






 本文深入探讨Java序列化机制,通过具体示例详细解析序列化过程中的关键步骤与内部原理,包括对象缓存、对象替换及不同类型对象的序列化处理。
本文深入探讨Java序列化机制,通过具体示例详细解析序列化过程中的关键步骤与内部原理,包括对象缓存、对象替换及不同类型对象的序列化处理。
周六小记
上班盼着周末,周六早上终于睡到了9点多起来。
现在是上班不想起来,周末睡不着。年纪大了,心里焦虑。
唯一缓解焦虑就是用所谓的努力来麻痹自己!
序列化源码学习
前面讨论了序列化的一些基本特性,传送门:
这里来学习一下jdk的序列化源码
普通的开头
还是以前面的一个例子开始,有一个Person类,实现了Serializable
public class Person implements Serializable {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}现在写个测试用例,把它先序列化一个实例到person.out文件中,然后反序列化
public class SerializableTest {
@Test
public void test1() {
serialize();
deSerialize();
}
private static void serialize() {
// 创建一个对象
Person person = new Person();
person.setName("张三");
try {
// 序列化到文件中
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("person.out"));
outputStream.writeObject(person);
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
private static void deSerialize() {
try {
// 从文件中反序列化
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("person.out"));
Person person = (Person) inputStream.readObject();
inputStream.close();
System.out.println("=================name:" + person.getName());
} catch (Exception e) {
e.printStackTrace();
}
}
}然后debug代码,开始序列化的源码之路
直接看writeObject方法
public final void writeObject(Object obj) throws IOException {
if (enableOverride) {
writeObjectOverride(obj);
return;
}
try {
writeObject0(obj, false);
} catch (IOException ex) {
if (depth == 0) {
writeFatalException(ex);
}
throw ex;
}
}这个方法会将对象写入流当中,我们可以看下方法注释,而且对于上面的例子来说,enableOverride为false,会走writeObject0(obj, false)分支;
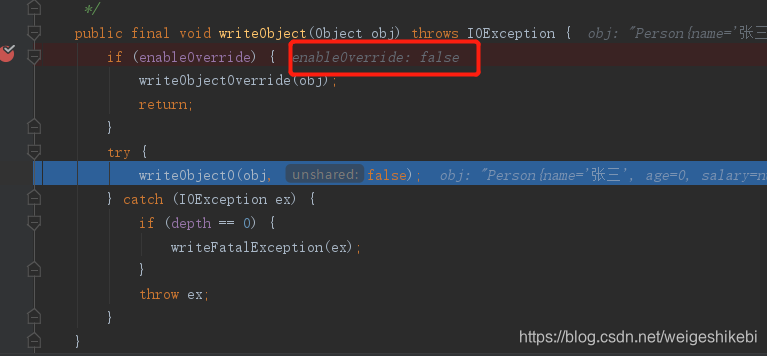
这是因为在构造器中默认了enableOverride=false,即不允许重写
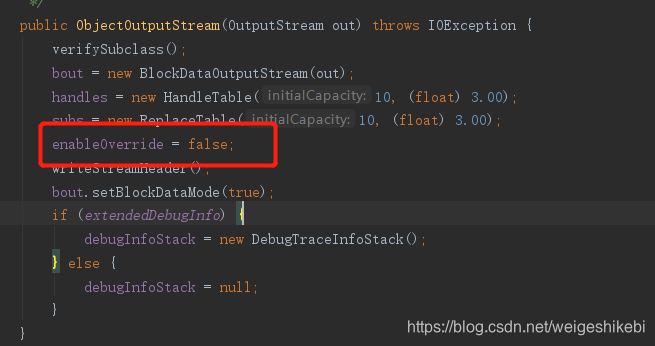
接下来看下真正的入口
/**
* Underlying writeObject/writeUnshared implementation.
*/
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
// handle previously written and non-replaceable objects
int h;
if ((obj = subs.lookup(obj)) == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
// check for replacement object
Object orig = obj;
Class<?> cl = obj.getClass();
ObjectStreamClass desc;
for (;;) {
// REMIND: skip this check for strings/arrays?
Class<?> repCl;
desc = ObjectStreamClass.lookup(cl, true);
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl)
{
break;
}
cl = repCl;
}
if (enableReplace) {
Object rep = replaceObject(obj);
if (rep != obj && rep != null) {
cl = rep.getClass();
desc = ObjectStreamClass.lookup(cl, true);
}
obj = rep;
}
// if object replaced, run through original checks a second time
if (obj != orig) {
subs.assign(orig, obj);
if (obj == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
}
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
depth--;
bout.setBlockDataMode(oldMode);
}
}这个方法做了以下几件事:
- 首先处理以前的写入和不可替换对象。这个以前的写入还没仔细研究
- 寻找指定对象的class元信息。
- 如果可以替换,则进行替换
- 如果对象被替换,则对原对象进行二次处理
- 处理剩下的场景
现在先看第一点
// handle previously written and non-replaceable objects
int h;
if ((obj = subs.lookup(obj)) == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}先说结论,例子里面的序列化代码是不会走到这些分支的,看下subs.lookup(obj)是啥
/**
* Looks up and returns replacement for given object. If no
* replacement is found, returns the lookup object itself.
*/
Object lookup(Object obj) {
int index = htab.lookup(obj);
return (index >= 0) ? reps[index] : obj;
}这个方法就是寻找指定对象的替换,如果找不到就返回自己。其实说白了就是将对象进行缓存,如果下次再序列化时,可以从缓存中取出而不用再次处理。比如上面的对象连续序列化2次debug,就会发现代码会走进去
else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
}

















 3975
3975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









