






 本文介绍了一个使用PHP实现的简单网页爬虫,通过POST请求提交搜索关键词至百度,并抓取返回的搜索结果页面。代码中展示了如何利用cURL进行HTTPS请求,设置请求头,处理重定向以及获取和打印响应内容。
本文介绍了一个使用PHP实现的简单网页爬虫,通过POST请求提交搜索关键词至百度,并抓取返回的搜索结果页面。代码中展示了如何利用cURL进行HTTPS请求,设置请求头,处理重定向以及获取和打印响应内容。
文件目录
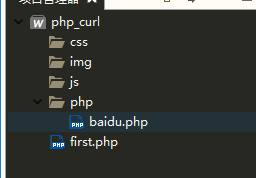
first.php
<!DOCTYPE html>
<html>
<body>
<form action="php/baidu.php" method="post">
<input type="text" name="search_text" id="search_text" value="请输入您要搜索的内容" />
<input type="submit" name="search" id="search" value="百度一下" />
</form>
</body>
</html>
baidu.php
<?php
echo $_POST['search_text'];
$url = "http://www.youdao.com/w/".$_POST['search_text']."/#keyfrom=dict2.top";//要爬取的网址
echo $url;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt ($ch, CURLOPT_HEADER,false);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
//设置用户代理(后缀为.top的网址不加这个获取不到内容。)
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.172 Safari/537.22");
//关闭直接输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
//加入重定向处理
curl_setopt($ch, CURLOPT_FOLLOWLOCATION ,1);
$response = curl_exec($ch);
echo curl_errno($ch);
echo($response);
curl_close($ch);
?>
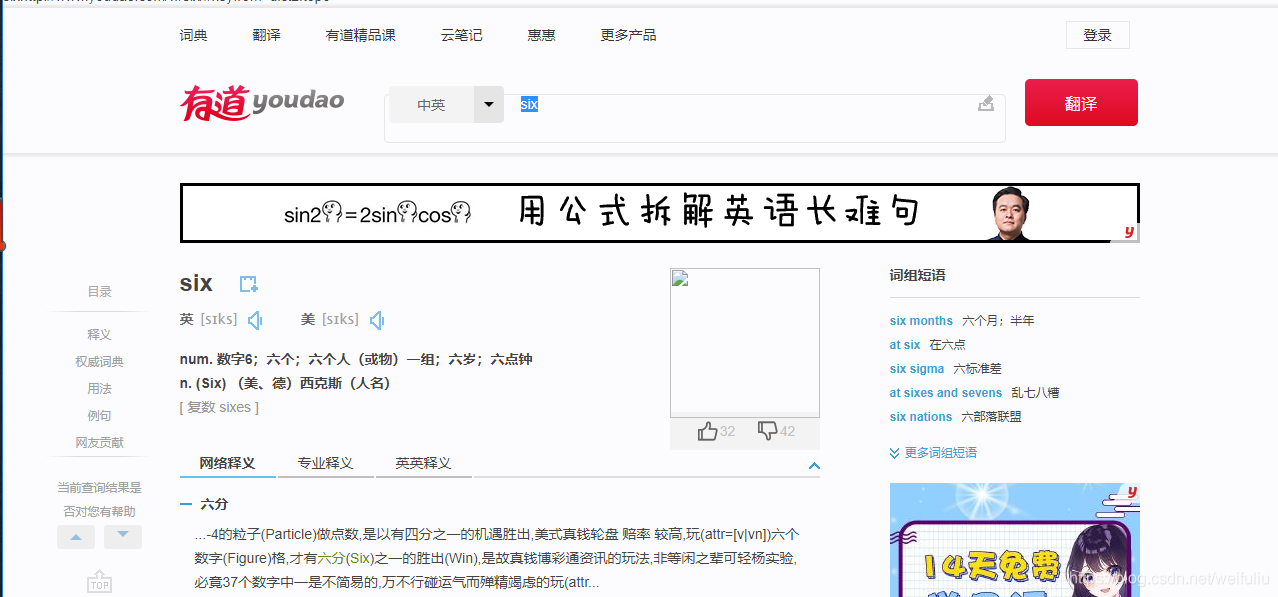
运行结果

















 5977
5977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









