




 本文围绕Python多线程展开,介绍了threading模块的常用方法、基本使用、多线程类创建及join方法。探讨了线程安全问题与互斥锁,分析了GIL全局解释器锁的原理、作用及与互斥锁的对比。还区分了计算密集型和IO密集型任务,介绍了生产者消费者模型,最后解决了多线程下print输出混乱问题。
本文围绕Python多线程展开,介绍了threading模块的常用方法、基本使用、多线程类创建及join方法。探讨了线程安全问题与互斥锁,分析了GIL全局解释器锁的原理、作用及与互斥锁的对比。还区分了计算密集型和IO密集型任务,介绍了生产者消费者模型,最后解决了多线程下print输出混乱问题。
threading模块
常用方法
threading.Thread(target=func[, args=(arg1, arg2...)]):创建线程对象target:方法名args:元组,如果参数只有一个,写法为args=(xxx,)
t.start():启动运行线程t.join():等待t线程执行完毕,再运行当前线程后面的代码threading.current_thread().getName():获取当前运行的线程名字- 主线程:
MainThread - 子线程:
Thread-{i},i = 1,2,…
- 主线程:
threading.enumerate():获取进程中正在运行的线程列表
基本使用
定义两个任务:
import threading
import time
def writing():
for i in range(5):
print('[{}] 正在写第 {} 页文字...'.format(
threading.current_thread().getName(), i
))
time.sleep(1)
def drawing():
for i in range(5):
print('[{}] 正在画第 {} 张画...'.format(
threading.current_thread().getName(), i
))
time.sleep(1)
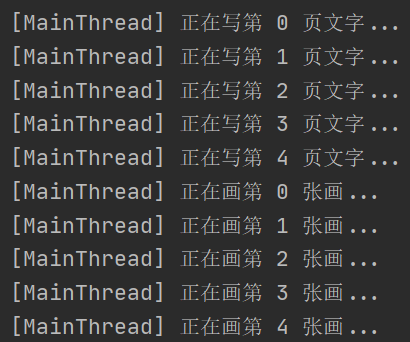
不使用线程,串行执行:
writing()
drawing()
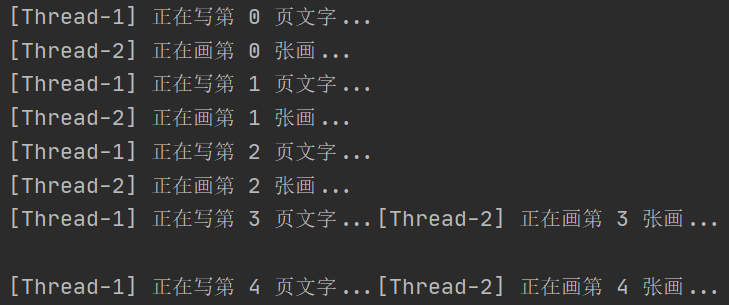
使用线程,并发执行:
threading.Thread(target=writing).start()
threading.Thread(target=drawing).start()
继承Thread创建多线程类
- 继承threading.Thread类,并重写run方法;
- 构造函数初始化后,必须调用start方法才能启动
import threading
import time
class WritingThread(threading.Thread):
def run(self):
for i in range(4):
print('[{}] 正在写代码 {} ...'.format(threading.current_thread().getName(), i))
time.sleep(1.0)
class DrawingThread(threading.Thread):
def run(self):
for i in range(4):
print('[{}] 正在画画 {} ...'.format(threading.current_thread().getName(), i))
time.sleep(1.0)
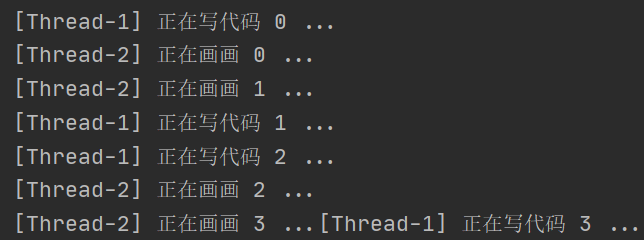
if __name__ == '__main__':
WritingThread().start()
DrawingThread().start()
join方法
可以做到等待子线程执行完毕再执行当前线程后边的代码
定义两个任务
import threading
import time
def writing():
for i in range(5):
print('[{}] 正在写第 {} 页文字...'.format(
threading.current_thread().getName(), i
))
time.sleep(1)
def drawing():
for i in range(5):
print('[{}] 正在画第 {} 张画...'.format(
threading.current_thread().getName(), i
))
time.sleep(1)
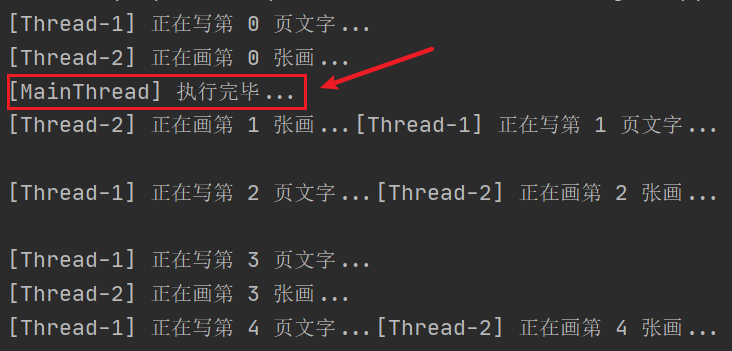
创建并运行两个线程,想要等待两个线程执行完毕后打印 执行完毕…
threading.Thread(target=writing).start()
threading.Thread(target=drawing).start()
print('[{}] 执行完毕...'.format(threading.current_thread().getName()))
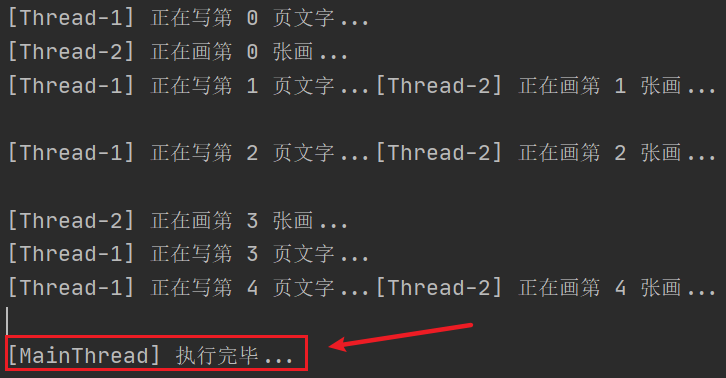
但是,运行结果可以看出,最终的打印语句并不是在最后,没有达到预期效果:
解决—join方法:
# 创建线程列表并追加线程对象
thread_list = list()
t1 = threading.Thread(target=writing)
t1.start()
thread_list.append(t1)
t2 = threading.Thread(target=drawing)
t2.start()
thread_list.append(t2)
# 等待执行完毕
for t in thread_list:
t.join()
# 全部线程结束后再执行
print('[{}] 执行完毕...'.format(threading.current_thread().getName()))
可以看到,此时达到了预期的运行效果
线程安全问题及互斥锁
共享数据的线程安全问题
在Python中,由于GIL存在,如果不进行特别耗时的IO或睡眠操作,就不存在线程安全问题
import time
import threading
# 全局变量
VALUE = 0
def add_value():
# 函数内部使用全局变量必须【global声明】
global VALUE
for _ in range(10):
tem = VALUE
time.sleep(0.1)
VALUE = tem + 1
if __name__ == '__main__':
start_time = time.time()
thread_list = list()
for i in range(100):
t = threading.Thread(target=add_value)
t.start()
thread_list.append(t)
# 让所有线程结束在执行主进程
for t in thread_list:
t.join()
print('程序运行使用时间: {:.2f}s'.format(time.time() - start_time))
print('最终VALUE = {}'.format(VALUE))

不是说同一时间只有一个线程在执行吗,为什么是10而不是1000?
- 第一个线程获取到获得的GIL锁运行线程绑定的函数,其他的线程等待GIL锁的释放才能运行…
- 函数中获取number的值为10,time.sleep()会让线程进入阻塞状态,这个时候会将GIL释放(关键点),其他的线程就会抢锁执行,都会在延时操作时释放掉锁,那么所有的的线程拿number的值为10
- 延时到期后,第一个线程再次获取GIL锁,将number的值设置为9,程序结束,释放GIL锁;其他的线程相继如此,最后所有线程的中number值都设置为9
GIL锁测试
将上面的示例代码删除time.sleep()
import time
import threading
# 全局变量
VALUE = 0
def add_value():
# 函数内部使用全局变量必须【global声明】
global VALUE
for _ in range(10):
tem = VALUE
VALUE = tem + 1
if __name__ == '__main__':
start_time = time.time()
thread_list = list()
for i in range(100):
t = threading.Thread(target=add_value)
t.start()
thread_list.append(t)
# 让所有线程结束在执行主进程
for t in thread_list:
t.join()
print('程序运行使用时间: {:.2f}s'.format(time.time() - start_time))
print('最终VALUE = {}'.format(VALUE))

- 同一时间只有一个线程在执行(线程执行函数速度快,直接执行完毕,给定时间与字节码没有超出,GIL锁没有中途释放)。
- 得到的VALUE是1000,结果是我们想要的
互斥锁
import time
import threading
# 全局变量
VALUE = 0
LOCK = threading.Lock()
def add_value():
# 函数内部使用全局变量必须【global声明】
global VALUE
for _ in range(10):
LOCK.acquire()
tem = VALUE
time.sleep(0.1)
VALUE = tem + 1
LOCK.release()
if __name__ == '__main__':
start_time = time.time()
thread_list = list()
for i in range(100):
t = threading.Thread(target=add_value)
t.start()
thread_list.append(t)
# 让所有线程结束在执行主进程
for t in thread_list:
t.join()
print('程序运行使用时间: {:.2f}s'.format(time.time() - start_time))
print('最终VALUE = {}'.format(VALUE))

- 第一个线程在运行时,先获取GIL锁,然后获取到互斥锁
- 运行到sleep线程变成阻塞态,释放GIL锁;第二个线程拿到了GIL锁执行到LOCK.acquire(),没有锁,线程进入阻塞态,释放GIL锁;其他的线程依旧如此,在同一个位置等待互斥锁的释放
- 当第一个线程sleep运行结束之后,重新进入就绪态,获取到GIL锁;
- 执行完后释放掉互斥锁,再释放掉GIL锁;其他线程取消阻塞,竞争互斥锁,依次执行完毕…程序由并发变成了串行,因此保证了共享数据的安全
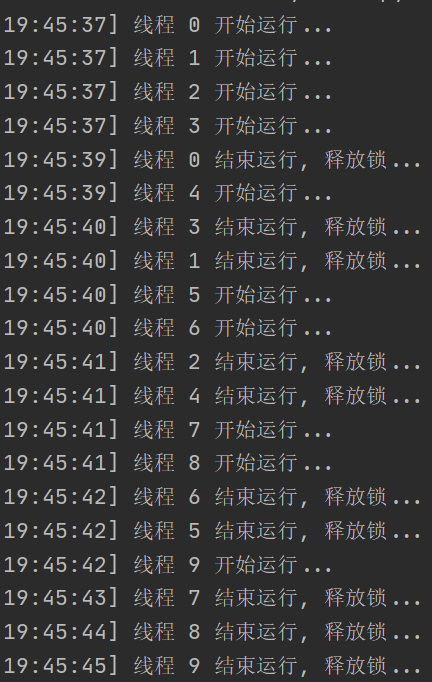
控制线程数量BoundedSemaphore
示例
# value表示每次最多执行的线程数
# 锁时机的原则: 上锁和解锁都在线程方法内的最开始一行和最后一行
LOCK = threading.BoundedSemaphore(value=4)
def task(num):
# 上锁acquire
LOCK.acquire()
print('[{}] 线程 {} 开始运行...'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), num))
# 随机睡眠
time.sleep(random.randint(2, 4))
print('[{}] 线程 {} 结束运行, 释放锁...'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), num))
# 注意: 一定要等线程执行结束再执行release!!! 否则就是无限线程
LOCK.release()
if __name__ == '__main__':
for i in range(10):
# 启动线程
threading.Thread(target=task, args=(i,)).start()
注意release时机
- 锁时机的原则: 上锁和解锁都在线程方法内的最开始一行和最后一行
- 调用
LOCK.acquire()一定是在线程方法内的最开始,LOCK.release()的时机一定是任务结束后!下面就是一个错误的示例:
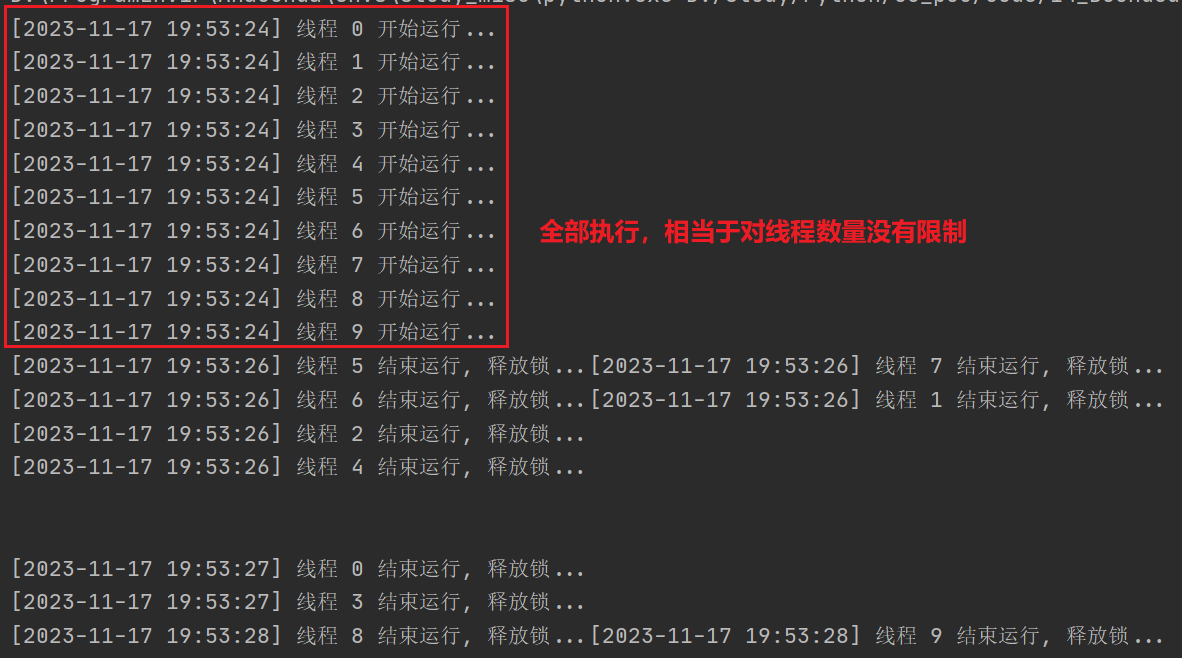
# value表示每次最多执行的线程数
# 锁时机的原则: 上锁和解锁都在线程方法内的最开始一行和最后一行
LOCK = threading.BoundedSemaphore(value=4)
def task(num):
print('[{}] 线程 {} 开始运行...'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), num))
# 随机睡眠
time.sleep(random.randint(2, 4))
print('[{}] 线程 {} 结束运行, 释放锁...'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), num))
if __name__ == '__main__':
for i in range(10):
# 错误: acquire不应该在这里调用
LOCK.acquire()
# 启动线程
threading.Thread(target=task, args=(i,)).start()
# 错误: release不应该在这里调用
LOCK.release()
运行效果如下,可以看到,10个线程同时启动,并没有做到对线程数量进行限制。后续一定要避免这种低级错误!
GIL全局解释器锁
简介
- Global Interpreter Lock,全局解释器锁
- 在CPython解释器中,GIL是一把互斥锁,用来阻止同一进程多个线程的同时执行
- GIL不是Python的特点,而是CPython解释器的特点
- 由于全局解释器锁的存在,在同一时间内,python解释器只能运行一个线程的代码。每个线程在调用cpython解释器之前, 需要先抢到GIL锁然后才能运行,这大大影响了python多线程的性能,而这个解释器锁由于历史原因,现在几乎无法消除。
为什么要有GIL
- 设计者为了规避类似内存管理这样的复杂的竞争风险问题(race condition)
- CPython大量使用C语言库,但大部分C语言库都不是原生"线程安全"的,因为线程安全会降低性能、增加复杂度
- CPython中,使用了引用计数。当引用计数为0时,CPython解释器会自动释放内存
- 如果有多个线程同时引用了一个变量,就会造成引用计数的竞争条件。如果发生了这种情况,可能会导致泄露的内存永远不会被释放,更严重的是对象的引用仍然存在的情况下错误地释放内存,导致Python程序崩溃或带来各种诡异的问题。因此引用计数变量需要在多个线程同时增加或减少时从竞争条件中得到保护
- 竞争条件(race condition):多个进程并发访问和操作同一数据,出现竞争的情况,执行结果与访问的特定顺序有关
- 假设1: 两个进程P1和P2共享了变量a,在某一执行时刻P1更新a为1;在另一时刻,P2更新a为2。因此两个任务竞争地写变量a,竞争的“失败者”(最后更新的进程)决定了变量a的最终值
- 假设2:两个进程P1和P2共享了变量a,在某一执行时刻P1更新a的计数引用为0,开始回收变量,释放内存;P2使用这个变量,但此时这个变量没有了,报错
GIL是如何工作的
-
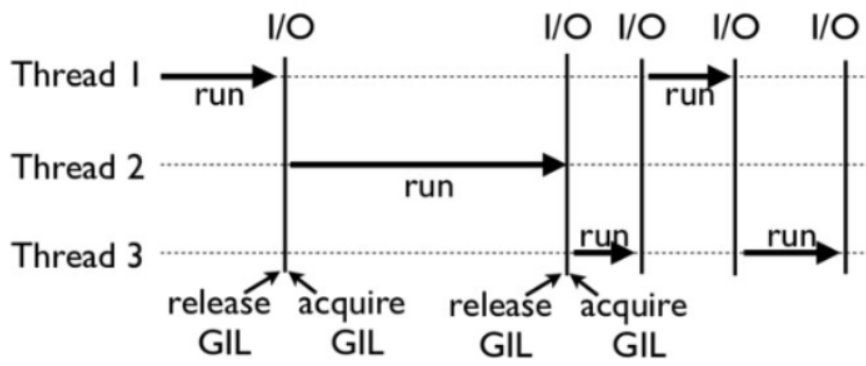
下面这张图就是一个GIL在Python程序中的工作示例。其中,线程1、2、3轮流执行, 每一个线程在执行, 都会先获取GIL锁,以阻止别的线程执行:
-
CPython中还有另一个机制check_interval,意思是CPython解释器会去轮询检查线程GIL的锁住情况。
每隔一段时间,Python解释器就会强制当前线程去释放GIL,这样别的线程才能有执行的机会。

-
释放GIL锁的情况:
- 任务没有执行完成
- 执行遇到I/O操作,会释放GIL,以允许别的线程开始利用资源
- 给定时间(python3为15毫秒)内没有执行完或执行了1000个bytecodes(字节码,早期为100)会释放GIL
-
主动释放锁的疑问?线程1没有执行完,释放锁给线程2执行,那么现在共有变量的问题好像又出现了…
-
GIL的设计, 主要是为了方便CPython解释器层面的编写者,而不是Python应用层面的程序员,作为Python的使用者,我们需要lock等工具来确保线程安全
GIL锁与互斥锁对比
详情 “多线程 > 线程安全问题及互斥锁”
- GIL锁:保证同一时刻只有一个线程能使用到cpu
- 互斥锁:多线程时,保证修改共享数据时进行有序的修改,不会产生数据修改混乱
计算密集型与IO密集型
由于 GIL 的存在, 即使是多个线程处理任务, 但是最终也只有一个线程在工作, 那么是不是多线程真的一点用处都没有呢?对于需要执行的任务来说,分为两种: 计算密集型、IO密集型
计算密集型CPU-Intensive
- 特点:要进行大量的计算,消耗CPU资源。比如计算圆周率、对视频进行高清解码等,全靠CPU的运算能力
- 计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
- 计算密集型任务由于主要消耗CPU资源,因此代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
- 假如一个计算密集型的任务需要10s的执行时间,总共有4个这样的任务。在4核及以上的情况下,
- 多进程:需要开启4个进程,但是4个CPU并行,最终只需要消耗10s多一点的时间(Python的效果会差一些)
- 多线程:只需要开1个进程,这个进程开启4个线程,开启线程所消耗的资源很少;但是由于最终执行是只有一个CPU可以工作,所以最终消耗 40s 多的时间
- 计算密集型
import time def func(): res = 1.1 # 模拟计算密集型 for i in range(1, 100000000): res *= i start_time = time.time() func() all_time = time.time() - start_time print('耗费的时间为: {:.2f}s'.format(all_time))

- 计算密集型使用多进程:
import time from multiprocessing import Process def func(): res = 1.1 # 模拟计算密集型 for i in range(1, 100000000): res *= i if __name__ == '__main__': # 定义一个列表存放进程对象 process_list = [] start_time = time.time() # 开始12个子进程 for i in range(12): p = Process(target=func) p.start() process_list.append(p) # 主进程等待子进程结束 for p in process_list: p.join() # 查看运行时间, 每开一个子进程, 时间就久一点 all_time = time.time() - start_time print('耗费的时间为: {:.2f}s'.format(all_time)) """ 自己电脑是 6大核加8小核 14个核心 开启的子进程数 花费的时间 14 7.39286470413208 12 6.670255661010742 10 5.984007358551025 ... 6 4.481975317001343 5 3.92647385597229 4 3.625216245651245 3 3.1252694129943848 2 2.837176561355591 1 2.513249158859253 """

- 计算密集型使用多线程
import time from threading import Thread def func(): res = 1.1 # 模拟计算密集型 for i in range(1, 100000000): res *= i if __name__ == '__main__': # 定义一个列表存放线程对象 thread_list = [] start_time = time.time() # 开始12个子线程 for i in range(12): t = Thread(target=func) t.start() thread_list.append(t) # 主进程等待子线程结束 for t in thread_list: t.join() all_time = time.time() - start_time print('耗费的时间为: {:.2f}s'.format(all_time))

IO密集型IO-Intensive
- 涉及到网络、磁盘IO的任务都是IO密集型任务
- 特点:CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)
- 对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。
- 常见的大部分任务都是IO密集型任务,比如Web应用。
- IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少。因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率高(代码量少)的语言,脚本语言是首选,C语言最差
- 假如有多个IO密集型的任务,CPU大多数时间是处于闲置状态,频繁的切换,
- 多进程:进程进行切换需要消耗大量资源
- 多线程:线程进行切换开销很小
- IO密集型使用多进程
import time from multiprocessing import Process def func(): # 模拟IO密集型 time.sleep(2) if __name__ == '__main__': # 定义一个列表存放进程对象 process_list = [] start_time = time.time() # 开始1000个子进程 for i in range(1000): p = Process(target=func) p.start() process_list.append(p) # 主进程等待子进程结束 for p in process_list: p.join() all_time = time.time() - start_time print('耗费的时间为: {:.2f}s'.format(all_time))

- IO密集型使用多线程
import time from threading import Thread def func(): # 模拟IO密集型 time.sleep(2) if __name__ == '__main__': # 定义一个列表存放线程对象 thread_list = [] start_time = time.time() # 开始1000个线程 for i in range(1000): t = Thread(target=func) t.start() thread_list.append(t) # 主进程等待子线程结束 for t in thread_list: t.join() all_time = time.time() - start_time print('耗费的时间为: {:.2f}s'.format(all_time))

总结:对于多进程、多线程其实都有其各自的应用场景。对于普通程序猿来说,开发的软件大多是IO密集型(WEB开发),所以即使存在GIL锁,开启多线程也是有优势的。并且,可以同时开启多进程与多线程,同时兼并二者的优点, 至于在何时切换成线程还是进程,则有专门的模块。
生产者消费者模型
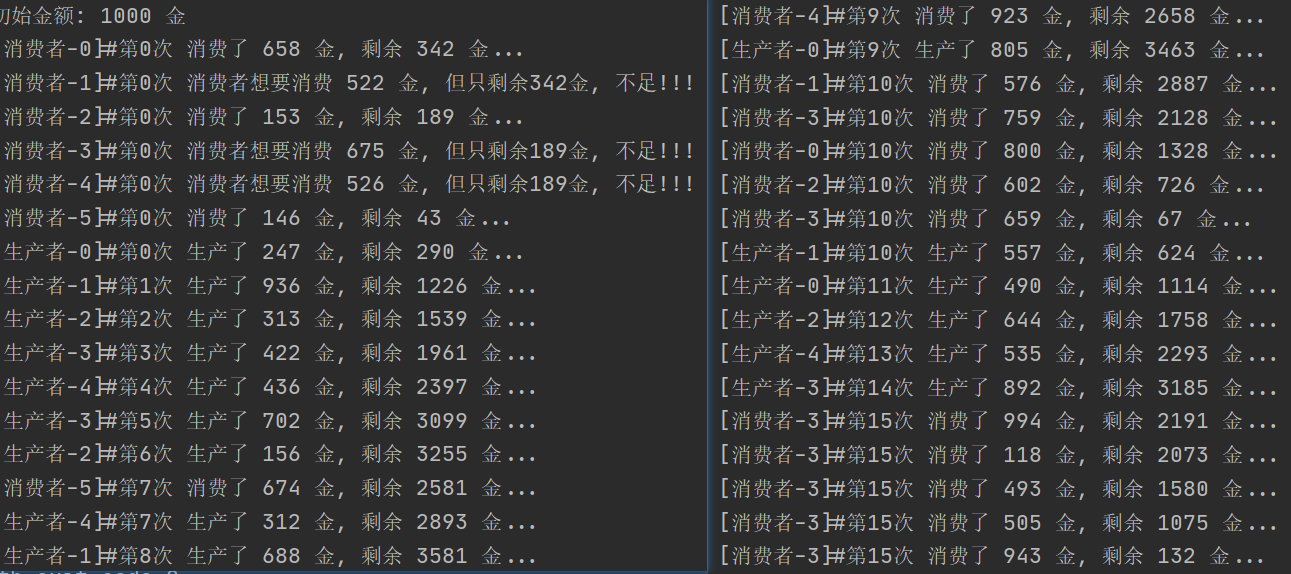
Lock版本
import random
import threading
import time
TIMES = 0
MONEY = 1000
LOCK = threading.Lock()
class Producer(threading.Thread):
'''生产金钱'''
def run(self):
global MONEY, TIMES
while TIMES <= 10:
money = random.randint(100, 1000)
LOCK.acquire()
MONEY += money
print('[{}]#第{}次 生产了 {} 金, 剩余 {} 金...'.format(
threading.current_thread().getName(), TIMES, money, MONEY
))
TIMES += 1
LOCK.release()
time.sleep(0.5)
class Consumer(threading.Thread):
'''消费金钱'''
def run(self):
global MONEY, TIMES
while True:
money = random.randint(100, 1000)
LOCK.acquire()
if MONEY >= money:
MONEY -= money
print('[{}]#第{}次 消费了 {} 金, 剩余 {} 金...'.format(
threading.current_thread().getName(), TIMES, money, MONEY
))
else:
if TIMES >= 10:
LOCK.release()
break
print('[{}]#第{}次 消费者想要消费 {} 金, 但只剩余{}金, 不足!!!'.format(
threading.current_thread().getName(), TIMES, money, MONEY
))
LOCK.release()
time.sleep(0.5)
if __name__ == '__main__':
print('初始金额: {} 金'.format(MONEY))
for i in range(6):
Consumer(name='消费者-{}'.format(i)).start()
for i in range(5):
Producer(name='生产者-{}'.format(i)).start()
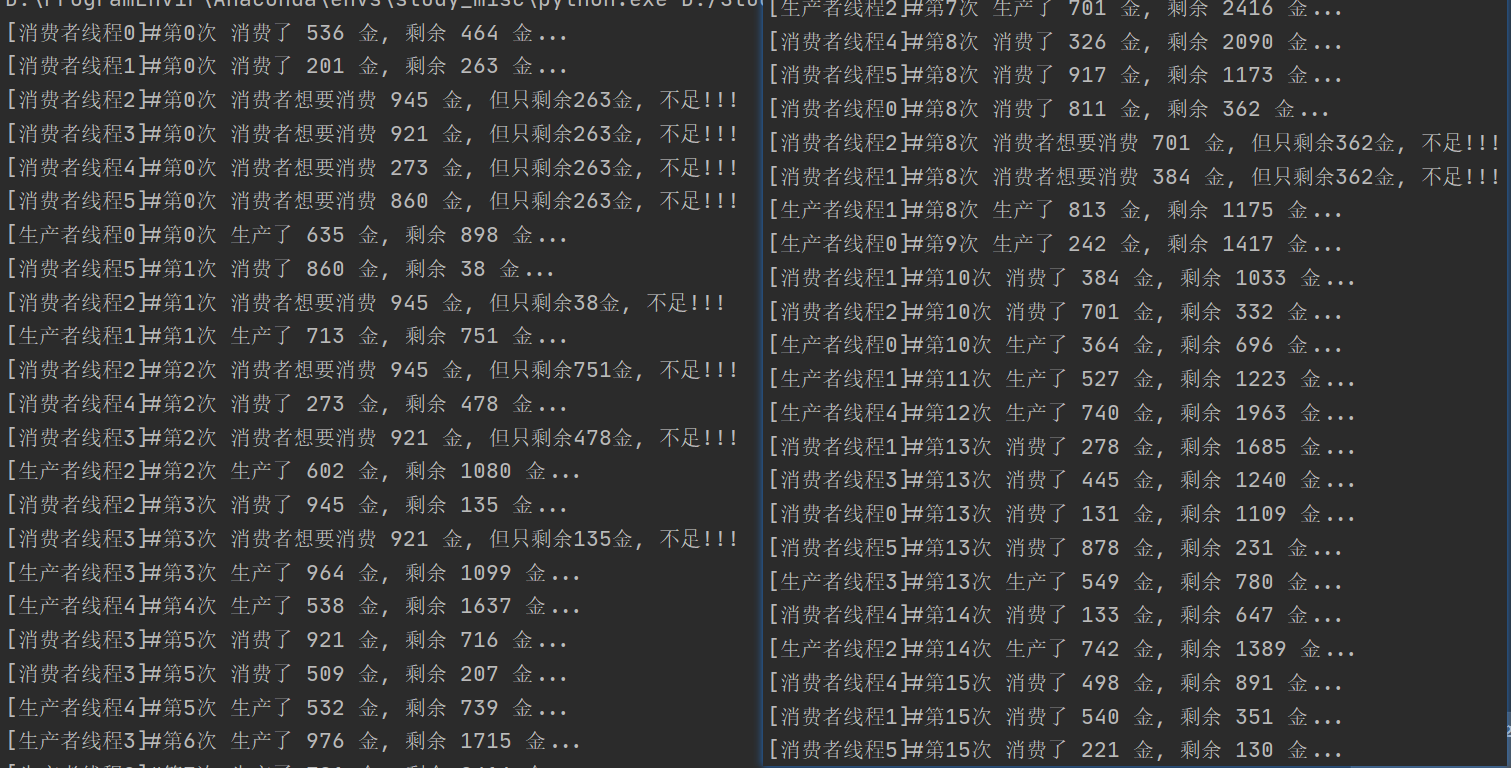
Condition版本
import random
import threading
import time
TIMES = 0
MONEY = 1000
LOCK = threading.Condition()
class Producer(threading.Thread):
""" 生产金钱 """
def run(self):
global MONEY, TIMES
while TIMES <= 10:
money = random.randint(100, 1000)
LOCK.acquire()
MONEY += money
print('[{}]#第{}次 生产了 {} 金, 剩余 {} 金...'.format(
threading.current_thread().getName(), TIMES, money, MONEY
))
TIMES += 1
# 唤醒所有在等待的线程, 必须在解锁release之前使用
LOCK.notify_all()
LOCK.release()
time.sleep(0.5)
class Consumer(threading.Thread):
""" 消费金钱 """
def run(self):
global MONEY, TIMES
while True:
money = random.randint(100, 1000)
LOCK.acquire()
while MONEY < money:
# 处于等待状态的线程
if TIMES >= 10:
LOCK.release()
return # 不能用break, 这样会只退出第二层while循环,而return回结束整个函数
print('[{}]#第{}次 消费者想要消费 {} 金, 但只剩余{}金, 不足!!!'.format(
threading.current_thread().getName(), TIMES, money, MONEY
))
LOCK.wait()
MONEY -= money
print('[{}]#第{}次 消费了 {} 金, 剩余 {} 金...'.format(
threading.current_thread().getName(), TIMES, money, MONEY
))
LOCK.release()
time.sleep(0.5)
if __name__ == '__main__':
for i in range(6):
Consumer(name='消费者线程{}'.format(i)).start()
for i in range(5):
Producer(name='生产者线程{}'.format(i)).start()
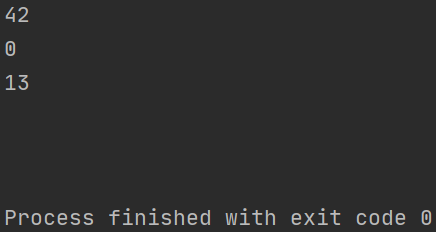
多线程下print输出挤在一行
问题描述:多线程中使用print函数,有时会出现格式混乱的情况,多个print输出挤在一行
import threading
import time
def func(i):
# 必须有一个io, 否则同一时间只有一个线程在执行, 有io后5个线程运行
time.sleep(0.1)
print(i)
if __name__ == '__main__':
for i in range(5):
threading.Thread(target=func, args=(i,)).start()
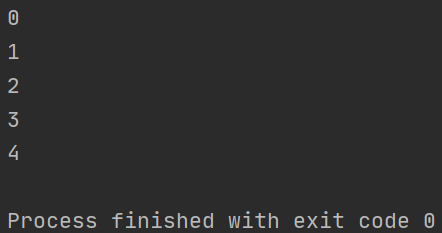
原因分析:有些print的操作不具备原子性,print的默认end参数为"\n",但end和print函数不是一起操作的,先打印value值,再打印end的参数。多线程中, 这就会造成刚打印value的值还未来得及打印end的参数,其他线程print了
解决:手动指定换行符\n, 不使用end参数换行,即print('{}\n'.format(i), end='')
import threading
import time
def func(i):
time.sleep(0.1)
print('{}\n'.format(i), end='')
if __name__ == '__main__':
for i in range(5):
threading.Thread(target=func, args=(i,)).start()


















 1896
1896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









