





 sentipy是一个用于文本特征可视化的工具,基于Spacy的情感分析包和Lime进行特征识别。它利用混合架构进行情感分类,并通过Streamlit创建Web应用程序。sentipy的工作流程包括文本处理、特征学习和可视化。该工具目前仍处于开发阶段,但其MVP版本已经可以用来识别基本模型学习的特征。通过sentipy,用户可以理解模型预测类别背后的依据。
sentipy是一个用于文本特征可视化的工具,基于Spacy的情感分析包和Lime进行特征识别。它利用混合架构进行情感分类,并通过Streamlit创建Web应用程序。sentipy的工作流程包括文本处理、特征学习和可视化。该工具目前仍处于开发阶段,但其MVP版本已经可以用来识别基本模型学习的特征。通过sentipy,用户可以理解模型预测类别背后的依据。
spark ml 文本分类
目的 (Objective)
The objective of this post is to help you understand how to identify the features that your ML model learns from the text input and understand the reason behind predicting the category it did.
这篇文章的目的是帮助您了解如何识别ML模型从文本输入中学习的功能,并了解预测其类别的背后原因。
背景 (Background)
The web-app — sentipy that helps in visualizing the text features is built on top of a sentiment analysis package. While the core package is at a very basic stage of development, the focus of this post is understand what features is your model learning.
在web-app - sentipy ,有助于可视化文本功能是建立在情感分析包的顶部。 尽管核心程序包处于开发的非常基本的阶段,但是本文的重点是了解您的模型学习有哪些功能。
组件 (Components)
Sentipy relies on several open source components. Following are the building blocks:
Sentipy依赖于几个开源组件。 以下是构建基块:
- Spacy — Text processing Spacy-文本处理
- Spacy Textcat — Sentipy leverages on Spacy’s textcat component with a hybrid architecture for sentiment classification Spacy Textcat — Sentipy利用Spacy的textcat组件和混合体系结构进行情感分类
- Lime — For identifying and visualizing features learnt Lime-用于识别和可视化所学功能
- Streamlit — Creating a web-app Streamlit —创建一个Web应用程序
Here’s a data flow diagram that provides a quick overview of the steps involved
这是一个数据流程图,提供了有关步骤的快速概述
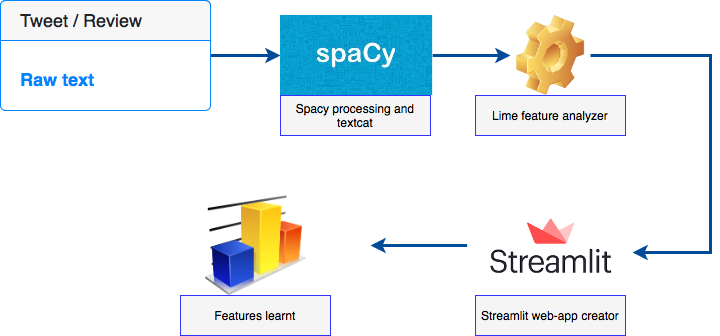
We’re only looking at the applying these components. For all the curious minds, I’m providing a couple of links if you wish to understand what lime is and how it works:
我们只看应用这些组件。 对于所有好奇的人,如果您想了解石灰是什么以及它如何工作,我会提供几个链接:
Blog by Abhishek Sharma — https://towardsdatascience.com/decrypting-your-machine-learning-model-using-lime-5adc035109b5
Abhishek Sharma撰写的博客— https://towardsdatascience.com/decrypting-your-machine-learning-model-using-lime-5adc035109b5
LIME Github — https://github.com/marcotcr/lime
LIME Github- https://github.com/marcotcr/lime
Blog by LIME’s author — https://homes.cs.washington.edu/~marcotcr/blog/lime/
石灰的作者博客- https://homes.cs.washington.edu/~marcotcr/blog/lime/
Original paper based on which LIME was built — https://arxiv.org/abs/1602.04938
根据原来的纸,上面LIME建- https://arxiv.org/abs/1602.04938
如何使用sentipy (How to use sentipy)
git clone the repo from https://github.com/sagard21/sentipy
git从https://github.com/sagard21/sentipy克隆存储库
- Create a new conda / virtual environment 创建一个新的conda /虚拟环境
Install sentipy by running the command
setup.py installon the terminal通过在终端上运行命令
setup.py install来安装sendipyOn the terminal run the following command to lauch the visualizer —
sentipy streamlit在终端上,运行以下命令启动可视化器-
sentipy streamlit
一瞥 (Glimpse)
Here are a few screenshots from the sentipy feature visualizer
这是一些来自“ sentipy功能”可视化器的屏幕截图
Image 1 — Text and number of features to visualize. Currently the max features is limited to 7
图像1-要可视化的特征的文本和数量。 目前,最大功能限制为7个
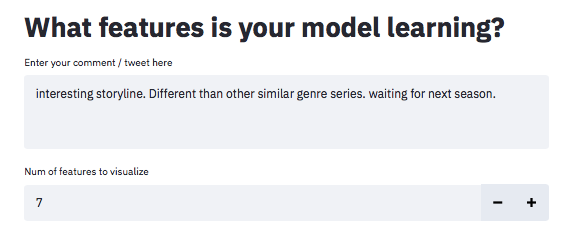
Image 2 — Predicted Class and Graphs
图像2 —预测的类和图
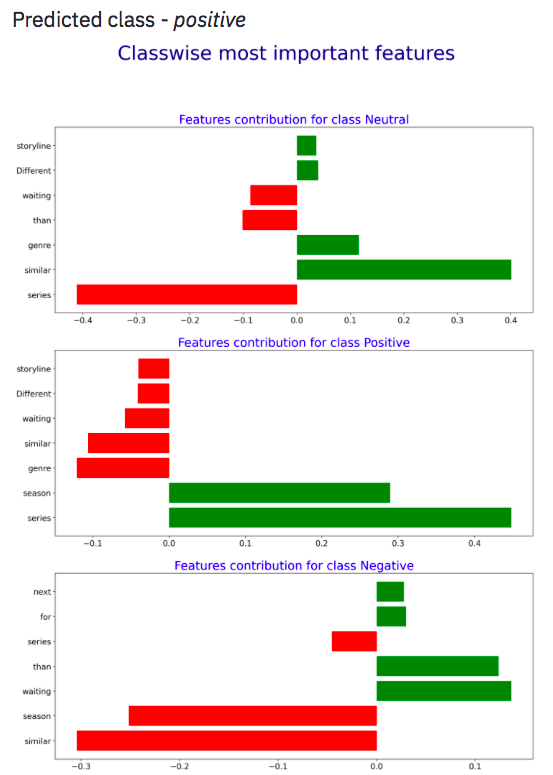
The graph above is from a review text that I asked my wife to write for a web-series she recently watched. Glad the classifier worked well :D
上图是来自我要求妻子为她最近观看的网络系列写的一篇评论文章。 很高兴分类器运作良好:D
最后的想法 (Final Thoughts)
sentipy is still a work in progress and a lot of progress is yet to be made. However the streamlit app MVP is ready and can be used to identify the features learnt by the base model. The readme file in the github lists some of the next set of improvements.
sentipy仍在进行中,尚未取得很多进展。 但是,精简的应用程序MVP已准备就绪,可用于识别基本模型学习的功能。 github中的自述文件列出了下一组改进。
If you have any thoughts on how this package can be made better, please leave a note. And your feedback is most welcome.
如果您对如何更好地改进此软件包有任何想法,请留下注释。 非常欢迎您提供反馈。
其他参考资料和来源 (Other References and Sources)
Spacy — https://spacy.io
Spacy- https: //spacy.io
Streamlit — https://www.streamlit.io
Streamlit — https://www.streamlit.io
Gain Access to Expert View — Subscribe to DDI Intel
获得访问专家视图的权限- 订阅DDI Intel
spark ml 文本分类

















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









