




 本文详细介绍了Spark累加器的概念和用途,包括如何创建和使用数值类型的累加器,并通过示例展示了自定义累加器的实现方式。累加器在并行任务中提供了一种安全的计数或求和机制,适用于计数器和求和场景。虽然累加器在UI中便于任务进度追踪,但在RDD的惰性转换中要注意更新时机,以确保正确性。
本文详细介绍了Spark累加器的概念和用途,包括如何创建和使用数值类型的累加器,并通过示例展示了自定义累加器的实现方式。累加器在并行任务中提供了一种安全的计数或求和机制,适用于计数器和求和场景。虽然累加器在UI中便于任务进度追踪,但在RDD的惰性转换中要注意更新时机,以确保正确性。
本文内容来自官网 spark自定义累加器 的api
http://spark.apache.org/docs/2.1.1/api/scala/index.html#org.apache.spark.util.AccumulatorV2
累加器描述
http://spark.apache.org/docs/2.1.1/programming-guide.html#accumulators
累加器是仅通过关联和交换操作“添加”到的变量,因此可以有效地并行支持。它们可用于实现计数器(如MapReduce)或求和。Spark本身支持数值类型的累加器,程序员可以添加对新类型的支持。
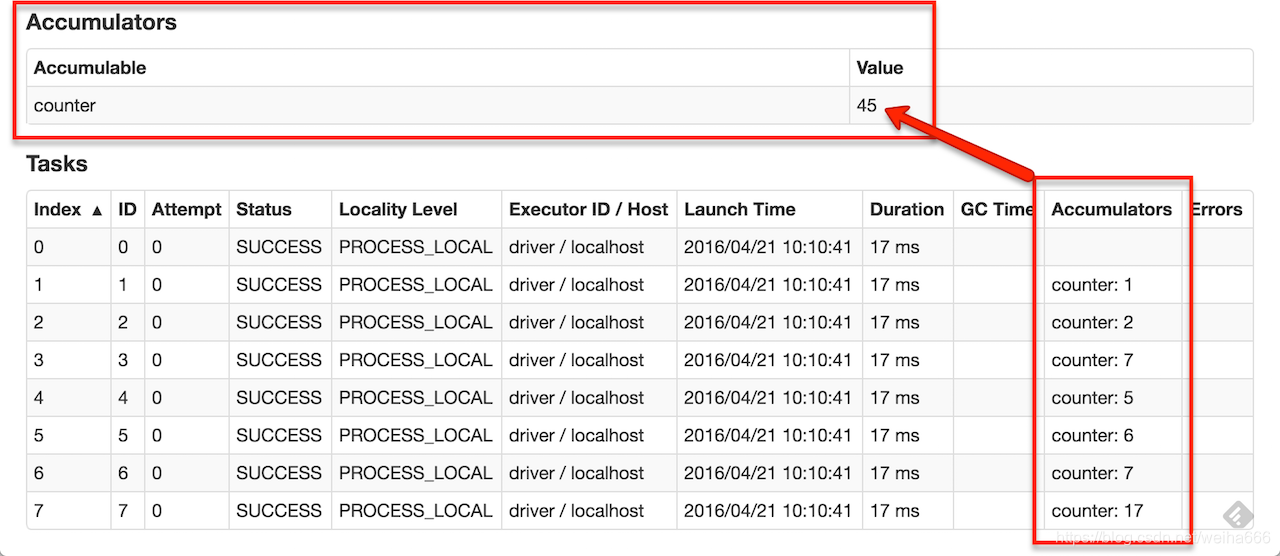
作为用户,可以创建命名或未命名的累加器。如下图所示,一个命名的累加器(在此实例计数器中)将显示在修改该累加器的阶段的web UI中。Spark在“Tasks”表中显示由任务修改的每个累加器的值。
在UI中跟踪累加器对于理解运行阶段的进度非常有用(注意:Python还不支持这一点)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









