来,我们要定义将要研究的日期范围。 我决定学习音乐的过去一年,但是您可以相应地调整日期。 我们还将增量定义为这两个日期之间的差,这将有助于以后的迭代。
We then write a for loop which will cycle through each date, convert it into a string, and then append it to our dates array.
然后,我们编写一个for循环,该循环将遍历每个日期,将其转换为字符串,然后将其附加到我们的dates数组中。
We’ll then write a function to cycle through these date-strings, and append each of them to our base URL, and then put the new URLs in an array. After running the function, we’ve now mapped what we’re going to scrape!
然后,我们将编写一个函数来循环这些日期字符串,并将它们分别附加到我们的基本URL,然后将新的URL放入数组中。 运行该函数后,我们现在已经映射了要抓取的内容!
#map site
url = "https://spotifycharts.com/regional/us/daily/"
start_date= date(2019, 9, 1)
end_date= date(2020, 9, 1)
delta= end_date-start_date for i in range(delta.days+1):
day = start_date+timedelta(days=i)
day_string= day.strftime("%Y-%m-%d")
dates.append(day_string)def add_url():
for date in dates:
c_string= url+date
url_list.append(c_string)add_url()Now what do we do with the URLs in our list? Well, we want to go through each of them, pull out the relevant text, and then store it. In order to do that, we first have to use Requests to get the content of the page. So that we don’t overwhelm the server on each loop, I put a 2 second pause in. Afterwards, we use Beautiful Soup to parse the text of our content. Then, we go down to the chart on the page which lists all the song data.
现在,我们如何处理列表中的URL? 好吧,我们想遍历每一个,取出相关文本,然后将其存储。 为了做到这一点,我们首先必须使用请求来获取页面的内容。 为避免每次循环时服务器不堪重负,我暂停了2秒。然后,我们使用Beautiful Soup解析内容的文本。 然后,我们转到页面上的图表,其中列出了所有歌曲数据。
for u in url_list:
read_pg= requests.get(u)
sleep(2)
soup= BeautifulSoup(read_pg.text, "html.parser")
songs= soup.find("table", {"class":"chart-table"})
song_scrape(u)Let’s go and get the data which we’ll be using for our animation.
我们去获取将用于动画的数据。
def song_scrape(x):
pg = x
for tr in songs.find("tbody").findAll("tr"):
artist= tr.find("td", {"class": "chart-table-
track"}).find("span").text
artist= artist.replace("by ","").strip()
title= tr.find("td",{"class": "chart-table-
track"}).find("strong").text songid= tr.find("td", {"class": "chart-table-
image"}).find("a").get("href")
songid= songid.split("track/")[1] url_date= x.split("daily/")[1] final.append([title, artist, songid, url_date])In our song_scrape function, we include the argument x so that the program knows what page we’re scraping. Then, we use search through the text which we got from Beautiful Soup to find each table row. Then, we analyze the HTML to see what elements we need to select to get artist, title, and song ID information.
在我们的song_scrape函数中,我们包含参数x,以便程序知道我们要抓取的页面。 然后,我们使用“ 美丽汤”中的文本进行搜索,以找到每个表格行。 然后,我们分析HTML,以了解需要选择哪些元素来获取艺术家,标题和歌曲ID信息。
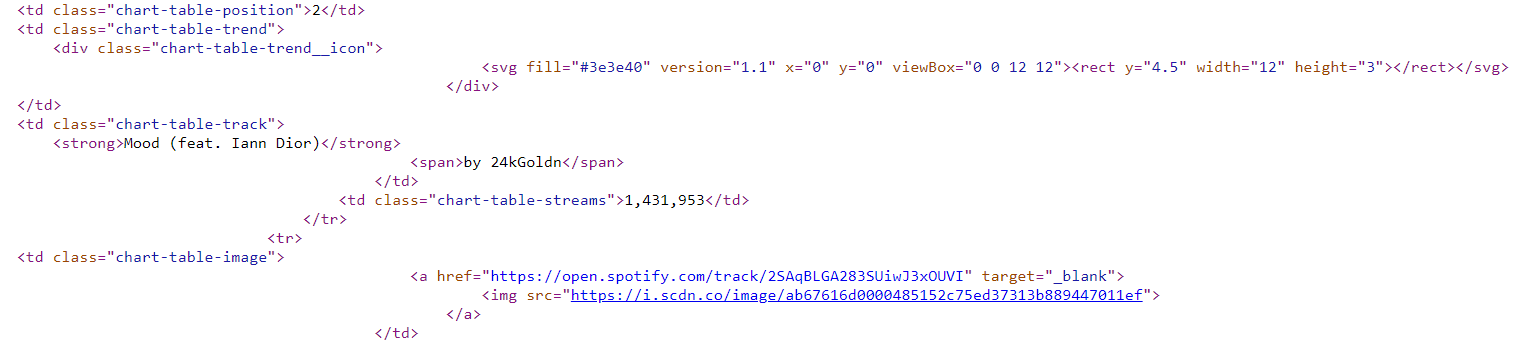
Based on the song above, Mood, we see that the artist is inside the <span> element. Thus, we find the class that the span is in (“chart-table-track”), find the span, and get the text of that. We replicate this process for the song title as well.
根据上面的歌曲Mood ,我们可以看到艺术家位于<span>元素内。 因此,我们找到跨度所在的类(“图表表轨道”),找到跨度,并获取其文本。 我们也为歌曲标题重复此过程。
Song ID is a bit trickier. When we make calls to the Spotify API in the second part of our tutorial, we’ll need the Spotify track ID’s (ex: 7FIWs0pqAYbP91WWM0vlTQ, Eminem’s “Godzilla).
歌曲ID有点棘手。 当在本教程的第二部分中调用Spotify API时,我们将需要Spotify轨道ID(例如:7FIWs0pqAYbP91WWM0vlTQ,Eminem的“ Godzilla”)。
The problem is that the Charts don’t have the Spotify ID included. They do have links to listen to the song in your browser however (ex: https://open.spotify.com/track/22LAwLoDA5b4AaGSkg6bKW, Lil Mosey’s “Blueberry Faygo”). As it happens, everything after “track/” in our URL matches the form of our track ID’s. They are our track ID’s.
问题在于图表中没有包含Spotify ID。 它们确实具有在您的浏览器中收听歌曲的链接(例如:Lil Mosey的“蓝莓Faygo”(例如https://open.spotify.com/track/22LAwLoDA5b4AaGSkg6bKW ))。 碰巧的是,我们网址中“ track /”之后的所有内容都与我们的曲目ID的形式匹配。 它们是我们的曲目ID。
All we have to do then is to split the URL into two parts, based on the strings before and after “track/” (including “track/”), and then take the second substring. Since Python’s indexing starts at 0, we take the second substring with [1]. Similarly, we note the date that the song charted by splitting the URL into the base URL and the date. We add all of our newfound data into a previously created empty array.
然后,我们要做的就是根据“ track /”之前和之后的字符串(包括“ track /”)将URL分为两部分,然后获取第二个子字符串。 由于Python的索引从0开始,所以我们将第二个子字符串作为[1]。 同样,我们通过将URL分为基本URL和日期来记录歌曲绘制的日期。 我们将所有新发现的数据添加到以前创建的空数组中。
The for loop which we precedes this code chunk calls this function at the end of it, running it.
我们在此代码块之前的for循环在其末尾调用此函数并运行它。
Now, all we have to do is convert the array into the appropriate form and save it. Here, we use Pandas to put the data into a data frame with appropriately named columns. We then write to a new CSV file, with header= True to acknowledge our column titles.
现在,我们要做的就是将数组转换为适当的形式并保存。 在这里,我们使用Pandas将数据放入具有适当命名列的数据帧中。 然后,我们使用header = True写入新的CSV文件,以确认我们的列标题。
final_df = pd.DataFrame(final, columns= ["Title", "Artist", "Song ID", "Chart Date"]) with open('spmooddata.csv', 'w') as f:
final_df.to_csv(f, header= True, index=False)After opening the file in Excel and deleting some blank rows, we get our finished product:
在Excel中打开文件并删除一些空白行后,我们得到了成品:
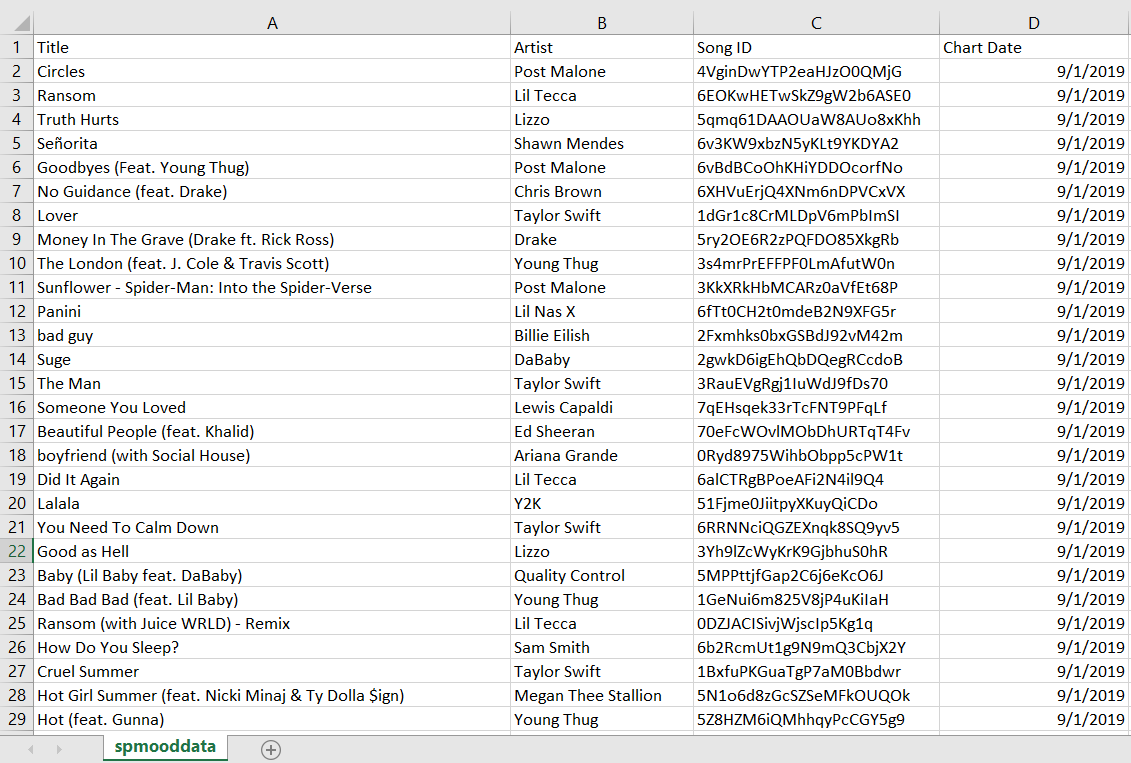
And there we have it! The full script can be viewed on my GitHub here. Join me soon for ~Part 2~!
我们终于得到它了! 完整的脚本可以在我的GitHub上查看 。 快加入我吧〜 第2部分〜 !
抓取spotify歌单

















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









