




 本文介绍Python自然语言处理库NLTK的使用方法,包括文本分词、词性标注、实体识别及语法树构建等功能,并提供安装指南。
本文介绍Python自然语言处理库NLTK的使用方法,包括文本分词、词性标注、实体识别及语法树构建等功能,并提供安装指南。
Python :自然语言处理工具 NLTK
NLTK 是一个高效的Python 构建的开源项目,用来处理自然语言数据,分类、标记化、词干化、解析和语义推理
官网
github
NLTK实现的简单例子
给文本分词
import nltk
sentence = "At eight o'clock on Thursday morning. Steve Jobs in U.S.A"
tokens = nltk.word_tokenize(sentence)
print(tokens)
输出
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', '.']
标记词性
tagged = nltk.pos_tag(tokens)
print(tagged)
输出
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'NN'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'), ('.', '.')]
注:
# 词性缩写
# "NN" (noun)(名词)
# "VB" (verb)(动词)
# "JJ" (adjective)(形容词)
# "RB" (adverb)(副词)
# "PR" (pronoun)(代词)
# "DT" (determiner)(限定词)
# "PP" (preposition)(介词)
# "NO" (number)(数词)
# "CJ" (conjunction)(连词)
# "UH" (interjection)(插入语)
# "PT" (particle)(小品词)
# "." (punctuation)(标点)
# "X" (foreign word, abbreviation)(外来词,缩写)
识别已命名的实体
entities = nltk.chunk.ne_chunk(tagged)
print(entities)
输出
在这里插入代码片
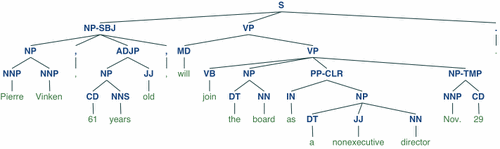
解析树
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
t.draw()
输出
在这里插入代码片
NLTK安装
要求Python 版本为2.7 或3.2 上
Mac / Unix
- 安装NLTK: 执行sudo pip install -u nltk
- 测试:执行python,进入python,进入python 后import nltk
Windows
http://pypi.python.org/pypi/nltk
NLTK附带了许多语料库,toy grammar以及训练模型等。完整的列表发布在:http://nltk.org/nltk_data/


















 6294
6294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











