






 该系列教程介绍了大数据的流式计算,通过自来水厂的例子阐述实时计算系统。讲解了大数据离线计算与流式计算的区别,并详细探讨了ApacheStorm的体系结构。还提供了Zookeeper的单节点搭建及ApacheStorm的安装步骤,最后通过单词计数的Demo展示了流式计算的实际应用。
该系列教程介绍了大数据的流式计算,通过自来水厂的例子阐述实时计算系统。讲解了大数据离线计算与流式计算的区别,并详细探讨了ApacheStorm的体系结构。还提供了Zookeeper的单节点搭建及ApacheStorm的安装步骤,最后通过单词计数的Demo展示了流式计算的实际应用。
大数据的流式计算
共计2小时,视频480P 不太清晰, 自来水厂例子很好
大数据的流式计算
| 章节 | 地址 |
|---|---|
| (一)小例子 | https://www.bilibili.com/video/BV1uW4115715 |
| (二)大数据离线计算与流式计算的区别 | https://www.bilibili.com/video/BV13W41157BQ |
| (三) Apache Storm的体系结构 介绍 | https://www.bilibili.com/video/BV13W41157CY |
| (四) 实战:搭建 Zookeeper | https://www.bilibili.com/video/BV13W41157kS |
| (五) 实战:搭建Apache Storm | https://www.bilibili.com/video/BV13W41157Ub |
| (六)Demo: 单词计数wordcount | https://www.bilibili.com/video/BV13W41157Qn |
目录
一、什么是大数据流式计算(实时计算)
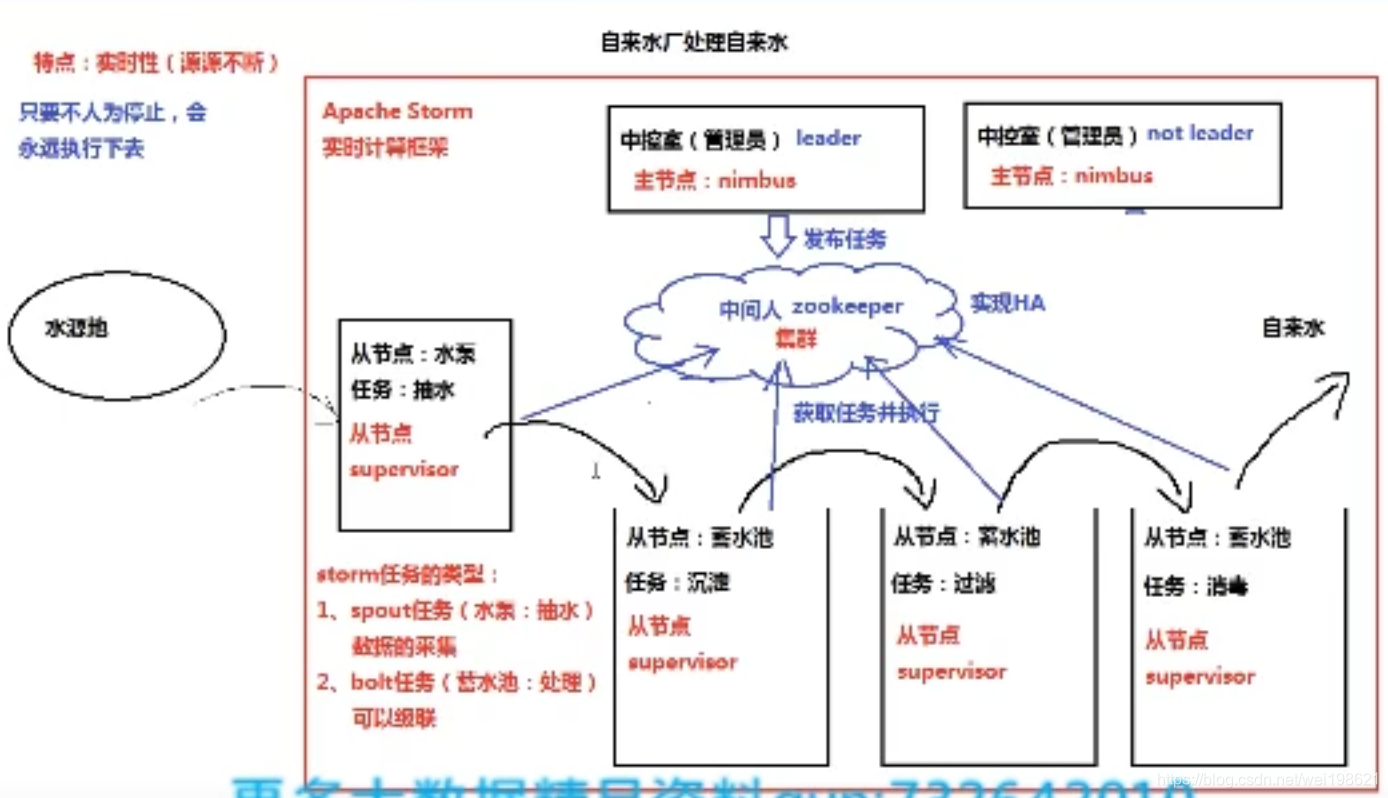
举例:自来水厂处理自来水—》典型:实时计算系统(流式计算)
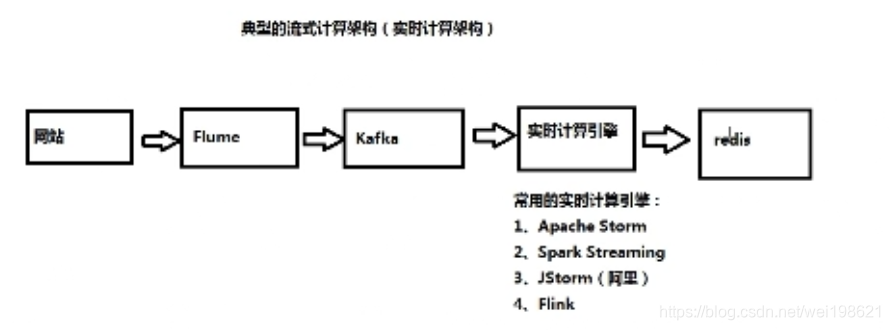
二、大数据离线机损与流式计算的区别
| 项目 | 离线计算 | 流式计算 |
|---|---|---|
| 代表技术 | MapReduce | Apache Storm / Spark Streaming / Flink |
| 数据采集 | Sqoop | Flume / Kafka |
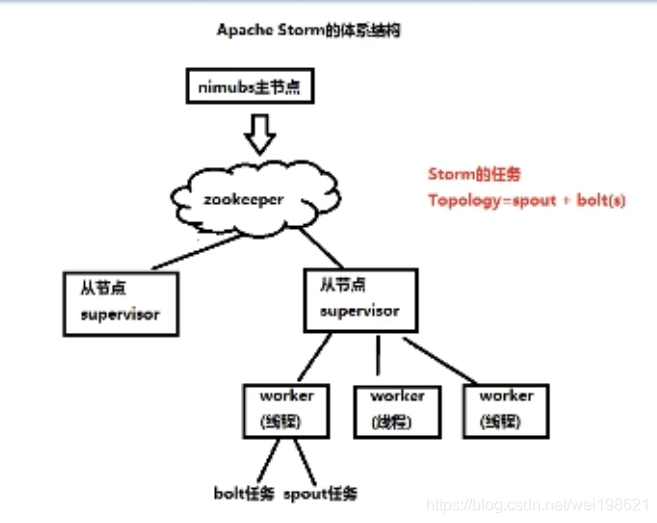
三、Apache Storm 体系结构(Spark Stoming)
实验环境:
linux Redhat 7.4
jdk 1.8
配置免密登录
主机名修改
关闭防火墙
四、实战zookeeper
1.zk 相当于一个数据库
2.建立一个单节点的zk
3.安装步骤3.1 解压
3.2设置环境变量
3.2 修改核心配置文件
五、实战 Apache Storm
安装步骤
1 解压
2设置环境变量
3 修改核心配置文件
六、Demo
大数据的流式计算 (一)小例子
大数据的流式计算 (一) 一个生活中的小例子 让你明白什么是大数据流式计算
https://www.bilibili.com/video/BV1uW4115715
storm 主节点: nimbus (光轮、灵气)
storm 从节点: supervisor (管理者、督导者、上司)supervisor任务一: spout 数据采集 (喷口、茶壶嘴、)
supervisor任务二: bolt 数据处理(组装、逃窜、门闩、插销)
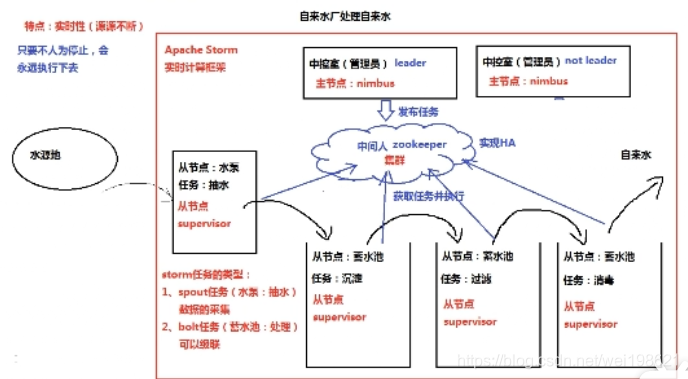
大数据的流式计算(二)大数据离线计算与流式计算的区别
https://www.bilibili.com/video/BV13W41157BQ
大数据的流式计算(三) Apache Storm的体系结构 介绍
https://www.bilibili.com/video/BV13W41157CY
大数据的流式计算 四 实战:搭建 Zookeeper
https://www.bilibili.com/video/BV13W41157kS
zookeeper 3.4.10
zk 默认使用 2181 端口
大数据的流式计算(五) 实战:搭建Apache Storm
参考: linux centos 7.6 安装 Apache Storm1.2.3
https://blog.youkuaiyun.com/wei198621/article/details/115449855
大数据的流式计算(六 )流式计算中的 Demo: 单词计数wordcount
https://www.bilibili.com/video/BV13W41157Qn


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









