





诱饵扫描
The term “clickbait” refers to an article headline written with the sole purpose of using sensationalist language to lure in a viewer to click through to a certain webpage. The webpage then generates ad revenue on the user’s clicks or monetizes the user’s activity data. The article itself is not written with journalistic integrity, research or really striving for any deeper meaning — it is simply a vehicle to monetize user clicks and data
术语“点击诱饵”指的是撰写标题的文章,其唯一目的是使用耸人听闻的语言来诱使查看者点击以进入某个网页。 然后,该网页通过用户的点击产生广告收入,或通过用户的活动数据获利。 本文本身并不是以新闻工作者的正直,研究或真正追求更深层含义的方式撰写的-它只是一种通过用户点击和数据获利的工具
With the explosion of social media, smartphones and the state of an increasingly digital world , there is no shortage of content vying for our attention. The ease of sharing and reposting on social media has allowed clutter like clickbait to run absolutely wild.
随着社交媒体,智能手机的爆炸式增长以及数字化世界的发展,不乏内容争夺我们的注意力。 易于在社交媒体上共享和重新发布,已使诸如Clickbait之类的杂物变得异常疯狂。
As clickbait has become increasingly prevalent across the web (remember when you could scroll through your Twitter feed and only see genuine content?) — I wanted to see if a headline could be classified using machine learning and what that process looks like. My goal with this project is to provide evidence for implementation on a larger scale on social media or various publisher websites as a ‘clickbait blocker’ (think ‘ad blocker’), where clickbait could be flagged or filtered out as such before a viewer ever lays eyes on it!
随着点击诱饵在网络上变得越来越普遍(还记得您何时可以滚动浏览Twitter提要并仅看到真实内容吗?)—我想看看是否可以使用机器学习对标题进行分类,以及该过程的外观。 这个项目的目标是为社交媒体或各种发布者网站上的“点击诱饵阻止程序”(认为是“广告阻止程序”)提供大规模实施的证据,在这种情况下,点击诱饵可能会在观众观看之前被标记或过滤掉盯上它!
数据 (The Data)
For this project, my data consisted of 52,000 headlines from a variety of clickbait and non-clickbait sources from roughly 2007–2020. My final dataset was compiled from a dataset found on Kaggle, as well as my own scraping and API calls of Twitter and various online publications. The data was labeled as clickbait or non-clickbait depending on the source and my final dataset was generally balanced (see distribution below).
对于这个项目,我的数据包括大约2007-2020年来自各种点击诱饵和非点击诱饵来源的52,000个标题。 我的最终数据集是根据在Kaggle上找到的数据集 ,以及我自己对Twitter和各种在线出版物的抓取和API调用编译而成的。 根据来源,数据被标记为点击诱饵或非点击诱饵,并且我的最终数据集通常处于平衡状态(请参见下面的分布)。
Clickbait sources: Buzzfeed, Upworthy, ViralNova, BoredPanda, Thatscoop, Viralstories, PoliticalInsider, Examiner, TheOdyssey
Clickbait来源: Buzzfeed,Upworthy,ViralNova,BoredPanda,Thatscoop,Viralstories,politicalInsider,Examiner,TheOdyssey
Non-clickbait sources: NY Times, The Washington Post, The Guardian, Bloomberg, The Hindu, WikiNews, Reuters
非点击诱饵来源 :《纽约时报》,《华盛顿邮报》,《卫报》,彭博社,印度教徒,维基新闻,路透社
数据处理与特征工程 (Data Processing & Feature Engineering)
As I was initially just working with the text data of each headline, the cleaning and feature engineering steps taken are described below.
当我刚开始使用每个标题的文本数据时,下面描述的清理和要素工程步骤。
Cleaning and processing
清洁与加工
- Punctuation, links and non-alphabetical/non-numeric characters were removed from the headlines using Regex. Numbers were not scrubbed as I wanted to account for the presence of a number. 使用正则表达式从标题中删除了标点,链接和非字母/非数字字符。 由于我想说明数字的存在,因此没有擦除数字。
- English stop words were removed using NLTK. 英语停用词已使用NLTK删除。
- Each headline was converted into lowercase and tokenized — unigrams for the initial EDA, and both unigrams and bigrams for modeling and later EDA. 每个标题都转换为小写字母和标记化符号-最初的EDA用字母组合表示,建模和以后的EDA用字母组合和双字母组合表示。
- Word frequency was utilized in my initial EDA, but my models relied on TF-IDF scores using NLTK’s implementation for each unigram and bigram. 我最初的EDA中使用了词频,但是我的模型依靠NLTK对每个字母和双字母组的实现使用TF-IDF分数。
Additional Feature Engineering
附加特征工程
I created the following features to assess along with the headline text data:
我创建了以下功能以与标题文本数据一起进行评估:
headline_words: word count in a headline (created before stop words were removed).
headline_words : 标题中的字数(在删除停用词之前创建)。
question: 1 for yes & 0 for no, if the headline started with a question word and/or included a ‘?’ (created before stop words and punctuation were removed).
问题 :如果标题以疑问词开头和/或包含“?”,则为1表示否,0表示否。 (在停用词和标点符号删除之前创建)。
exclamation: 1 if the headline includes an exclamation point, 0 if it does not (created before punctuation was removed).
感叹号 :如果标题包含感叹号,则为1;否则,则为0(在删除标点符号之前创建)。
starts_with_num: 1 if the headline starts with a number, 0 if it does not.
starts_with_num :如果标题以数字开头, 则为 1,否则为0。
EDA (EDA)
Prior to running any models, I analyzed the word frequencies of clickbait headlines and non-clickbait headlines. There were some clear distinctions in vocabulary as well as some overlap as visualized in the WordClouds below. In the clickbait cloud, numbers were prevalent along with vague terms. For example, a clickbait headline utilizing these words might be something along the lines of “The 19 best things people actually need” and so a reader would want to click in to read about the specific people or things…
在运行任何模型之前,我分析了点击诱饵标题和非点击诱饵标题的词频。 在词汇上有一些明显的区别,在下面的词云中也有一些重叠。 在点击诱饵云中,数字和模糊的术语一起盛行。 例如,使用这些单词的点击诱饵标题可能类似于“人们真正需要的19件事”,因此读者可能希望单击以阅读有关特定人物或事物的信息……
I also analyzed the class distribution of my engineered features and their relevance on each class. As shown below, on average, clickbait headlines are slightly longer than non-clickbait headlines.
我还分析了我的设计特征的类分布及其与每个类的相关性。 如下所示,平均而言,点击诱饵标题要比非点击诱饵标题更长。
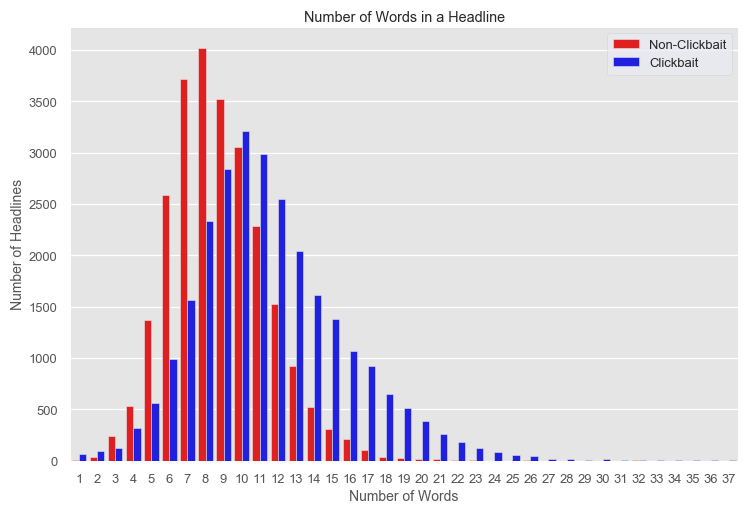
Clickbait headlines also more often start with a number or pose a question within the headline.
Clickbait标题通常也以数字开头或在标题中提出问题。
造型 (Modeling)
I trained and tested the following models — a baseline dummy classifier that predicts the majority class, a Naive Bayes classifier, a Random Forest classifier, a Linear SVM classifier and a Logistic Regression model. The evaluation metrics that I utilized for measuring performance were accuracy and recall. I placed a slight emphasis on recall to minimize false negatives, such as classifying a clickbait article as not clickbait. The following is a snapshot into the accuracy and recall scores of my test predictions:
我训练并测试了以下模型-预测多数类的基线虚拟分类器,朴素贝叶斯分类器,随机森林分类器,线性SVM分类器和Logistic回归模型。 我用来衡量绩效的评估指标是准确性和召回率。 我对召回略有强调,以最大程度地减少误报,例如将点击诱饵文章归类为非点击诱饵。 以下是测试预测的准确性和召回力得分的快照:
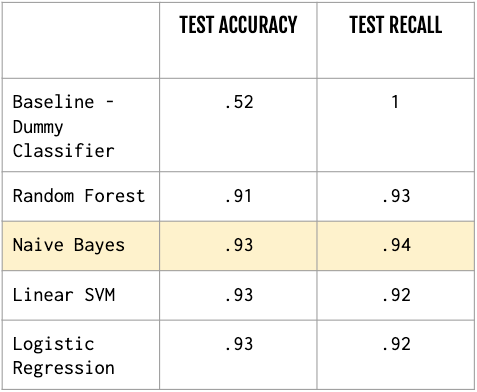
Naive Bayes performed the best as shown above in terms of recall and accuracy scores, but the other models were not too far off. Naive Bayes also makes a good final model as it runs a lot faster than the other models, which will work well with a lot more data in a real-world scenario.
就召回率和准确性得分而言,朴素贝叶斯表现最佳,如上所示,但其他模型相差不远。 朴素贝叶斯也成为一名优秀的最终模式,因为它的运行速度比其他车型,这将在真实的场景中有很多更多的数据很好地工作快得多。
I was able to take a closer look at the model’s process by evaluating the coefficients and I gained useful insight into what features, and words, were being used by the model to make the classification.
通过评估系数,我可以更仔细地查看模型的过程,并获得了有用的见解,可以了解模型使用了哪些特征和单词进行分类。
结论与总结 (Concluding Thoughts & Takeaways)
I was able to use machine learning algorithms such as Naive Bayes, Logistic regression and SVM to accurately classify clickbait versus non-clickbait headlines. The results were quite good — within the 90–93% range for accuracy scores and 90–93% range for recall scores. I slightly prioritized recall as I figured that it would be more valuable to minimize false negatives (classifying clickbait as non-clickbait).
我能够使用诸如朴素贝叶斯,逻辑回归和SVM之类的机器学习算法来对点击诱饵和非点击诱饵标题进行准确分类。 结果非常好-准确性得分在90-93%范围内,召回得分在90-93%范围内。 我稍微想起召回的优先顺序,因为我发现将假阴性最小化(将点击诱饵归类为非点击诱饵)会更有价值。
As machine learning was able to work so well, there is definitely a real-world use case for deploying a machine learning solution to filter out or flag clickbait before a reader even has to visualize and evaluate the headline for themselves!
由于机器学习能够很好地运行,因此肯定有一个现实世界的用例,即在读者甚至不得不自己可视化和评估标题之前,部署机器学习解决方案来过滤或标记点击诱饵!
By analyzing the coefficients of the models that performed the best, I was able to interpret and get some insight into how the models determined if a headline is clickbait or not.
通过分析表现最佳的模型的系数,我能够解释并获得一些洞察力,以了解模型如何确定标题是否为点击诱饵。
演示版 (Demo)
I put together a simple web app using Streamlit to demo and test out my model with new headlines.
我使用Streamlit编写了一个简单的Web应用程序,以使用新的标题演示和测试我的模型。
Feel free to try the deployed version on Heroku and submit a headline of your choosing for classification: clickbait detector.
随意尝试在Heroku上部署的版本,并提交您选择的标题进行分类: clickbait探测器 。
If you’re interested in the code behind this project — check out my Github: https://github.com/AlisonSalerno/clickbait_detector
如果您对该项目背后的代码感兴趣,请查看我的Github: https : //github.com/AlisonSalerno/clickbait_detector
翻译自: https://towardsdatascience.com/is-this-headline-clickbait-86d27dc9b389
诱饵扫描

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}