




编程不良人原版笔记 — https://blog.youkuaiyun.com/wei198621/article/details/111280555
part 01 hadoop 集群的搭建 – https://blog.youkuaiyun.com/wei198621/article/details/111167560
part 02 mapreduce 的学习 – https://blog.youkuaiyun.com/wei198621/article/details/111411463
相关笔记下载地址 ( 很少的费用 带来很多的收获 支持一下自己技术上的进步 支持一下陈兄 )
https://www.baizhiedu.xin/front/index#/main
Hadoop 从入门到精通----编程不良人 ( 25 小时 )
https://www.bilibili.com/video/BV17E411g7F2
java hdfs 操作hdfs库
https://github.com/wei198621/hdfs_by_baizhi
简介
hadoop 官网
http://hadoop.apache.org/
文档下载地址
https://hadoop.apache.org/docs/r2.10.1/
https://hadoop.apache.org/docs/r2.9.2/
配置项下载地址
core-site.xml
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
hdfs-site.xml
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
yarn 简单分布式创建
对应视频
https://www.bilibili.com/video/BV17E411g7F2?p=19
搭建 yarn 分布式集群步骤
1. 集群规划
三台机器
192.168.121.215 hadoop15 NameNode DataNode NodeManager
192.168.121.216 hadoop16 DataNode ResourceManager NodeManager
192.168.121.217 hadoop17 DataNode NodeManager
2. 准备机器
-------------------- 此步骤在vmware上面操作-------------------------
a. 修改ip地址 vim /etc/sysconfig/network-scripts/ifcfg-ens33
192.168.121.215 (216、217)
systemctl restart network --- 修改网卡ip后要重启网路
[leo@hadoop1 ~]$ su root
[root@hadoop1 leo]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop1 leo]# ping 192.168.121.215 --- 修改保存后,没有生效
[root@hadoop1 leo]# systemctl restart network
[root@hadoop1 leo]# ping 192.168.121.215 --- 执行成功ping通
------------------此步骤及以下在serurityCRT上面操作 -----------------------
b. 修改主机名 vim /etc/hostname
hadoop15 (16,17)
reboot --- 修改主机名需要重启机器
c. 配置主机名ip 映射关系 vim /etc/hosts --- 此修改无需重启等操作
192.168.121.215 hadoop15
192.168.121.216 hadoop16
192.168.121.217 hadoop17
d. 配置 NameNode所在节点215 免密登录 215 216 217
配置 ResourceManager所在节点216 免密登录 215 216 217
(215) ssh-keygen ssh-copy-id hadoop15 (16,17)
(216) ssh-keygen ssh-copy-id hadoop15 (16,17)
(215) [root@hadoop15 ~]# ssh hadoop16 --- 如果可以免密登录说明配置成功
e. 配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_251
export HADOOP_HOME=/root/hadoop-2.9.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
3. hadoop 相关配置
tar -zxvf hadoop-2.9.2.tar.gz
hadoop-env.sh ----- 基本的JAVA_HOME hdfs yarn 都要用
[root@hadoop15 ~]# echo $JAVA_HOME
/usr/java/jdk1.8.0_251
[root@hadoop15 ~]# vim /root/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
export JAVA_HOME=${JAVA_HOME} -- 修改此处为
export JAVA_HOME=/usr/java/jdk1.8.0_251
core-site.xml ---- hdfs相关
<configuration>
</configuration>
修改为
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop15:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.9.2/data</value>
</property>
</configuration>
hdfs-site.xml ---- hdfs相关 --- 无需修改
yarn-site.xml ---- yarn
[root@hadoop15 ~]# vim /root/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop16</value> ----- 自己选定的yarn的resourceManager节点
</property>
</configuration>
mapred-site.xml ---- yarn (目录下没有此文件有对应的模板文件需要执行copy命令)
[root@hadoop15 ~]# cp /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<configuration>
</configuration>
---修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves ----- 基本的映射 hdfs yarn 都要用
[root@hadoop15 hadoop]# vim /root/hadoop-2.9.2/etc/hadoop/slaves
hadoop15
hadoop16
hadoop17
~
4. hadoop安装步骤 (上面已经有介绍此为总结)
a. 每台机器上面解压 hadoop
tar -zxvf hadoop-2.9.2.tar.gz
b.具体修改相关配置
hadoop-env.sh ----- 基本的JAVA_HOME hdfs yarn 都要用
core-site.xml ---- hdfs相关
hdfs-site.xml ---- hdfs相关
maped-site.xml ---- yarn
yarn-site.xml ---- yarn
slaves ----- 基本的映射 hdfs yarn 都要用
5. 将215 上面修改好的配置文件 同步到 216 217
[root@hadoop15 hadoop]# scp -r /root/hadoop-2.9.2/etc/hadoop/ root@hadoop16:/root/hadoop-2.9.2/etc/
[root@hadoop15 hadoop]# scp -r /root/hadoop-2.9.2/etc/hadoop/ root@hadoop17:/root/hadoop-2.9.2/etc/
------ 到 16 17 上,看最新时间有变化了,说明同步成功
[root@hadoop16 hadoop]# ll /root/hadoop-2.9.2/etc/hadoop/
[root@hadoop17 hadoop]# ll /root/hadoop-2.9.2/etc/hadoop/
6. 格式化NameNode节点 (在hdfs的namenode节点15上面执行)
reboot 15,16,17 重启机器让之前配置的 core-site.xml 等生效
hdfs namenode -format
[root@hadoop15 hadoop]# hdfs namenode -fromat
[root@hadoop15 hadoop]# jps -- 没有多余进程启动
[root@hadoop16 hadoop]# jps -- 没有多余进程启动
[root@hadoop17 hadoop]# jps -- 没有多余进程启动
15 机器上面会生成 /root/hadoop-2.9.2/data 这个目录,表示成功这行format
16 17 不会有此目录
7. 启动 hdfs yarn
start-dfs.sh --- 可以在 namenode datanode 的任意节点启动,一般选择在namenode 节点启动
[root@hadoop15 ~]# jps
8997 SecondaryNameNode
9209 Jps
8590 NameNode
8767 DataNode
[root@hadoop16 ~]# jps
8391 DataNode
8777 Jps
[root@hadoop17 ~]# jps
8391 DataNode
8777 Jps
start-yarn.sh --- 16 节点上启动
[root@hadoop15 ~]# jps
10032 Jps
8997 SecondaryNameNode
9625 NodeManager
8590 NameNode
8767 DataNode
[root@hadoop16 ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-resourcemanager-hadoop16.out
hadoop17: starting nodemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop17.out
hadoop15: starting nodemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop15.out
hadoop16: starting nodemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop16.out
[root@hadoop16 ~]# jps
9239 NodeManager
9704 Jps
8462 DataNode
9103 ResourceManager
[root@hadoop17 ~]# jps
9636 Jps
8391 DataNode
9048 NodeManager
8. 验证配置是否成功
hdfs dfs -put /etc/profile /profile20201220
http://192.168.121.215:50070 ----hdfs
http://192.168.121.216:8088 ----yarn


Map Reduce 的第一个程序 WordCount
mapreduce中数据类型
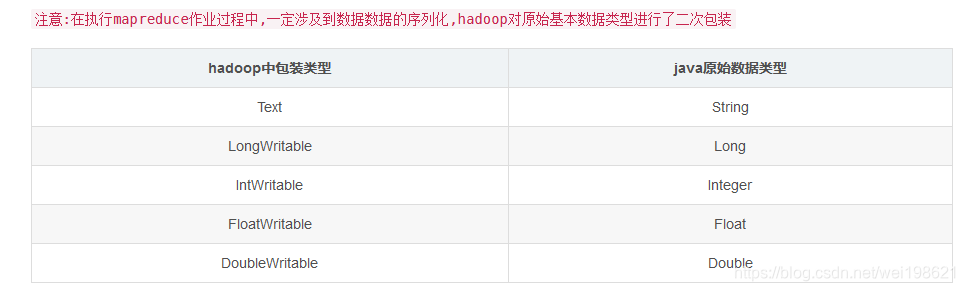 还有: NullWritable 这个类型
还有: NullWritable 这个类型
流程示意图

pom 文件
<properties>
<hadoop.version>2.9.2</hadoop.version>
</properties>
<dependencies>
<!-- 01 hadoop公共依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- 02 hadoop client (hdfs 依赖 ) -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- 03 map reduce 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.5.1</version>
</dependency>
<!-- 04 junit log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
准备基础数据
[root@hadoop15 ~]# mkdir hadoopdata
[root@hadoop15 ~]# cd hadoopdata/
[root@hadoop15 hadoopdata]# mkdir wordcount
[root@hadoop15 hadoopdata]# cd wordcount/
[root@hadoop15 wordcount]# pwd
/root/hadoopdata/wordcount //数据路径
[root@hadoop15 wordcount]# touch data //将数据放到这个目录
[root@hadoop15 wordcount]# vim data //查看数据
anghuihui wuhui zhainingning
zhangran songshen wangxuan
zhanglian zhangpengfei lichao
weilei liangbinchang huyunlong
zhouyu liujiyu qinchong
zhangsan lisi wangwu
chensubo zhanglian huyunlong songxin
zhangsan lisi wangwu
zhangran zhaoning wuhui zhanglian
zhouyu zhangsan lisi wangwu zhangsan lisi wangwu
zhangsan lisi wangwu ziyangzhao yaobanghu shaoqili
编码思路
package com.tiza.leo.mapreduct.wordcount;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* Author: tz_wl
* Date: 2020/12/21 15:01
* Content:
*/
public class WordCountJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new WordCountJob(),args);
}
// org.apache.hadoop.util.Tool 的方法
public int run(String[] strings) throws Exception {
// 1 创建job
// 2 设置inputformat
// 3 设置map阶段
// 4 设置shuffle 阶段 (默认无需配置)
// 5 设置reduce 阶段
// 6 设置 output Formate 注意:要求结果目录不能存在
// 7 提交job作业
//
return 0;
}
}
编码详情
01 WordCountMap
package com.tiza.leo.mapreduct.wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Author: tz_wl
* Date: 2020/12/21 15:54
* Content:
*
*
* // 1 创建job //设置数据输入路径
// 2 设置inputformat 原始数据 zhangsan lisi wangwu --第一行
zhangsan --第二行
// 3 设置map阶段 zhangsan 1
lisi 1
wangwu 1
zhangsan 1
// 4 设置shuffle 阶段 (默认无需配置) zhangsan [1,1]
lisi 1
wangwu 1
// 5 设置reduce 阶段 zhangsan 2
lisi 1
wangwu 1
// 6 设置 output Formate // 设置数据输出路径 注意:要求结果目录不能存在
// 7 提交job作业
*
*/
public class WordCountMap extends Mapper<LongWritable,Text,Text,LongWritable> {
/**
*
* @param key 没有使用 (原始数据的字符偏移量,作为key )
* @param value 读入的一行数据
* @param context 上下文
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] keys = value.toString().split(" ");
for (String word : keys) {
context.write(new Text(word),new LongWritable(1));
}
//super.map(key, value, context);
}
}
02 WordCountReduce
package com.tiza.leo.mapreduct.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Author: tz_wl
* Date: 2020/12/21 15:54
* Content:
*
* // 1 创建job //设置数据输入路径
// 2 设置inputformat 原始数据 zhangsan lisi wangwu --第一行
zhangsan --第二行
// 3 设置map阶段 zhangsan 1
lisi 1
wangwu 1
zhangsan 1
// 4 设置shuffle 阶段 (默认无需配置) zhangsan [1,1]
lisi 1
wangwu 1
// 5 设置reduce 阶段 zhangsan 2
lisi 1
wangwu 1
// 6 设置 output Formate // 设置数据输出路径 注意:要求结果目录不能存在
// 7 提交job作业
*
*/
public class WordCountReduce extends Reducer<Text,LongWritable,Text,LongWritable> {
/**
*
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (LongWritable value : values) {
sum+=value.get();
}
context.write(key,new LongWritable(sum));
//super.reduce(key, values, context);
}
}
03 WordCountJob
package com.tiza.leo.mapreduct.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* Author: tz_wl
* Date: 2020/12/21 15:01
* Content:
*/
public class WordCountJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new WordCountJob(),args);
}
/*
// 1 创建job //设置数据输入路径
// 2 设置inputformat 原始数据 zhangsan lisi wangwu --第一行
zhangsan --第二行
// 3 设置map阶段 zhangsan 1
lisi 1
wangwu 1
zhangsan 1
// 4 设置shuffle 阶段 (默认无需配置) zhangsan [1,1]
lisi 1
wangwu 1
// 5 设置reduce 阶段 zhangsan 2
lisi 1
wangwu 1
// 6 设置 output Formate // 设置数据输出路径 注意:要求结果目录不能存在
// 7 提交job作业
*/
public int run(String[] strings) throws Exception {
// 1 创建job
Configuration conf = getConf();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJob.class);
// 2 设置inputformat
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/wordcount/data"));
// 3 设置map阶段
job.setMapperClass(WordCountMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4 设置shuffle 阶段 (默认无需配置)
// 5 设置reduce 阶段
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 6 设置 output Formate 注意:要求结果目录不能存在
job.setOutputFormatClass(TextOutputFormat.class);
Path resPath = new Path("/wordcount/result"); //此为目录 会在 此目录下 生成/wordcount/result/part-r-00000 名的结果文件
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(resPath)){
fileSystem.delete(resPath,true);
}
TextOutputFormat.setOutputPath(job,resPath);
// 7 提交job作业
boolean result = job.waitForCompletion(true);
System.out.println("wordcount result = " + result);
return 0;
}
}
打包及发布
securityCRT 连接到namenode 所在机器 hadoop15
ctrl + p 打开传输文档视图 将本地文件放到 hadoop15
sftp> put -r "D:\04_CodeFromNet\HDFS\hdfs_by_baizhi\wordcount\target\wordcount-1.0-SNAPSHOT.jar"
到namenode 所在机器 hadoop15 执行
[root@hadoop15 ~]# hadoop jar wordcount-1.0-SNAPSHOT.jar com.tiza.leo.mapreduct.wordcount.WordCountJob
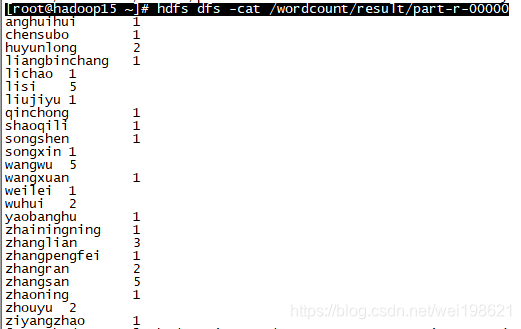
验证
[root@hadoop15 ~]# hdfs dfs -cat /wordcount/result/part-r-00000
 http://192.168.213.216:8088/cluster
http://192.168.213.216:8088/cluster
http://hadoop15:50070/explorer.html#/wordcount/
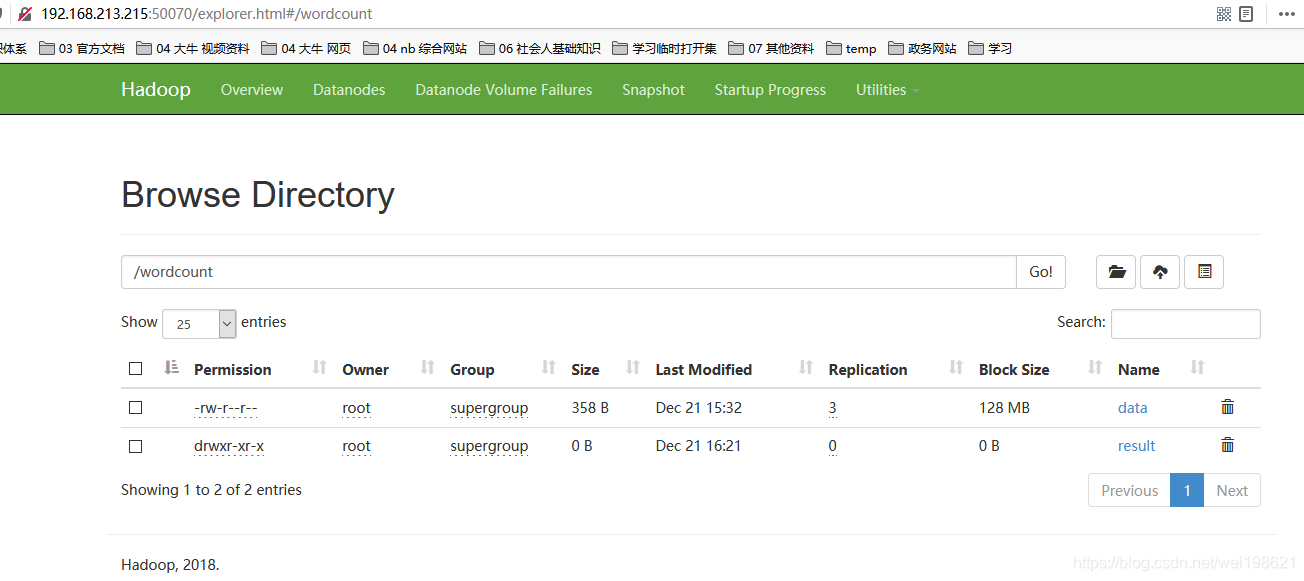
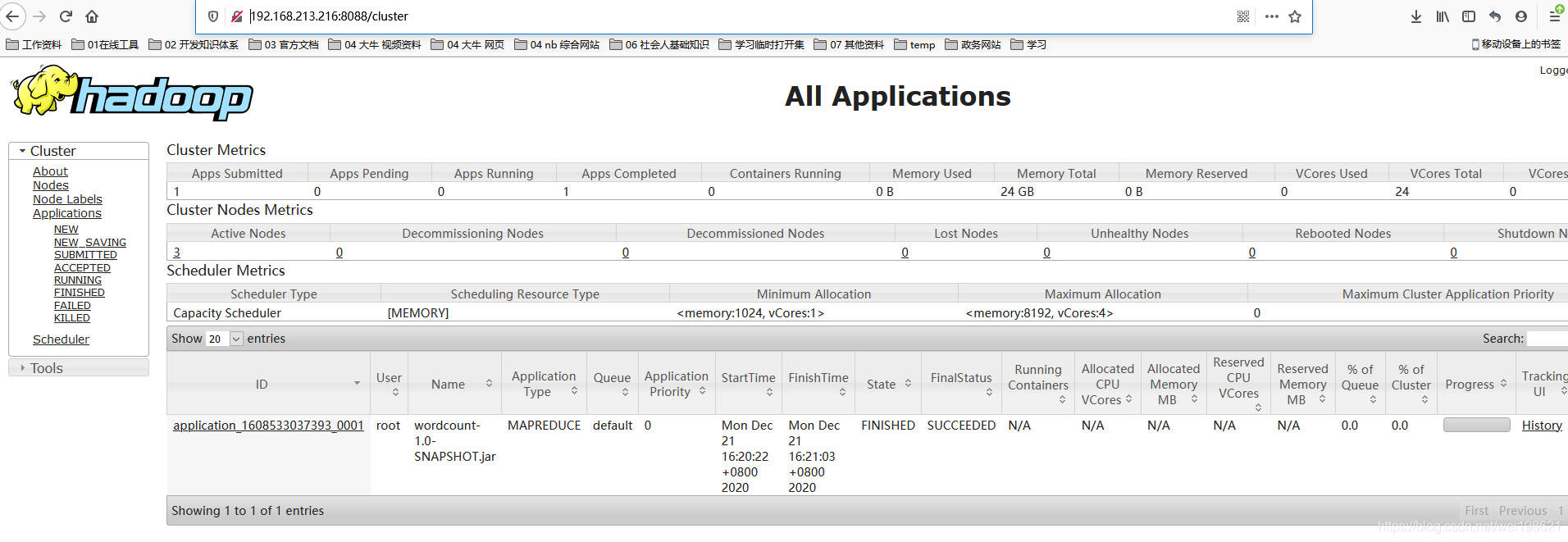
MapReduce 自动化运行配置
step1 最初版本的发布及运行 mapreduce 程序wordcount 过程-
1. IDEA 中执行 maven package
2. 将target中的Jar包放到15上面 put -r "D:\04_CodeFromNet\HDFS\hdfs_by_baizhi\wordcount\target\wordcount-1.0-SNAPSHOT.jar"
3. 到15上面执行 hadoop jar wordcount-1.0-SNAPSHOT.jar com.tiza.leo.mapreduct.wordcount.WordCountJob
4. 验证是否执行成功 hdfs dfs -cat /wordcount/result/part-r-00000
http://192.168.213.216:8088/cluster
http://192.168.213.215:50070/explorer.html#/wordcount/
http://hadoop15:50070/explorer.html#/wordcount/
默认target目录下的jar包的 META-INF/MANIFEST.MF 中的内容是
Manifest-Version: 1.0
Archiver-Version: Plexus Archiver
Built-By: tz_wl
Created-By: Apache Maven 3.5.2
Build-Jdk: 1.8.0_45
step2 在打包插件中指定main class 信息
在pom.xml 中增加打包规则
1.zhi定输入目录 ${basedir}=当前项目根目录
2.指定入口函数类
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<outputDirectory>${basedir}</outputDirectory>
<archive>
<manifest>
<mainClass>com.tiza.leo.mapreduct.wordcount.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
修改pom后,target目录下的jar包的 META-INF/MANIFEST.MF 中的内容是
Manifest-Version: 1.0
Archiver-Version: Plexus Archiver
Built-By: tz_wl
Created-By: Apache Maven 3.5.2
Build-Jdk: 1.8.0_45
Main-Class: com.tiza.leo.mapreduct.wordcount.WordCountJob
到15上面执行 无需执行入口函数
[root@hadoop15 ~]# hadoop jar wordcount-1.0-SNAPSHOT.jar
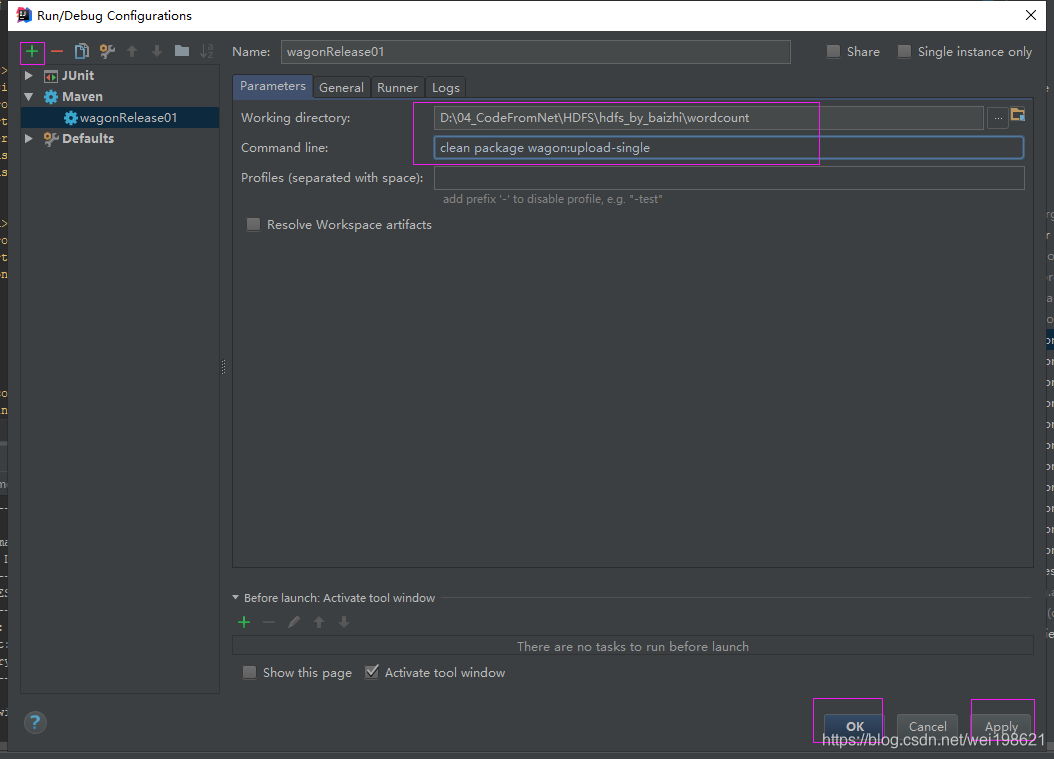
使用wagon上传jar完成后远程执行job作业
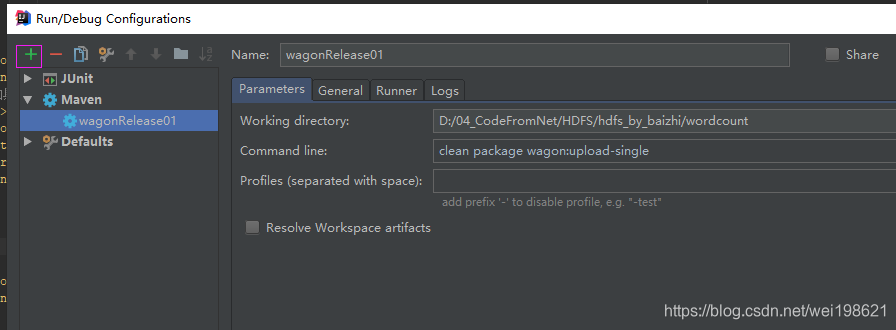
1. 配置pom使用wagon
2. 删除服务器 上面原始的 jar 包
[root@hadoop15 ~]# rm -rf wordcount-1.0-SNAPSHOT.jar
3. idea 执行maven 自带指令 clean 删除本地文件
4. idea 执行maven 自带指令 package 在目录target下生成jar文件
5. 执行wagon插件下的 wagon:upload-single 指令 将本地target下的jar文件 通过scp 放到 远程服务器
<build>
<!--增加wagon扩展-->
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<outputDirectory>${basedir}/target</outputDirectory>
<archive>
<manifest>
<mainClass>com.tiza.leo.mapreduct.wordcount.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<!--增加具体的wagon指令自定义配置-->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<fromFile>target/${project.build.finalName}.jar</fromFile> <!-- target/wordcount-1.0-SNAPSHOT.jar 或者 ${project.build.finalName}.jar-->
<url>scp://root:root@192.168.213.215/root</url> <!-- scp://user:password@192.168.20.128/root-->
</configuration>
</plugin>
</plugins>
</build>
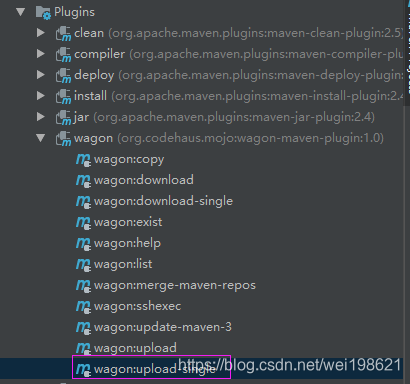
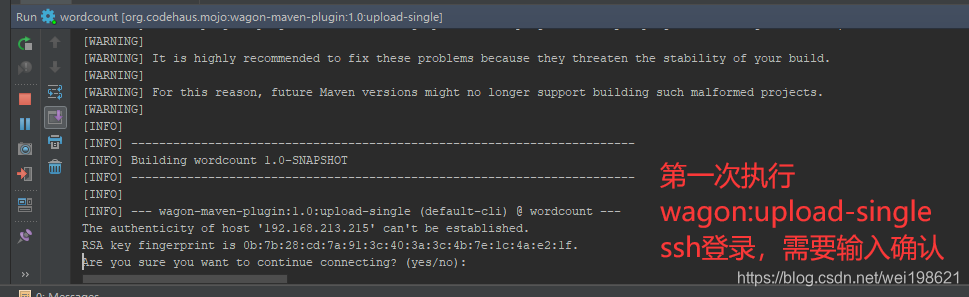
wagon远程执行wordcount的mapreduce指令
在这里插入代码片
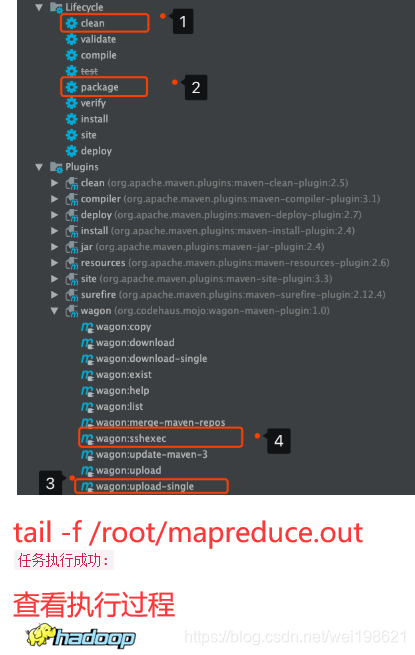
[root@hadoop15 ~]# tail -f /root/mapreduce.out
查看 resourceManager 相关日志
(working)
http://192.168.213.215:50070/ ----- namenode 节点web服务
http://192.168.213.216:8088/cluster ----- ResourceManager web服务
(zhan99)
http://192.168.121.215:50070/ ----- namenode 节点web服务
http://192.168.121.216:8088/cluster ----- ResourceManager web服务
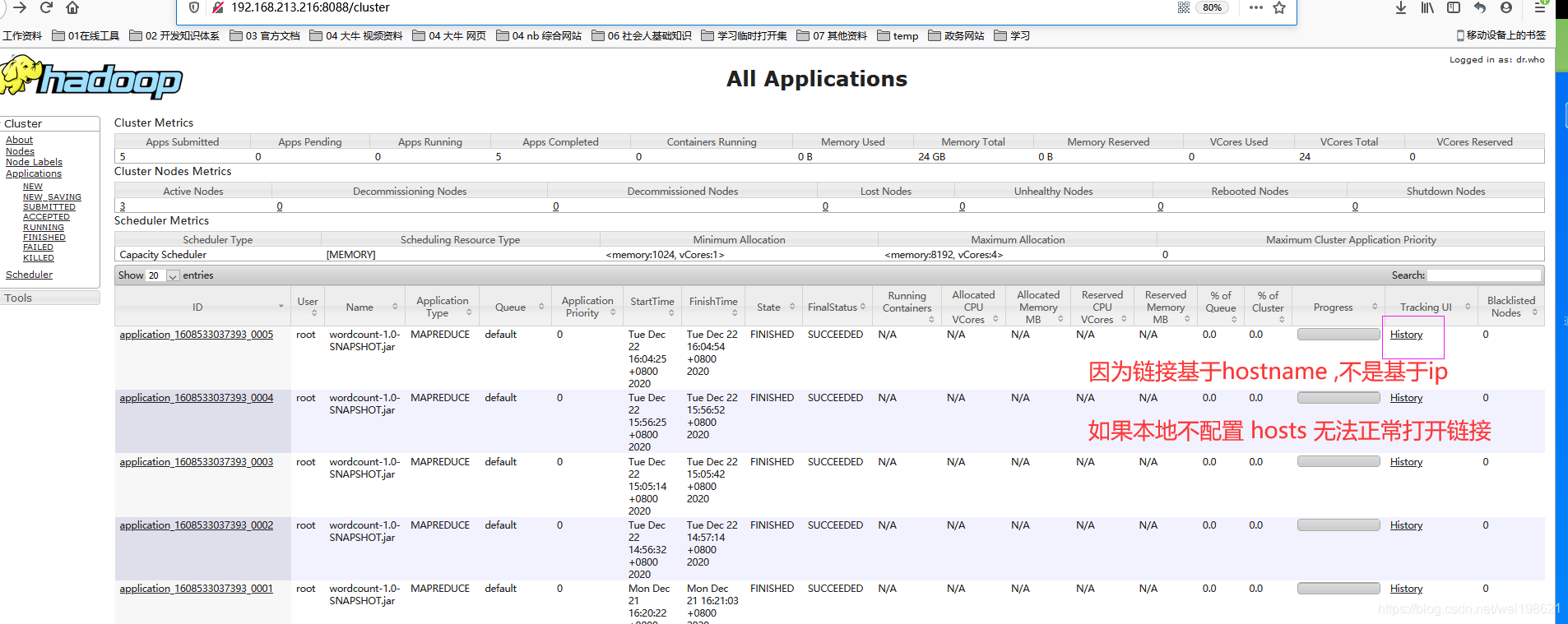
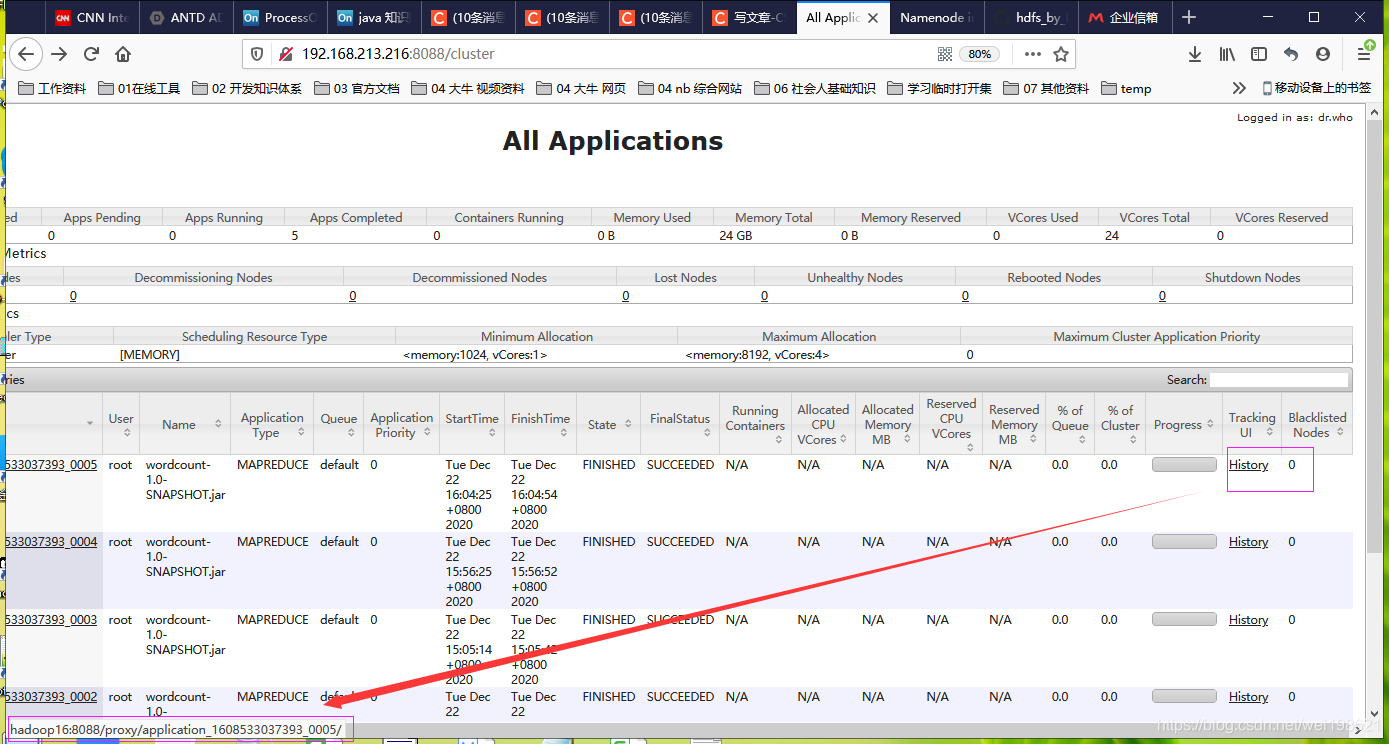
C:\Windows\System32\drivers\etc
#本地测试mapreduce
192.168.213.215 hadoop15
192.168.213.216 hadoop16
192.168.213.216 hadoop17
http://hadoop16:19888/jobhistory/job/job_1608533037393_0005
在这里插入代码片
配置历史服务器调试Map Reduce
20201222 ----暂时没有成功
在这里插入代码片
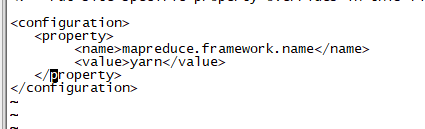
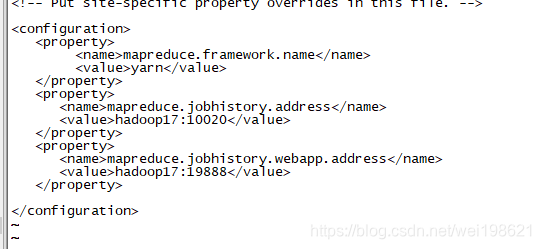

配置yarn-site.xml 并同步集群配置
01 编辑 hadoop 15 指令的 mapred-site.xml ,指定 17 作为历史服务器
10020 ---- 历史服务器后台接口地址
19888 ---- 历史服务器UI访问地址
vim /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop17:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop17:19888</value>
</property>
02 编辑 hadoop 15 指令的 yarn-site.xml
vim /root/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<!--开启日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保存时间 单位秒 这里是7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
03 将 15 上面修改的配置文件同步到 16 17
scp /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml root@hadoop16:/root/hadoop-2.9.2/etc/hadoop/
scp /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml root@hadoop17:/root/hadoop-2.9.2/etc/hadoop/
scp /root/hadoop-2.9.2/etc/hadoop/yarn-site.xml root@hadoop16:/root/hadoop-2.9.2/etc/hadoop/
scp /root/hadoop-2.9.2/etc/hadoop/yarn-site.xml root@hadoop17:/root/hadoop-2.9.2/etc/hadoop/
启动历史服务器 验证是否成功运行
17历史服务器上面启动 jobhistory服务器
16上面启动 ResourceManager服务器
启动历史服务器 按照之前的计划17作为我们的历史服务器
[root@hadoop17 ~]# mr-jobhistory-daemon.sh start historyserver
[root@hadoop17 ~]# mr-jobhistory-daemon.sh stop historyserver --- 此句不用执行
Last login: Sun Dec 20 00:13:21 2020 from 192.168.121.1
[root@hadoop17 ~]# jps
41574 Jps
8391 DataNode
9048 NodeManager
[root@hadoop17 ~]# mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /root/hadoop-2.9.2/logs/mapred-root-historyserver-hadoop17.out
[root@hadoop17 ~]# jps
8391 DataNode
9048 NodeManager
41865 Jps
41723 JobHistoryServer ---- 启动了jobHistoryServer
[root@hadoop17 ~]#
由于启动 yarn的时候 其配置的 mapred-site.xml yarn-site.xml 还不是最新的,
所以需要到ResourceManager所在服务器 16上面 重新启动yarn
stop-yarn.sh
start-yarn.sh --- 重启之后,此不的重启,会读取最新的配置文件,
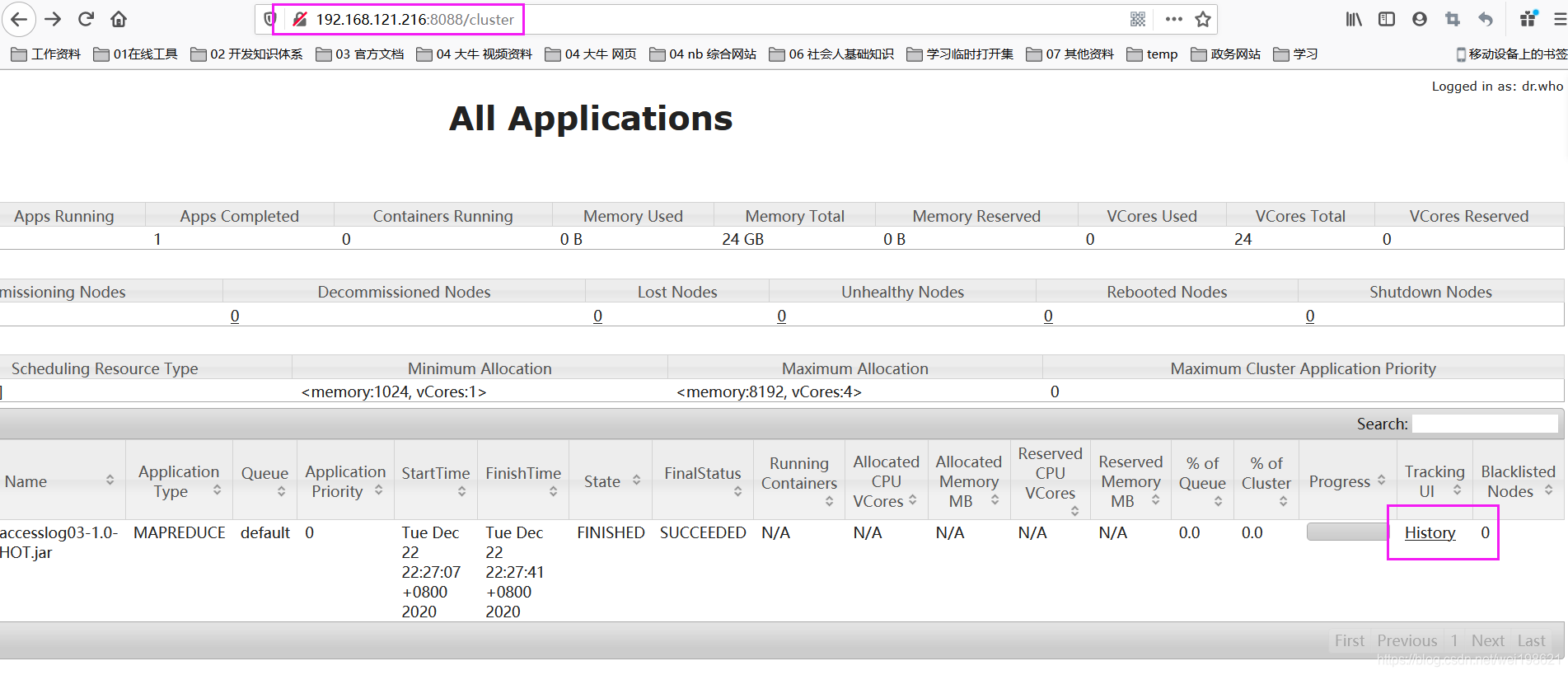
---当点击 http://192.168.121.216:8088/cluster 列表中的History字段的时候,会自动定位到217历史服务器的内容中去
http://hadoop17:19888/jobhistory/job/job_1608533037393_0007
http://192.168.213.217:19888/jobhistory/job/job_1608533037393_0007
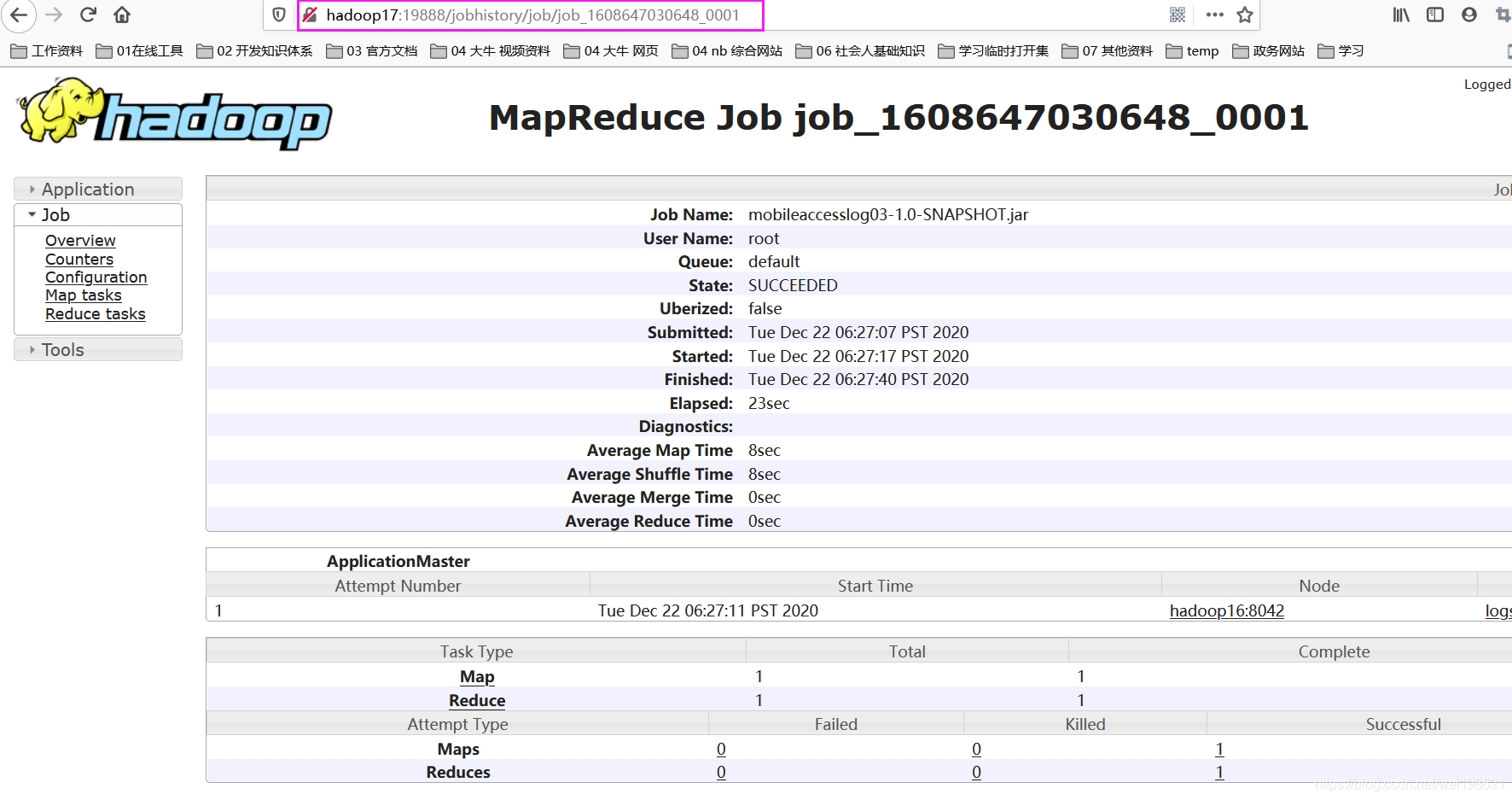
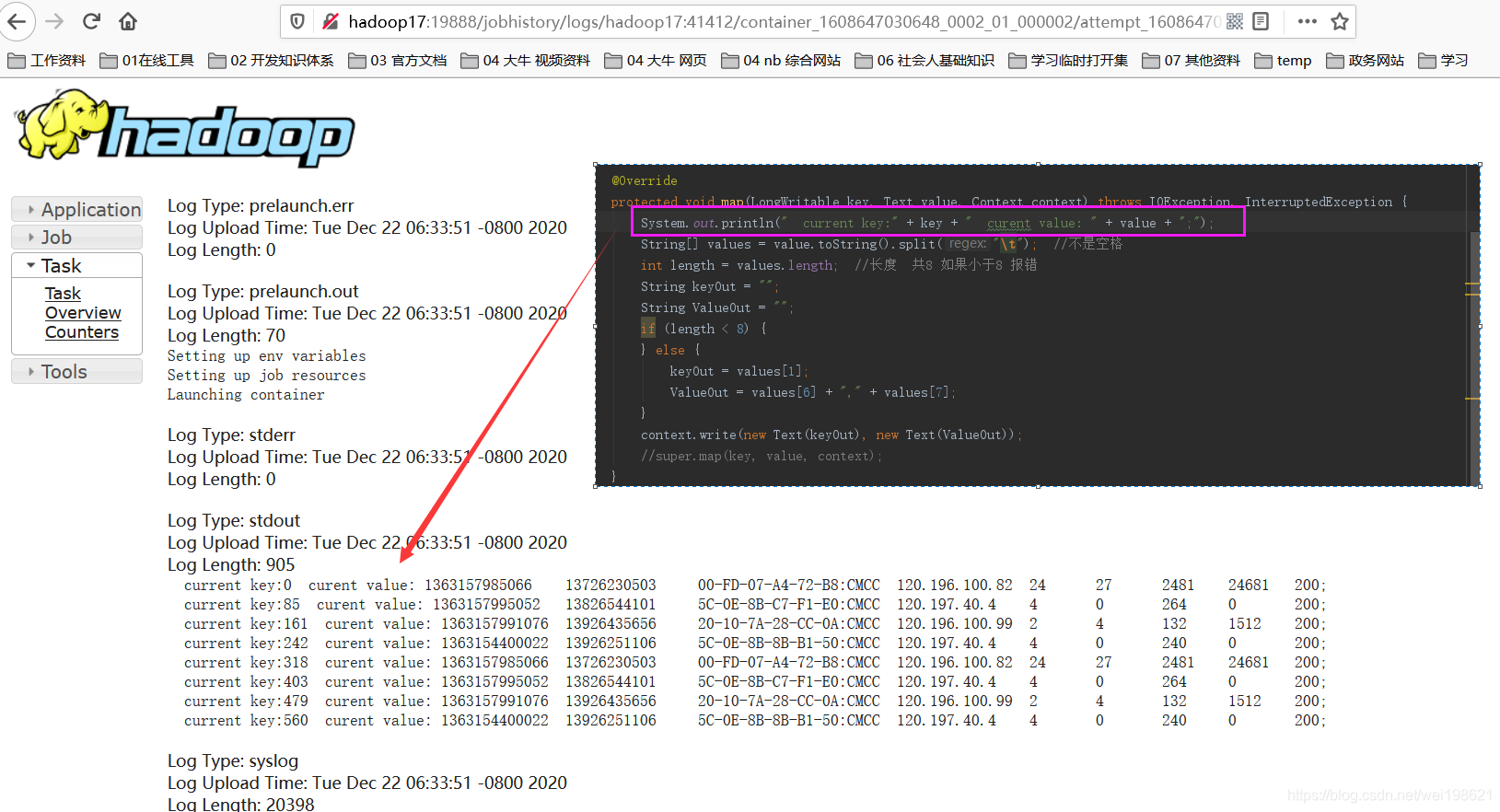
http://hadoop17:19888/jobhistory/job/job_1608647030648_0001
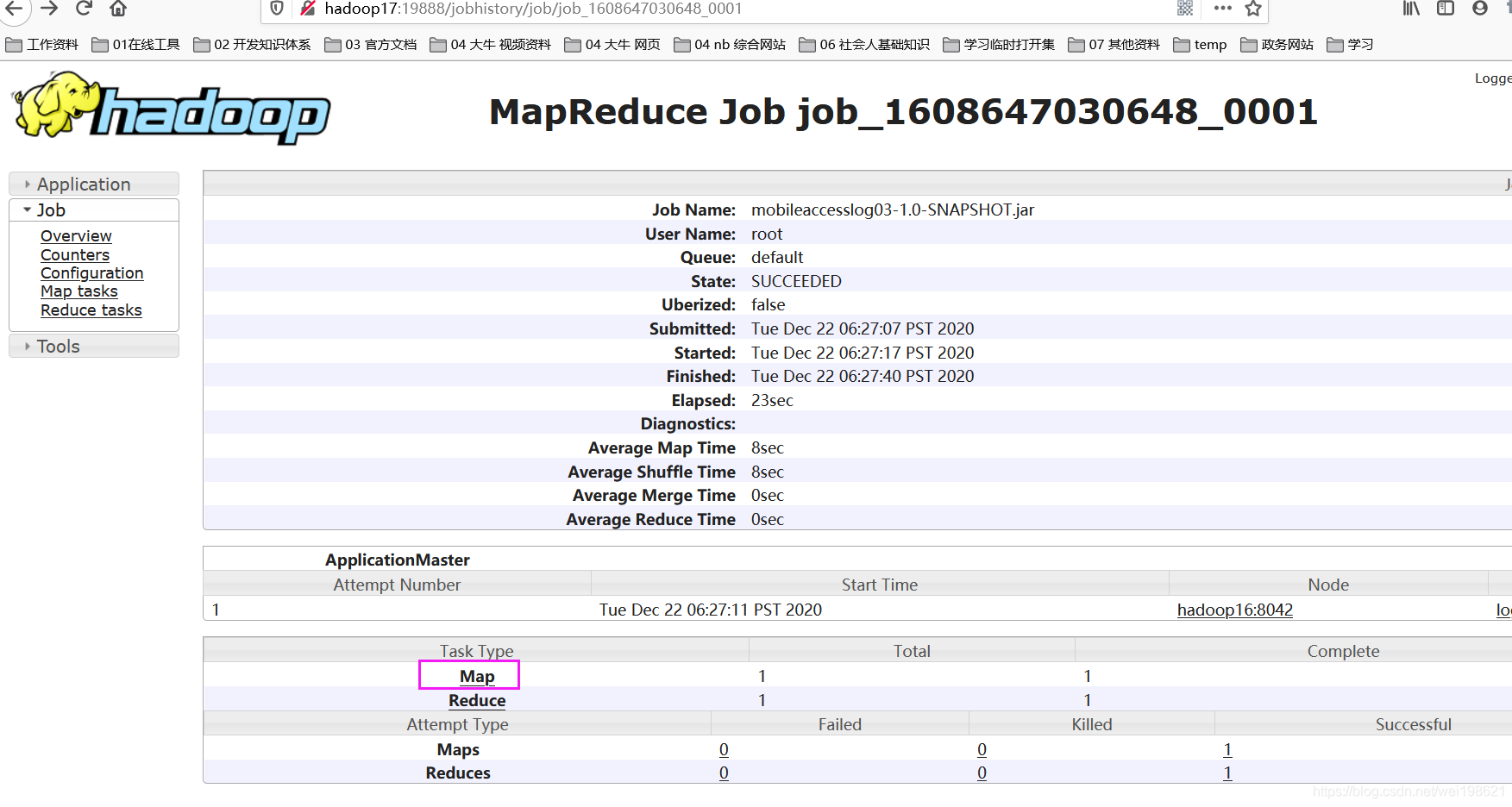
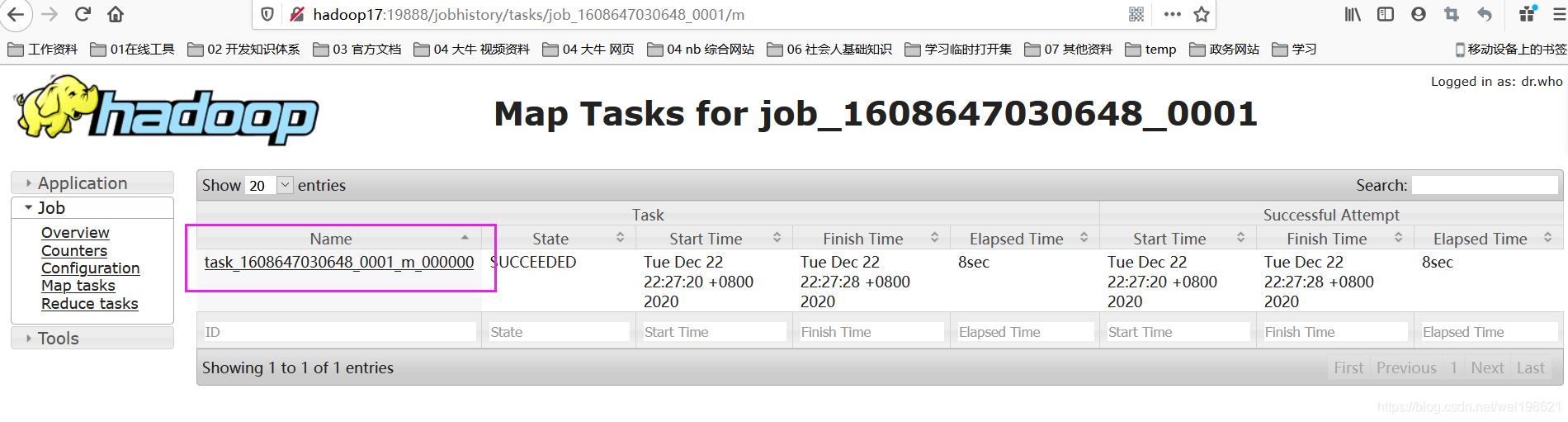
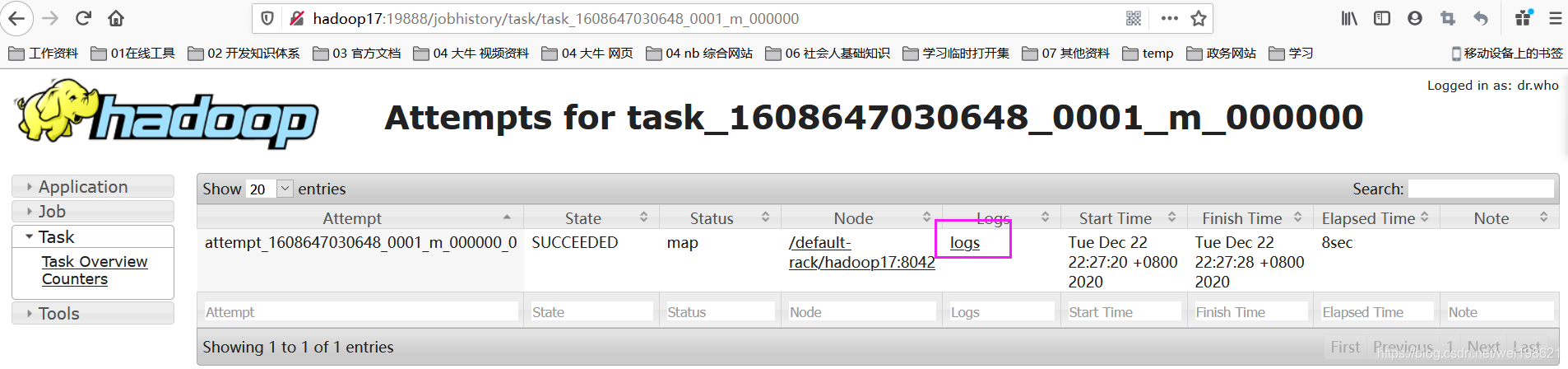 map示例
map示例
 reduce示例
reduce示例
 reduce示例 清晰版
reduce示例 清晰版
在这里插入代码片
在这里插入代码片
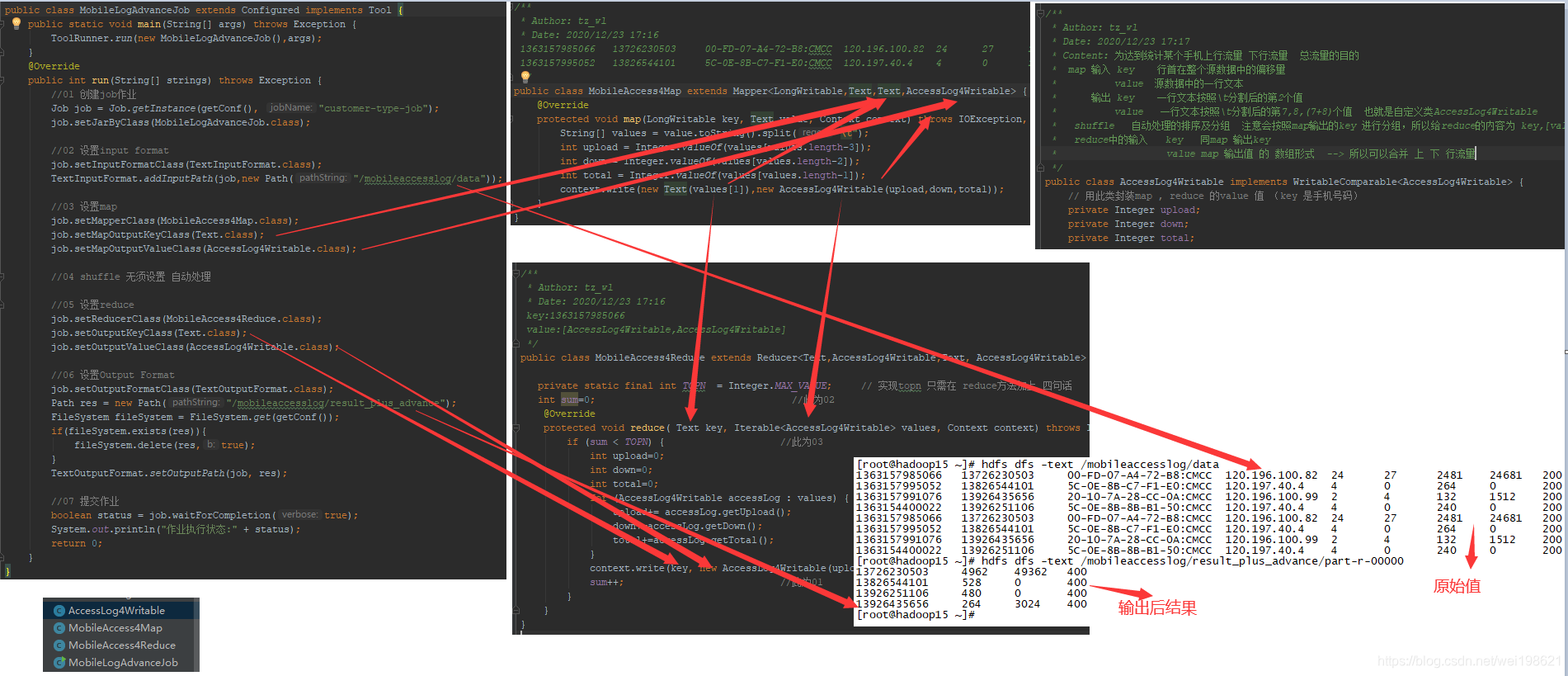
MobileAccessJob 从手机上下行数据中mr出 上行 下行 总流量
git 地址 : https://github.com/wei198621/hdfs_by_baizhi
准备原始数据
将数据及程序都部署到15这台机器上面
在15上面创建 /mobileaccesslog/data 放置要分析的全部数据
[root@hadoop15 ~]# vim mobileaccesslog
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
[root@hadoop15 ~]# hdfs dfs -mkdir /mobileaccesslog
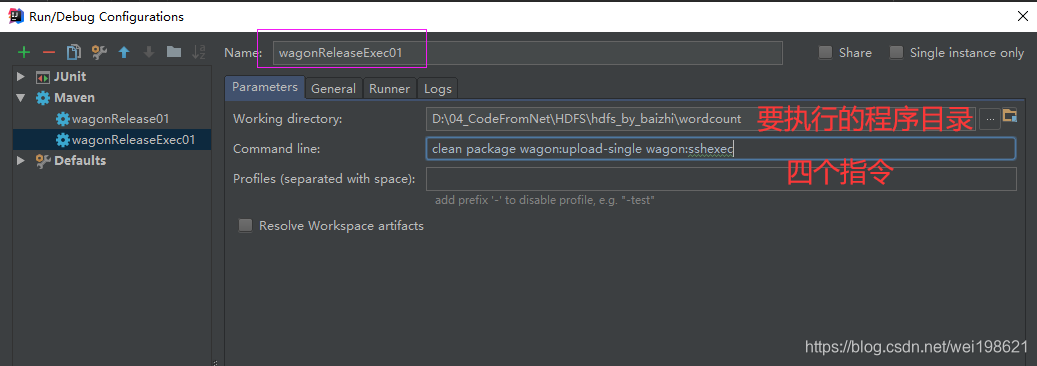
[root@hadoop15 ~]# hdfs dfs -put mobileaccesslog /mobileaccesslog/data
配置maven 命令组
clean package wagon:upload-single wagon:sshexec
成功执行后,看结果日志
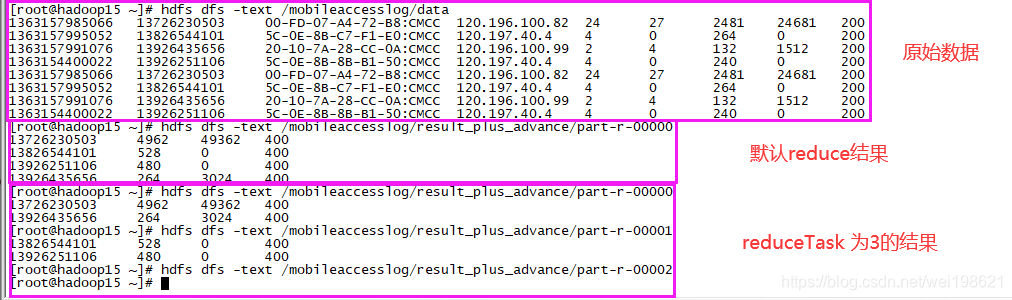
[root@hadoop15 ~]# hdfs dfs -cat /mobileaccesslog/result/part-r-00000
13726230503 up:4962,down:49362,all:54324
13826544101 up:528,down:0,all:528
13926251106 up:480,down:0,all:480
13926435656 up:264,down:3024,all:3288
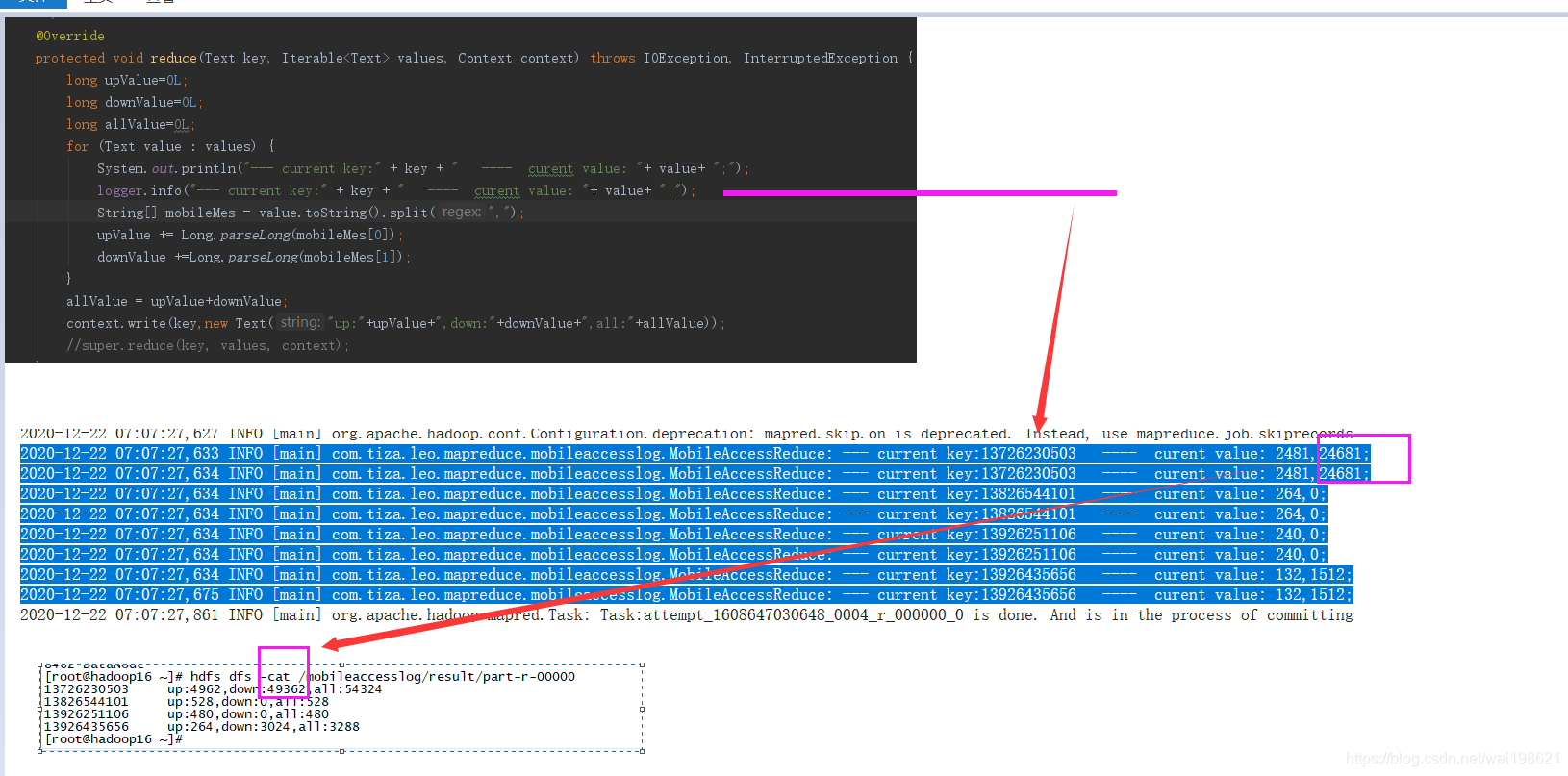
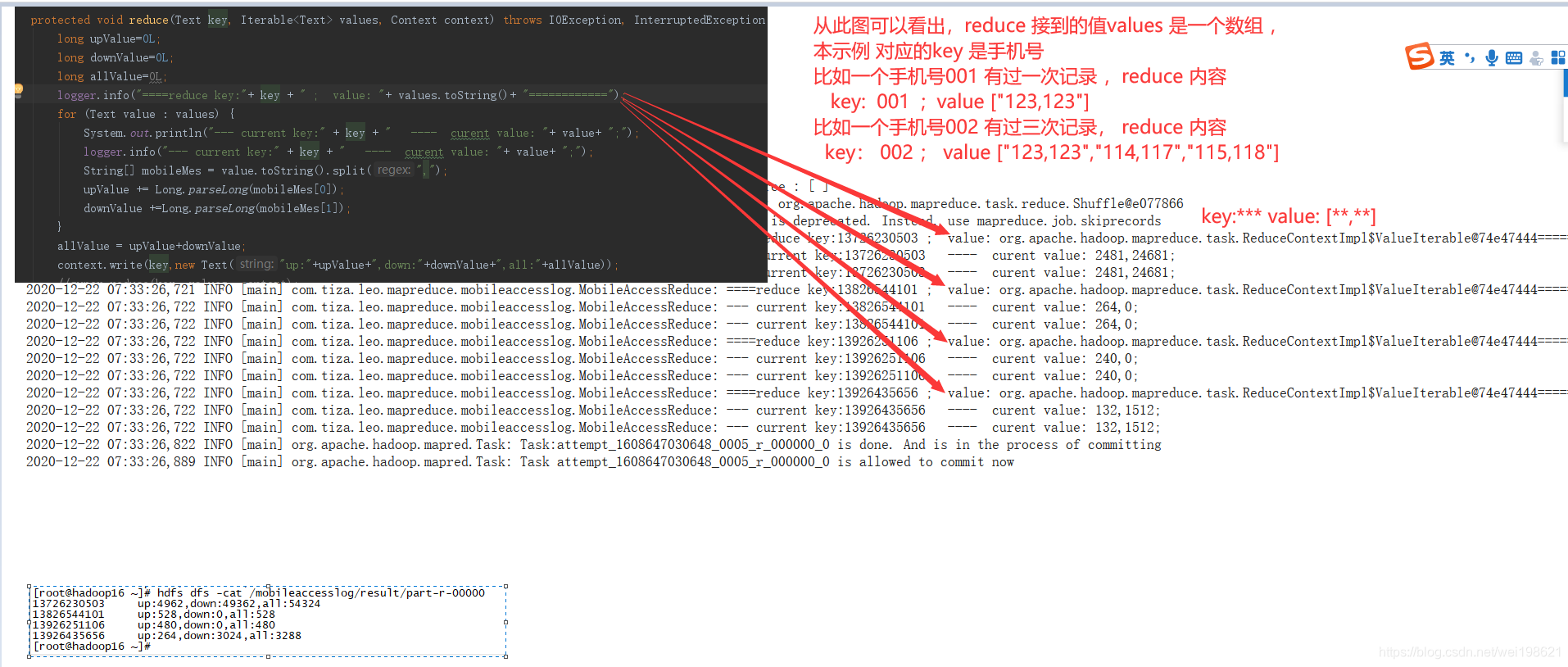
MobileAccessJob 从手机上下行数据中mr出 上行 下行 总流量 --面向对象思想处理 上下行及总流量
代码路径:
https://github.com/wei198621/hdfs_by_baizhi/tree/main/mobileaccesslogplus05
就是 03 的升级版
https://github.com/wei198621/hdfs_by_baizhi/tree/main/mobileaccesslog03
03版本 Map 传递给 reduce的内容是 拼的字符串 upload+down+total ,现在05版给的是一个对象

06基于05的统计,按照流量倒序排序
将05的结果 作为06的输入
代码路径:
https://github.com/wei198621/hdfs_by_baizhi/tree/main/mobiltaccesslogorder06
[root@hadoop15 ~]# hdfs dfs -cat /mobileaccesslog/result_plus/part-r-00000
13726230503 4962 49362 54324
13826544101 528 0 528
13926251106 480 0 480
13926435656 264 3024 3288


在排序基础上实现topn
没有新写代码
代码路径:
https://github.com/wei198621/hdfs_by_baizhi/tree/main/mobiltaccesslogorder06


流量数据只实现map
源码路径:
https://github.com/wei198621/hdfs_by_baizhi/tree/main/mobileaccesslogmap07
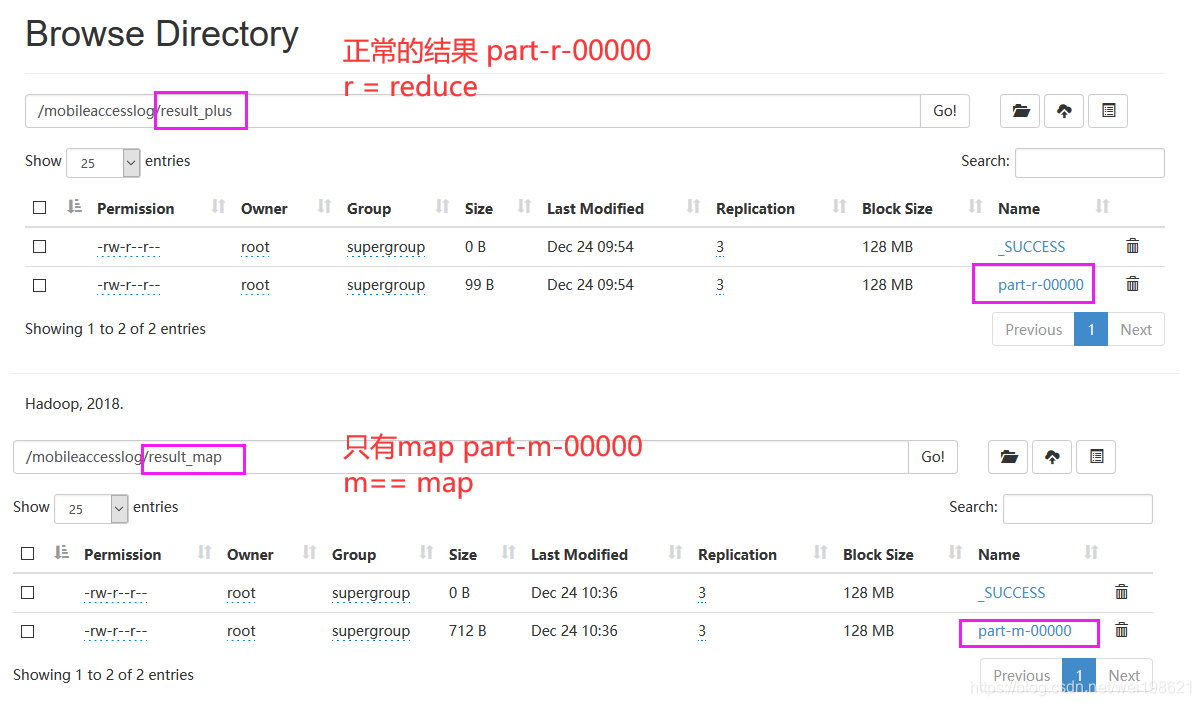
流量数据只实现map – 原数据大于128M
源码路径: input path 中的文件较大
https://github.com/wei198621/hdfs_by_baizhi/tree/main/mobileaccesslogmap07
单个map对象默认128M ,做一个文件 大于128M ,看看MAP的效果 ,map result 会生成多个文件,证明 map个数= 原始数据大小/128M
简单的脚本测试
[root@hadoop15 ~]# while true
> do echo "11111 2222 333 " >> access2.log
> sleep 1000
> done
某个原始数据
[root@hadoop15 hadoopdata]# vim mobiledata03
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
生成数据脚本:
[root@hadoop15 hadoopdata]# while true
> do cat mobiledata03 >> mobilebigdata.txt
> done
可以看到,当文件较大的时候,
[root@hadoop15 hadoopdata]# ll
总用量 374684
-rw-r--r--. 1 root root 383672088 12月 24 11:08 mobilebigdata.txt
-rw-r--r--. 1 root root 636 12月 22 17:47 mobiledata03
drwxr-xr-x. 2 root root 18 12月 21 15:31 wordcount
[root@hadoop15 hadoopdata]# pwd
/root/hadoopdata
[root@hadoop15 hadoopdata]# du -h mobilebigdata.txt
366M mobilebigdata.txt
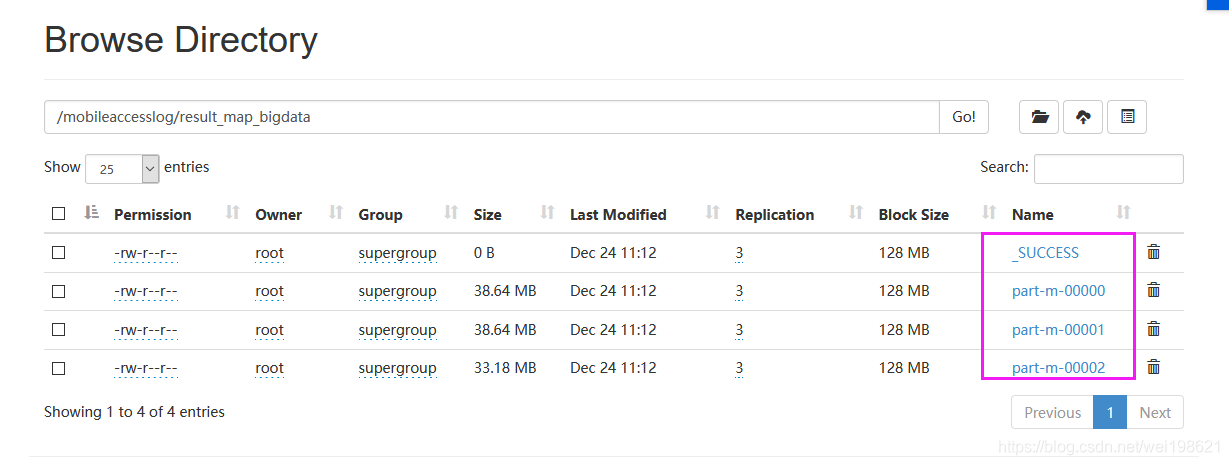
将文件分为按128M一个,分为3个文件
所以 map的结果分为三个
part-m-00000
part-m-00001
part-m-00002
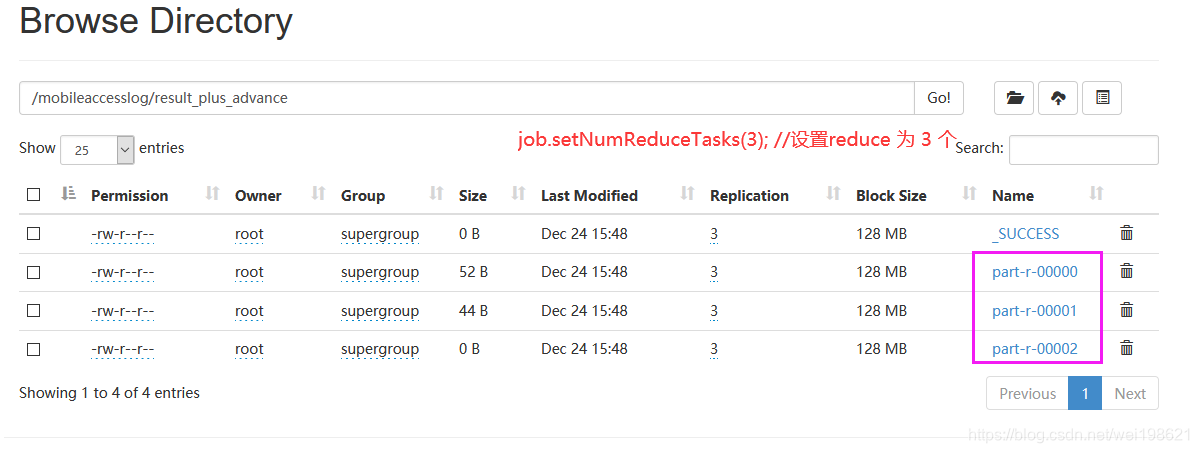
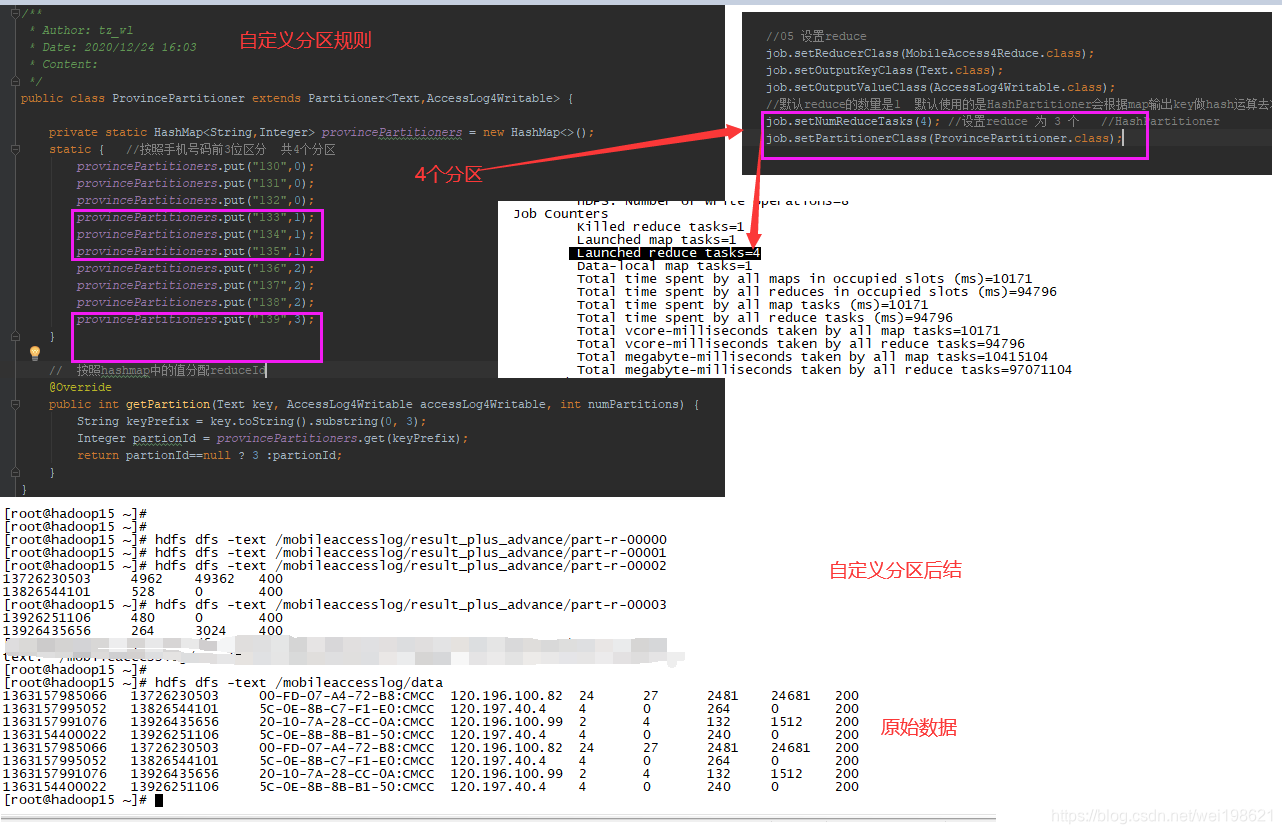
MapReduce中Reduce的数量修改示例(统计手机上下行流量)
源码地址:
https://github.com/wei198621/hdfs_by_baizhi/tree/main/mobileaccesslogadvace08
随机分为3个分区
配置文件中指定wagon的指令输出 在 /root/mapreduce08.out
查看日打印的日志有如下几项
File System Counters
FILE: Number of bytes read=214
FILE: Number of bytes written=398561
...
Job Counters
Launched map tasks=1
Launched reduce tasks=1
...
Map-Reduce Framework
Map input records=8
Map output records=8
...
Shuffle Errors
BAD_ID=0
File Input Format Counters
Bytes Read=636
File Output Format Counters
Bytes Written=96
可以看到 JobCounters 中 map task=1 reduce tasks=1
当修改 main 方法中 job 的reduce 数量后
job.setNumReduceTasks(3);
可以看到 reduce tasks=3
Job Counters
Killed reduce tasks=1
Launched map tasks=1
Launched reduce tasks=3
同时,我们看到输入结果目录
/mobileaccesslog/result_plus_advance
有三个文件,分别为
part-r-00000
part-r-00001
part-r-00002
没有分reduce的时候默认只有一个
part-r-00000
自定义分区

从两个csv文件中 去重计算
git 地址 : https://github.com/wei198621/hdfs_by_baizhi
思路
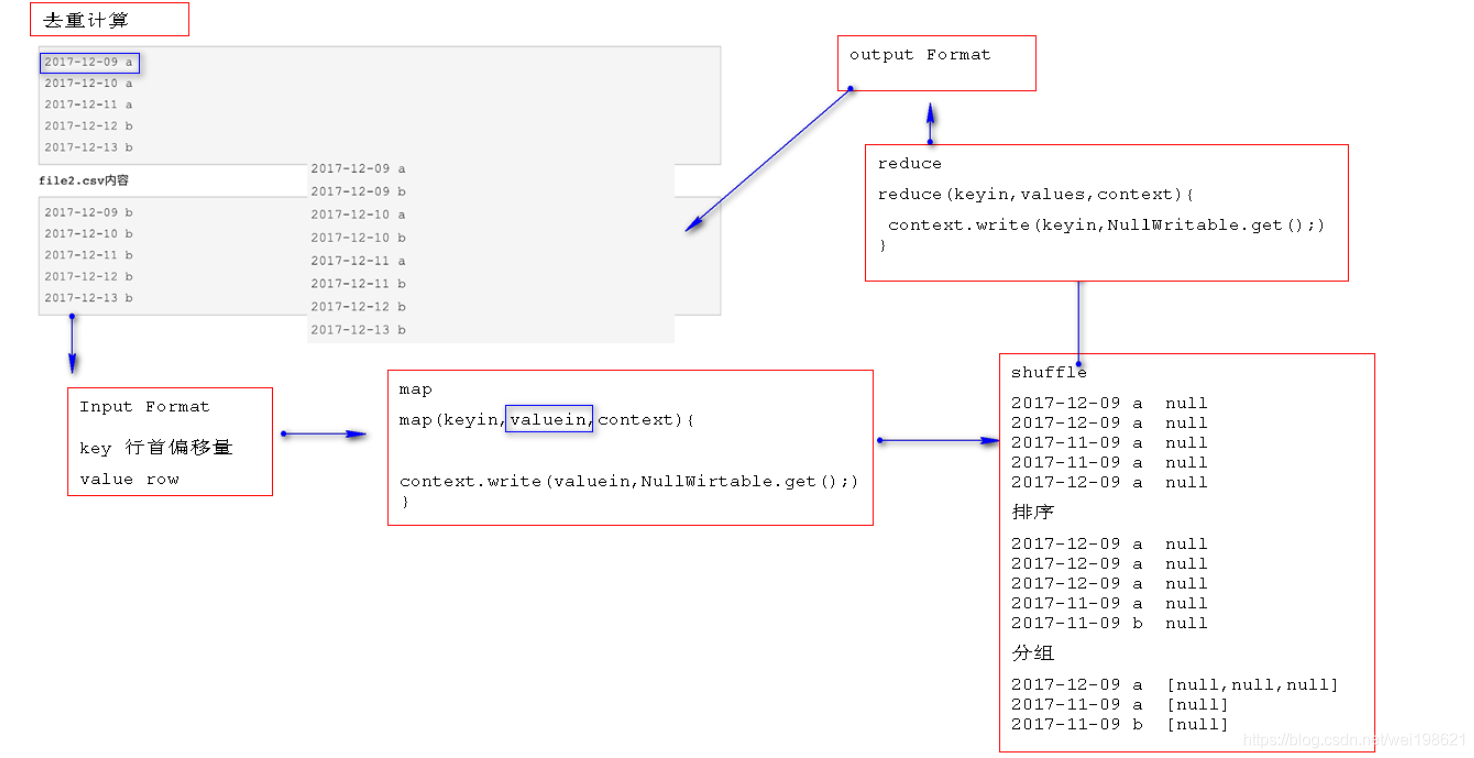
.csv 文件
2017-12-09 a
2017-12-10 a
2017-12-11 a
2017-12-12 b
2017-12-13 b
结果
[root@hadoop15 mapdata]# hdfs dfs -cat /cutmultiResult/result/part-r-00000
2017-12-09 a
2017-12-09 b
2017-12-10 a
2017-12-10 b
2017-12-11 a
2017-12-11 b
2017-12-12 b
2017-12-13 b
到现阶段 各种服务器主界面
启动各服务器
15启动hdfs
[root@hadoop15 ~]# start-dfs.sh
[root@hadoop15 ~]# stop-dfs.sh
16启动yarn
[root@hadoop16 ~]# start-yarn.sh
[root@hadoop16 ~]# stop-yarn.sh
17启动历史服务器
[root@hadoop17 ~]# mr-jobhistory-daemon.sh start historyserver
NameNode(15)
http://hadoop15:50070/
192.168.121.215:50070/ – zhan99 pc
192.168.213.215:50070/ – working PC
Resource Manager (16)
http://hadoop16:8088/cluster
192.168.121.216:50070/ – zhan99 pc
192.168.213.216:50070/ – working PC
历史服务器 (17)
http://hadoop17:19888/jobhistory
http://192.168.121.217:19888/jobhistory – zhan99 pc
http://192.168.213.217:19888/jobhistory – working PC
图示map reduce个参数间关系
HA的hadoop集群搭建
集群规划
集群规划
192.168.213.220 zk zknodes 通过一个节点充当整个集群
192.168.213.222 hadoop22 NameNode (active) & ZKFC
192.168.213.223 hadoop23 NameNode (standby) & ZKFC
192.168.213.224 hadoop24 ResourceManager(active)
192.168.213.225 hadoop25 ResourceManager(standby)
192.168.213.226 hadoop26 DataNode & JournalNode & NodeManager
192.168.213.227 hadoop27 DataNode & JournalNode & NodeManager
192.168.213.228 hadoop28 DataNode & JournalNode & NodeManager
# 克隆机器做准备工作:
0.修改ip地址为上述ip vim /etc/
[leo@hadoop1 ~]$ su root
cd
[root@hadoop1 ~]# rm -rfv aa.txt anaconda-ks.cfg bb.txt cc.txt ddd2.txt dd.txt
ll
[root@hadoop1 network-scripts]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.213.201 //修改为对应值 **
reboot / shutdown -t 0
1.修改主机名/etc/hostsname为上述对应主机名 修改完必须重新启动
2.配置主机名ip地址映射/etc/hosts文件并同步所有节点
192.168.213.220 zk
192.168.213.222 hadoop22
192.168.213.223 hadoop23
192.168.213.224 hadoop24
192.168.213.225 hadoop25
192.168.213.226 hadoop26
192.168.213.227 hadoop27
192.168.213.228 hadoop28
3.所有节点安装jdk并配置环境变量 vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
4.关闭所有机器的网络防火墙配置
systemctl stop firewalld
systemctl disable firewalld
5.所有节点安装centos7.x搭建集群的依赖 -- 用于支持 killall 命令
yum install psmisc -y
6.配置ssh免密登录 ll -a /root/.ssh ssh-copy-id hadoop22
hadoop22 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
hadoop23 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
hadoop24 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
hadoop25 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
搭建zk集群
# 1.安装zk安装包
[root@zk ~]# tar -zxvf zookeeper-3.4.12.tar.gz
# 2.准备zk的数据文件夹
[root@zk ~]# mkdir zkdata1 zkdata2 zkdata3
# 3.在每个数据文件夹中准备集群唯一标识文件myid
[root@zk ~]# echo "1" >> zkdata1/myid
[root@zk ~]# echo "2" >> zkdata2/myid
[root@zk ~]# echo "3" >> zkdata3/myid
# 4.在每个数据文件夹中准备zk的配置文件zoo.cfg
--- 3001 zk与客户端通讯端口,
--- 3002 zk内部广播端口,
--- 3003 zk容错选举端口
[root@zk ~]# vim /root/zkdata1/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata1
clientPort=3001
server.1=zk:3002:3003
server.2=zk:4002:4003
server.3=zk:5002:5003
[root@zk ~]# vim /root/zkdata2/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata2
clientPort=4001
server.1=zk:3002:3003
server.2=zk:4002:4003
server.3=zk:5002:5003
[root@zk ~]# vim /root/zkdata3/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata3
clientPort=5001
server.1=zk:3002:3003
server.2=zk:4002:4003
server.3=zk:5002:5003
# 5.进入zk安装目录bin目录执行如下命令启动zk集群: [root@zk bin]# cd /root/zookeeper-3.4.12/bin
[root@zk bin]# ./zkServer.sh start /root/zkdata1/zoo.cfg
[root@zk bin]# ./zkServer.sh start /root/zkdata2/zoo.cfg
[root@zk bin]# ./zkServer.sh start /root/zkdata3/zoo.cfg
# 6.进入zk安装目录bin目录执行如下命令查看集群状态
./zkServer.sh status /root/zkdata1/zoo.cfg
./zkServer.sh status /root/zkdata2/zoo.cfg
./zkServer.sh status /root/zkdata3/zoo.cfg
#7 查看运行状态
[root@zk bin]# jps
2597 QuorumPeerMain
2679 Jps
2552 QuorumPeerMain
2648 QuorumPeerMain
[root@zk bin]# ./zkServer.sh status /root/zkdata1/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /root/zkdata1/zoo.cfg
Mode: follower
[root@zk bin]# ./zkServer.sh status /root/zkdata2/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /root/zkdata2/zoo.cfg
Mode: leader
[root@zk bin]# ./zkServer.sh status /root/zkdata3/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /root/zkdata3/zoo.cfg
Mode: follower
搭建hadoop的HA集群
# 1.在hadoop22--hadoop28上安装hadoop安装包
tar -zxf hadoop-2.9.2.tar.gz
# 2.在hadoop22--hadoop28机器上配置hadoop环境变量
[root@hadoop22 ~]# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_202
export HADOOP_HOME=/root/hadoop-2.9.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 3.在hadoop22节点上配置hadoop-env.sh文件
[root@hadoop28 ~]# echo $JAVA_HOME
/usr/java/jdk1.8.0_202
[root@hadoop28 ~]# vim /root/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_202
# 4.在hadoop22节点上配置core-site.xml文件
[root@hadoop22 ~]# vim /root/hadoop-2.9.2/etc/hadoop/core-site.xml
<!--hdfs主要入口不再是一个具体机器而是一个虚拟的名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- hadoop临时目录位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.9.2/data</value>
</property>
<!--zk集群的所有节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk:3001,zk:4001,zk:5001</value>
</property>
# 5.在hadoop22节点上配置hdfs-site.xml文件
[root@hadoop22 ~]# vim /root/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop22:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop22:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop23:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop23:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop26:8485;hadoop27:8485;hadoop28:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
# 6.在hadoop22节点上配置yarn-site.xml文件
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop24</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop25</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop24:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop25:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk:3001,zk:4001,zk:5001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
# 7.在hadoop2节点上配置mapred-site.xml文件,默认不存在需要复制
[root@hadoop22 ~]# cp /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml
[root@hadoop22 ~]# vim /root/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# 8.在hadoop2节点上配置slaves文件
[root@hadoop22 ~]# vim /root/hadoop-2.9.2/etc/hadoop/slaves
hadoop26
hadoop27
hadoop28
# 9.同步集群配置文件
scp -r /root/hadoop-2.9.2/etc/hadoop/ hadoop23:/root/hadoop-2.9.2/etc/
scp -r /root/hadoop-2.9.2/etc/hadoop/ hadoop24:/root/hadoop-2.9.2/etc/
scp -r /root/hadoop-2.9.2/etc/hadoop/ hadoop25:/root/hadoop-2.9.2/etc/
scp -r /root/hadoop-2.9.2/etc/hadoop/ hadoop26:/root/hadoop-2.9.2/etc/
scp -r /root/hadoop-2.9.2/etc/hadoop/ hadoop27:/root/hadoop-2.9.2/etc/
scp -r /root/hadoop-2.9.2/etc/hadoop/ hadoop28:/root/hadoop-2.9.2/etc/
# 9.9.reboot 所有节点
# 10.启动HDFS的高可用
1.在任意NameNode上格式化ZK (通常在nameNode所在机器 22 )
hdfs zkfc -formatZK
2.在hadoop26 hadoop27 hadoop28启动journal node
[root@hadoop26 ~]# hadoop-daemon.sh start journalnode
[root@hadoop27 ~]# hadoop-daemon.sh start journalnode
[root@hadoop28 ~]# hadoop-daemon.sh start journalnode
3.在活跃的NameNode节点上执行格式化
[root@hadoop22 ~]# hdfs namenode -format ns
4.在NameNode上启动hdfs集群
[root@hadoop22 ~]# start-dfs.sh
[root@hadoop22 ~]# jps
2768 DFSZKFailoverController
2465 NameNode
2839 Jps
5.在standby的NameNode上执行
[root@hadoop23 ~]# hdfs namenode -bootstrapStandby
[root@hadoop23 ~]# jps
2114 Jps
2056 DFSZKFailoverController
[root@hadoop23 ~]# hdfs namenode -bootstrapStandby
6.在standby的NameNode执行
[root@hadoop23 ~]# hadoop-daemon.sh start namenode
[root@hadoop23 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /root/hadoop-2.9.2/logs/hadoop-root-namenode-hadoop23.out
[root@hadoop23 ~]# jps
2225 NameNode
2056 DFSZKFailoverController
2286 Jps
# 11.在活跃节点上启动yarn集群
1.在活跃的resourcemang节点上执行
[root@hadoop24 ~]# start-yarn.sh
[root@hadoop24 ~]# jps
2020 ResourceManager
2106 Jps
----启动后 26 27 28 就会启动NodeManager
[root@hadoop27 ~]# jps
2052 DataNode
1957 JournalNode
2175 Jps
[root@hadoop27 ~]# jps
2052 DataNode
2388 Jps
1957 JournalNode
2253 NodeManager
2.在standby的节点上执行
[root@hadoop25 ~]# yarn-daemon.sh start resourcemanager
[root@hadoop25 ~]# jps
1992 Jps
[root@hadoop25 ~]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-resourcemanager-hadoop25.out
[root@hadoop25 ~]# jps
2059 Jps
2030 ResourceManager
# 12.测试集群
1. 访问hdfs提供的web界面
http://192.168.213.222:50070/
http://hadoop22:50070/
2. [root@hadoop22 ~]# hdfs -dfs -put aa.txt /
[root@hadoop22 ~]# hdfs dfs -ls /
3. 查看 hadoop运行状态 resourcemanager节点 hadoop24 hadoop25
http://192.168.213.224:8088/cluster
http://hadoop24:8088/cluster
http://192.168.213.225:8088/cluster 访问25节点自动跳到24节点
http://hadoop25:8088/cluster 访问25节点自动跳到24节点
3.1 关闭主节点 hadoop24
[root@hadoop24 ~]# jps
2547 Jps
2020 ResourceManager
[root@hadoop24 ~]# yarn-daemon.sh stop resourcemanager
stopping resourcemanager
[root@hadoop24 ~]# jps
2582 Jps
此时再访问24,访问不通了 ,25可以访问
重启24简单的resourcemanager
[root@hadoop24 ~]# jps
2582 Jps
[root@hadoop24 ~]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-resourcemanager-hadoop24.out
[root@hadoop24 ~]# jps
2643 ResourceManager
2684 Jps
此时再通过web访问 24 25 节点,都会跳到25节点,因为此节点此时为主节点


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









