



ClickHouse官网: https://clickhouse.com/
ClickHouse 的优势和特点
列式存储:ClickHouse 采用列式存储,将数据按列存储在磁盘上,有助于压缩数据以及优化分析查询性能。
高性能:ClickHouse 针对大数据量和高吞吐量进行了优化,能够在秒级内查询和分析数十亿行数据。
分布式架构:支持水平扩展和集群部署,能够处理大规模数据,并提供高可用性。
并行处理:能够同时利用多个 CPU 核心进行并行计算,提高查询处理速度。
实时数据分析:ClickHouse 支持实时数据导入和实时查询,适用于需要快速分析实时数据的场景。
灵活的查询语言:支持 SQL 查询语言,提供了丰富的查询功能,包括聚合、分组、排序等。
可扩展性:可轻松集成到现有的数据处理管道中,支持多种数据格式。
ClickHouse 被广泛应用于数据分析领域,特别适用于大数据量下的实时分析和报表生成等场景。其高性能和高度优化的列式存储特性使其成为处理大规模数据分析任务的理想选择。
适用场景
ClickHouse 是一个针对大规模数据分析和时序数据处理优化的开源列式数据库管理系统。下面列举一些较为常用的场景:
时序数据分析:
ClickHouse 专注于时序数据,非常适用于处理时间序列数据,比如日志、传感器数据、监控数据等。
能够高效处理需要按时间序列进行快速查询和分析的大规模数据。
实时数据仓库(Real-time Data Warehouse):
ClickHouse 可以作为实时数据仓库,支持高并发、高吞吐量的查询,适用于快速响应实时数据的分析查询需求。
分布式分析:
适用于大规模数据分析场景,支持分布式部署和高度扩展性,能够处理PB级别的数据规模。
大规模数据分析和报表:
用于生成报表、数据可视化以及对海量数据进行查询和分析。
日志和事件数据处理:
适用于处理大量日志和事件数据,支持对日志和事件数据进行快速的聚合、筛选和分析。
高性能时序数据存储:
ClickHouse 的列式存储、数据压缩和查询优化,使其在存储大量时序数据时表现出色。
数据仓库存储:
作为数据仓库存储系统,适用于存储和分析大量结构化数据,支持复杂的数据查询。
大数据分析平台:
在大数据分析平台中作为存储层,为大数据计算提供支持。
ClickHouse 的基本概念
表(Table)
ClickHouse 中的表是数据存储的基本单元,使用列式存储。
列族(Column Family)
ClickHouse 的表可以按列族进行组织,相似类型的列可以组合在一起进行物理存储和压缩。
分区(Partition)
ClickHouse 支持根据分区键将数据分割成不同的分区,便于管理和查询。
引擎(Storage Engine)
ClickHouse 支持多种存储引擎,用于控制数据的存储方式和处理方法。
MergeTree
ClickHouse 最常用的存储引擎之一,专门用于处理时序数据的引擎。
MergeTree 索引(Index)
ClickHouse 使用 MergeTree 索引来加速查询操作。
#1、 拉取最新的ClickHouse镜像(推荐)
docker pull clickhouse/clickhouse-server
以下是个人镜像(版本是:25.8.4.13)
x86镜像
docker pull registry.cn-hangzhou.aliyuncs.com/qiluo-images/clickhouse-server:latest
arrch64版本
docker pull registry.cn-hangzhou.aliyuncs.com/qiluo-images/linux_arm64_clickhouse-server:latest
2、启动镜像
docker run \
-p 8123:8123 \
--name clickhouse-server \
--ulimit nofile=262144:262144 \
-e CLICKHOUSE_DB=test \
-e CLICKHOUSE_USER=root \
-e CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT=1 \
-e TZ=Asia/Shanghai \
-e CLICKHOUSE_PASSWORD=123456 \
-d registry.cn-hangzhou.aliyuncs.com/qiluo-images/clickhouse-server:latest
3.使用工具连接使用即可
参数解释:
-p 8123:8123:将主机的 8123 端口映射到容器内的 8123 端口,用于访问 ClickHouse 的 HTTP 查询服务。
–name clickhouse-server:为容器指定一个名称,方便后续管理和操作。
–ulimit nofile=262144:262144:设置容器内 ClickHouse 进程的文件打开数量限制,防止因文件描述符不足导致问题。
-e CLICKHOUSE_DB=test:设置 ClickHouse 的默认数据库名为 test。
-e CLICKHOUSE_USER=root:设置 ClickHouse 的默认管理员用户名为 root。
-e CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT=1:启用 ClickHouse 的访问控制功能,需要设置管理员账号密码才能进行操作。
-e TZ=Asia/Shanghai:设置容器的时区为上海时间,便于处理时间相关的数据。
-e CLICKHOUSE_PASSWORD=123456:设置 ClickHouse 的管理员账号密码为 123456。
-d clickhouse/clickhouse-server: 25.8.4.13:使用 clickhouse/clickhouse-server 镜像中的 ClickHouse 服务,并以后台方式运行容器。
生产环境
容器数据相关的文件夹需要挂载到宿主机上, 分别有:clickhouse的配置文件、数据文件、日志文件。进而实现Clickhouse数据持久化, 方便数据备份、迁移、恢复。
宿主机对应文件夹:
配置文件的文件夹:/data/clickhouse/conf
日志文件夹:/data/clickhouse/log
数据文件夹:/data/clickhouse/data
# 1.启动一个临时容器,为了拿配置文件
docker run --rm -d --name=temp-clickhouse-server registry.cn-hangzhou.aliyuncs.com/qiluo-images/clickhouse-server:latest
# 2.复制配置文件到宿主机
mkdir -p /data/clickhouse/conf
docker cp temp-clickhouse-server:/etc/clickhouse-server/users.xml /data/clickhouse/conf/users.xml
docker cp temp-clickhouse-server:/etc/clickhouse-server/config.xml /data/clickhouse/conf/config.xml
# 3.删除临时容器
docker rm -f temp-clickhouse-server
3.1.2 配置文件中添加用户
添加root用户,打开users.xml文件,把下面的内容复制到 标签中
<root>
<password_sha256_hex>8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92</password_sha256_hex>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</root>
其中8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92生成方式
echo -n "123456" | sha256sum | tr -d '-'
8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
如果是生产
echo -n "02dRPp5tqHFccf0H" | sha256sum | tr -d '-'
527169a482b9e967ed55f4c65ef2151a322bd581962d5941c0b3332aec184337
sudo docker run -d --name=clickhouse-server \
-p 8123:8123 \ # HTTP API端口(必需)
-p 9000:9000 \ # 原生TCP协议端口(强烈推荐)
-p 9004:9004 \ # PostgreSQL协议端口(推荐)
-p 9005:9005 \ # MySQL协议端口(可选)
-p 9009:9009 \ # 跨服务器复制端口(可选)
-p 9010:9010 \ # SSL/TLS原生协议端口(可选)
-p 9011:9011 \ # Prometheus监控端口(可选)
-e TZ=Asia/Shanghai \
--volume=/data/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml \
--volume=/data/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml \
--volume=/data/clickhouse/log:/var/log/clickhouse-server \
--volume=/data/clickhouse/data:/var/lib/clickhouse/ \
registry.cn-hangzhou.aliyuncs.com/qiluo-images/clickhouse-server:latest
或者
sudo docker run -d --name=clickhouse-server \
-p 8123:8123 \ # HTTP API端口
-p 9000:9000 \ # 原生TCP协议端口(支持SSL)
-p 9004:9004 \ # PostgreSQL协议端口
-p 9005:9005 \ # MySQL协议端口(可选)
-e TZ=Asia/Shanghai \
--volume=/data/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml \
--volume=/data/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml \
--volume=/data/clickhouse/log:/var/log/clickhouse-server \
--volume=/data/clickhouse/data:/var/lib/clickhouse/ \
registry.cn-hangzhou.aliyuncs.com/qiluo-images/clickhouse-server:latest
参数解释:
-d:将容器设置为在后台运行。
–name=clickhouse-server:给容器指定一个名称,这里是 “clickhouse-server”。
-p 8123:8123:将主机的 8123 端口映射到容器的 8123 端口,用于通过 HTTP 访问 ClickHouse 的查询服务。
-e TZ=Asia/Shanghai:设置容器的时区为亚洲/上海,以适应上海时区的时间。
–volume=/data/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml:将主机中 /data/clickhouse/conf/config.xml 文件映射到容器内的 /etc/clickhouse-server/config.xml 文件,这样可以提供自定义的 ClickHouse 配置文件。
–volume=/data/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml:将主机中 /data/clickhouse/conf/users.xml 文件映射到容器内的 /etc/clickhouse-server/users.xml 文件,这样可以提供自定义的用户认证信息。
–volume=/data/clickhouse/log:/var/log/clickhouse-server:将主机中 /data/clickhouse/log 目录映射到容器内的 /var/log/clickhouse-server 目录,用于存储 ClickHouse 的日志文件。
–volume=/data/clickhouse/data:/var/lib/clickhouse/:将主机中 /data/clickhouse/data 目录映射到容器内的 /var/lib/clickhouse/ 目录,用于存储 ClickHouse 的数据文件。
clickhouse/clickhouse-server:latest:基于 ClickHouse 25.8.4.13 版本的 Docker 镜像,用于启动 ClickHouse 服务。
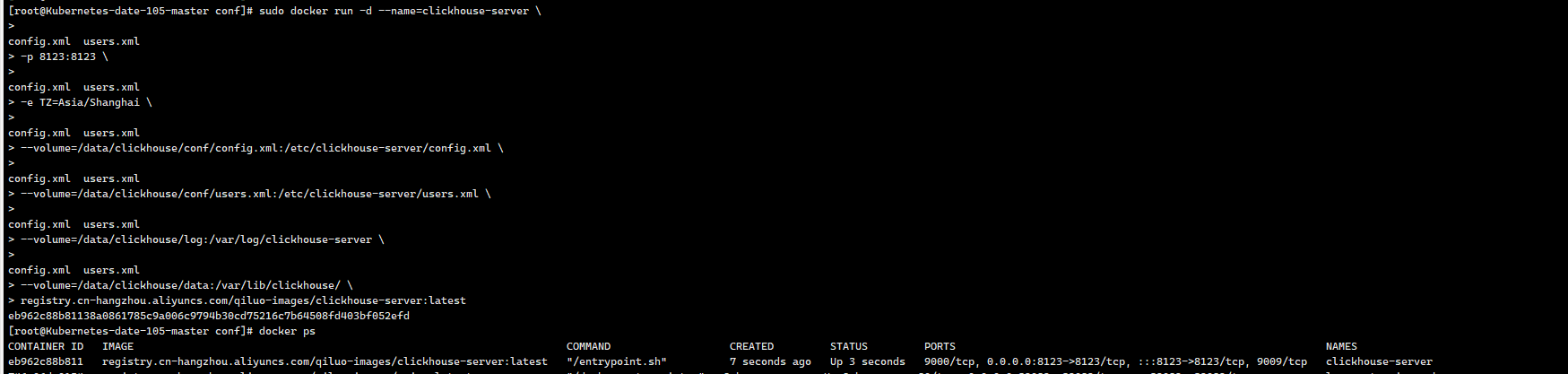
只需要放8123和9000端口即可
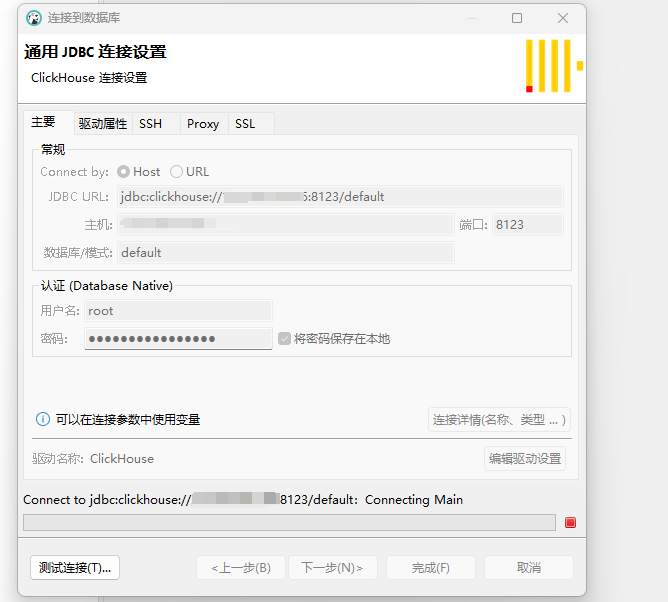
ClickHouse 与 Spring Boot 集成
ClickHouse JDBC 连接
ClickHouse 的基本操作
创建数据库和表、插入和查询数据
-- 创建数据库
```bash
CREATE DATABASE IF NOT EXISTS my_db;
– 创建表
CREATE TABLE IF NOT EXISTS my_db.my_table
(
event_date Date,
event_time DateTime,
user_id Int32,
clicks Int32
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(event_date)
ORDER BY (event_date, event_time);
– 插入数据
INSERT INTO my_db.my_table (event_date, event_time, user_id, clicks)
VALUES ('2023-12-31', '2023-12-31 23:59:59', 1, 10);
-- 查询数据
select * from my_db.my_table;
使用 MergeTree 引擎处理时序数据
在 ClickHouse 中,MergeTree 引擎非常适合处理时序数据,例如日志、性能指标数据、时间序列数据等。它是 ClickHouse 提供的一种用于存储有序数据并快速执行范围查询的引擎。以下是使用 MergeTree 引擎处理时序数据的示例:
创建带有 MergeTree 引擎的表
首先要创建一个带有 MergeTree 引擎的表。指定 ORDER BY 和 PARTITION BY 子句。
CREATE TABLE IF NOT EXISTS tb_metric(
timestamp DateTime,
value Float64
) ENGINE = MergeTree()
ORDER BY (timestamp)
PARTITION BY toYYYYMM(timestamp);
在这个示例中,创建了一个名为 tb_metric的表,包含 timestamp 和 value 两个字段。表使用 MergeTree() 引擎,按照 timestamp 字段进行排序,并按年份和月份进行分区。
插入时序数据
INSERT INTO your_table (timestamp, value)
VALUES ('2023-12-01 10:00:00', 25.5),
('2023-12-01 10:05:00', 26.2),
('2023-12-01 10:10:00', 24.8),
...
查询时序数据
使用 MergeTree 引擎后,可以执行范围查询以获取特定时间范围内的数据。
SELECT *
FROM tb_metric
WHERE timestamp BETWEEN '2023-12-01 00:00:00' AND '2023-12-01 23:59:59';
该语句会检索tb_metric 表中 ‘2023-12-01’ 这一天的所有数据,比如指标数据每分钟采集一次并进行存储,这个表的数据量会巨大,那么这个时候用此方式检索会比较快。
管理分区
在 ClickHouse 中,MergeTree 引擎支持对分区进行管理。分区管理可以根据时间范围、日期、月份等策略进行,以实现数据的有效存储和查询。以下是管理 MergeTree 表分区的基本操作:
创建带有分区的 MergeTree 表
和上面一样创建带有分区的 MergeTree 表,指定分区键和分区策略:
CREATE TABLE IF NOT EXISTS tb_metric(
timestamp DateTime,
value Float64
) ENGINE = MergeTree()
ORDER BY (timestamp)
PARTITION BY toYYYYMM(timestamp);
添加新分区
当数据到达新的时间范围时,需要为表添加新分区。ClickHouse 提供了 ALTER TABLE … ATTACH PARTITION 语句来添加新分区:
ALTER TABLE your_table ATTACH PARTITION 202312;
删除旧分区
当不再需要某个时间段内的数据时,可以使用 ALTER TABLE … DETACH PARTITION 语句删除旧分区:
ALTER TABLE your_table DETACH PARTITION 202301;
查询现有分区
要查看表中的所有分区,可以执行以下查询显示名为 tb_metric 的表的所有分区信息:
SELECT partition_id, partition
FROM system.parts
WHERE table = 'tb_metric';
合并分区
如果需要将两个分区合并为一个较大的分区以优化性能,可以使用 ALTER TABLE … FREEZE PARTITION 来合并分区:
ALTER TABLE tb_metric FREEZE PARTITION 202310, 202311;
可以将您的ClickHouse数据源配置转换为YAML格式如下:
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>
spring:
datasource:
url: jdbc:clickhouse://your_clickhouse_host:port/default
username: your_username
password: your_password
driver-class-name: ru.yandex.clickhouse.ClickHouseDriver
如果您使用的是较新版本的ClickHouse JDBC驱动,可能需要使用以下配置:
<dependency>
<groupId>com.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.9.2</version>
</dependency>
配置是以下
spring:
datasource:
url: jdbc:ch://your_clickhouse_host:port/default
username: your_username
password: your_password
driver-class-name: com.clickhouse.jdbc.ClickHouseDriver


















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











