






 本文深入解析Linux系统中的负载概念,通过实例说明如何利用uptime、top和w命令监测系统负载,并探讨load值与CPU核数的关系,以及如何判断系统是否超负荷运行。
本文深入解析Linux系统中的负载概念,通过实例说明如何利用uptime、top和w命令监测系统负载,并探讨load值与CPU核数的关系,以及如何判断系统是否超负荷运行。
偶尔有load告警
今天线上偶尔报警
SYSTEM load15 当前时间的值2.525大于阈值2.5
平时对这一块关注不多,特地了解一下
如何查看load状况
可以通过uptime、top、w等命令查看load运行状况
uptime

分别表示:当前时间、系统已运行时间、当前登录用户的数量、最近5、10、15分钟内的平均负载
w

前面第一行表示的跟uptime一样:当前时间、系统已运行时间、当前登录用户的数量、最近5、10、15分钟内的平均负载
接下来的条目展示每个用户:登录名,tty 名,远程的(登录)主机,登录时间,空闲时间,JCPU,PCPU,以及当前进程的命令行。
top
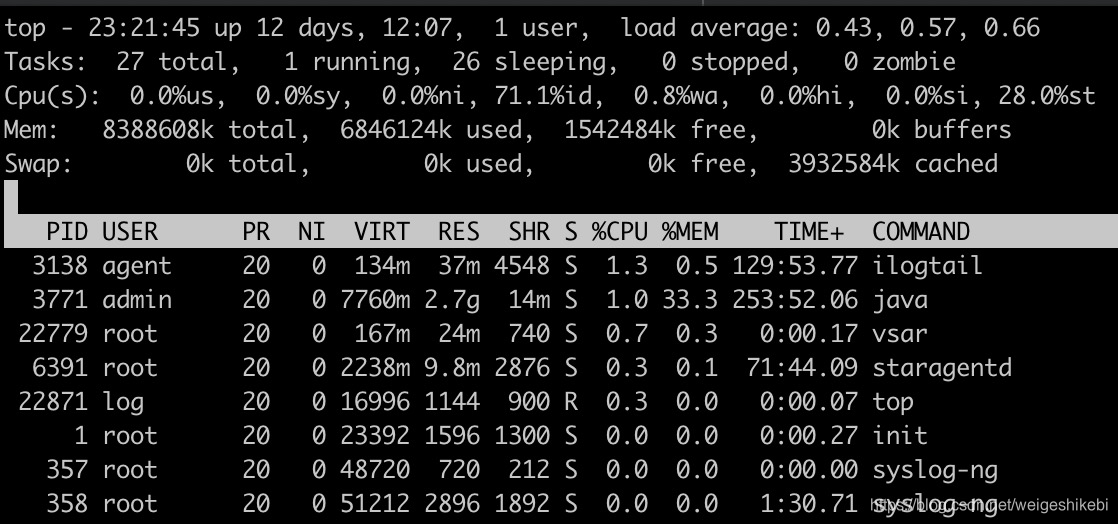
- 第一行系统运行时间和平均负载:当前时间、系统已运行时间、当前登录用户的数量、最近5、10、15分钟内的平均负载
-
第二行任务:任务的总数、运行中(running)的任务、休眠(sleeping)中的任务、停止(stopped)的任务、僵尸状态(zombie)的任务
-
第三行cpu状态
字段 字段释义 us user: 运行(未调整优先级的) 用户进程的CPU时间 sy system: 运行内核进程的CPU时间 ni niced:运行已调整优先级的用户进程的CPU时间 id idle:空闲时间 wa IO wait: 用于等待IO完成的CPU时间 hi 处理硬件中断的CPU时间 si 处理软件中断的CPU时间 st 这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的) - 第四行内存:全部可用内存、已使用内存、空闲内存、缓冲内存
- 第五行swap交换分区:全部、已使用、空闲和缓冲交换空间
- 第七行至N行:各进程任务的的状态监控
字段 释义 PID 进程ID,进程的唯一标识符 USER 进程所有者的实际用户名 PR 进程的调度优先级。这个字段的一些值是'rt'。这意味这这些进程运行在实时态。 NI 进程的nice值(优先级)。越小的值意味着越高的优先级。负值表示高优先级,正值表示低优先级 VIRT virtual memory usage 虚拟内存,进程使用的虚拟内存。进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量RES resident memory usage 常驻内存,驻留内存大小。驻留内存是任务使用的非交换物理内存大小。进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
1、进程当前使用的内存大小,但不包括swap out
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小SHR SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来S 这个是进程的状态。它有以下不同的值:
- D - 不可中断的睡眠态。
- R – 运行态
- S – 睡眠态
- T – 被跟踪或已停止
- Z – 僵尸态
%CPU 自从上一次更新时到现在任务所使用的CPU时间百分比。%CPU显示的是进程占用一个核的百分比,而不是整个cpu(N核)的百分比,有时候可能大于100,那是因为该进程启用了多线程占用了多个核心,所以有时候我们看该值得时候会超过100%,但不会超过总核数*100 %MEM 进程使用的可用物理内存百分比 TIME+ 任务启动后到现在所使用的全部CPU时间,精确到百分之一秒 COMMAND 运行进程所使用的命令。进程名称(命令名/命令行)
什么是load
load表示Linux的负载,上面一般显示的就是最近5、10、15分钟内的平均负载
我们怎么来理解Linux的负载呢? 打个比方
一核CPU对应我们一条公路,一个进程对应一辆汽车。在一条公路上,只有一辆汽车行驶,load=1没有出现拥堵的情况。一般load不超过1就没什么影响。
如果有两量汽车行驶在一条公路上行驶,会出现拥堵的情况,需要排队,这是load=2。
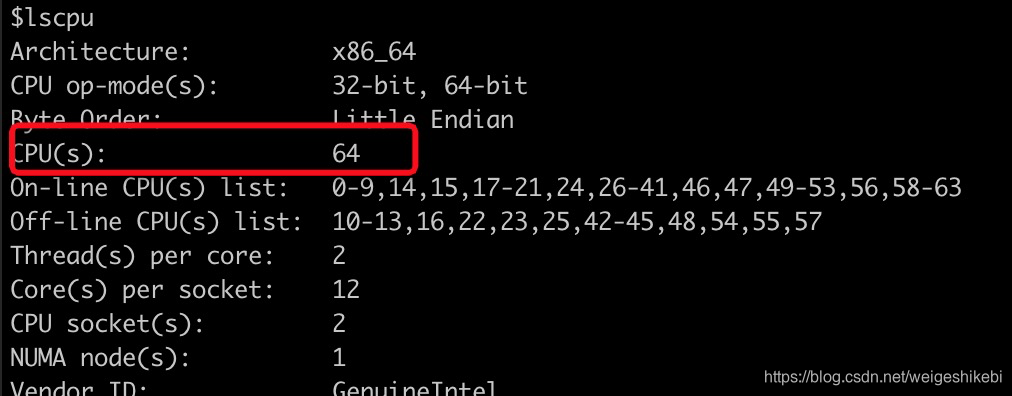
如下这台机器,用lscpu查看一下,CPU为64核,
当系统load=64时,系统cpu刚刚好在该机器cpu能处理的范围内;当load>64时,机器就超出负荷了,会有任务出现等待的情况。
计算公式
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值,然后用这个值和当前机器的cpu核数进行相除,得到的值
负载的好和坏
需要根据机器当前的进程数与CPU总核数的比值(process_cores_values)和CPU总核数(total_cores)来比较
- 当 process_cores_values <= total_cores 时,机器负载在CPU合理承受范围内
- 当 process_cores_values > total_cores 时,机器负载超过CPU承受范围,机器超负荷运行。
在执行top或者uptime的时候会有3个load的值,那根据哪个值做为我们判断依据呢?
还是着眼5分钟和15分钟的load值比较合适,因为1分钟的值有可能是个瞬间值,而5分钟或者15分钟的值是平均值,长时间负载高,机器肯定是需要排查问题的。
load= process/total_cpu_cores

















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









