



C语言的数据结构是由程序员通过定义变量、数组、结构体(struct)、联合体(union)、枚举(enum)、指针等构造出来的。这些基础构造块可以用来创建更复杂的数据结构,如:链表、栈、队列、树、图等。C语言中常用的数据结构类型:
基本数据类型:
整型(int、short、long、long long)
浮点型(float、double)
字符型(char)
布尔型(在C99之前,C语言没有直接的布尔类型,但可以使用_Bool或宏定义如#define TRUE 1和#define FALSE 0,或使用<stdbool.h>中的bool类型,C99及以后)
数组:
固定大小的连续内存空间,用于存储相同类型的数据。
结构体(struct):
允许将不同类型的数据项组合成一个单一的类型。
联合体(union):
允许在相同的内存位置存储不同的数据类型,但一次只能使用其中一种类型。
枚举(enum):
是一种用户定义的类型,允许程序员为整数指定更易读的名字。
指针:
存储变量内存地址的变量类型,是C语言中实现动态数据结构(如链表、树等)的关键。
动态数据结构:
链表:由一系列节点组成,每个节点包含数据和指向列表中下一个节点的指针。
栈:后进先出(LIFO)的数据结构,可以通过数组或链表实现。
队列:先进先出(FIFO)的数据结构,通常由链表实现。
树:一种分层的数据结构,每个节点可能有多个子节点。常见的树结构包括二叉树、搜索树(如二叉搜索树)、平衡树(如AVL树、红黑树)等。
图:由节点(也称为顶点)和连接这些节点的边组成的集合。图可以是有向的或无向的,并且边可以有权重。
位字段(Bit-fields):
结构体中的成员可以指定具体的位数,在需要精确控制内存布局或处理硬件接口时非常有用。
..........................................................................................................................................................
数据结构与算法的关系:
1. 数据结构是算法的基础
数据结构是算法操作的对象,定义数据之间的组织方式或存储方式。不同的数据结构适用于不同的场景和算法需求。算法的设计和实现往往依赖于所选的数据结构,因为算法的效率很大程度上取决于数据结构的特性。例如:在需要频繁查找、插入和删除操作的场景中,选择合适的数据结构(如:平衡二叉树或哈希表)可以显著提高算法的效率。
2. 算法是对数据结构的操作
算法是操作数据的步骤或方法,它告诉计算机如何执行特定的任务,以解决问题。算法的设计和实现需要考虑数据结构的特性,以便高效地处理数据。例如:排序算法(如:快速排序、归并排序)是对数组或链表等数据结构进行排序的方法,而搜索算法(如:二分搜索)则依赖于有序数组或链表等数据结构以提高搜索效率。
3. 数据结构与算法相互影响
数据结构与算法之间存在相互影响的关系。一方面,数据结构的选择会影响算法的效率。例如:在解决图问题时,选择邻接矩阵还是邻接表作为图的存储方式,会直接影响遍历图、查找边等操作的效率。另一方面,算法的设计也会影响数据结构的选择。有时候,为了优化算法的性能,可能需要设计新的数据结构或修改现有的数据结构。
4. 数据结构与算法共同支撑程序设计
一个好的程序设计需要选择合适的数据结构和算法来解决问题,以达到高效、可靠、易维护的目标。掌握数据结构与算法的知识对于提高程序设计的质量和效率具有重要意义。
...........................................................................................................................................................
链表的三要素主要包括:
节点(Node):
节点是链表中的基本单元,用于存储数据。每个节点通常包含至少两个部分:一部分用于存储数据(称为数据域),另一部分用于存储指向列表中下一个节点的指针(称为指针域或链域)。在某些情况下,如双向链表或循环链表,节点还可能包含指向前一个节点的指针。每个节点(包括链表的第一个节点)在内存中都有一个唯一的地址,这个地址是由操作系统在分配内存时确定的,用于访问该节点的数据和指针。这个地址是隐式的,通常在编写C语言代码时不需要直接操作(除非进行底层的内存管理或调试)。
头指针(Head Pointer):
头指针是一个特殊的指针,它指向链表中第一个节点的地址。对于空链表,头指针通常设置为NULL。头指针的作用是方便对整个链表的访问和操作,特别是当链表需要在其开始处进行添加或删除节点时。节点中的指针用于建立节点之间的链接。对于链表的第一个节点,它可能包含一个指向链表第二个节点的指针(在单向链表中)或两个指针:一个指向链表中的前一个节点(尽管对于第一个节点来说,这个指针可能是NULL或指向链表的尾节点,取决于链表的实现方式,如循环链表),另一个指向链表中的下一个节点。
链接关系(Linking):
链接关系定义了链表中节点之间的连接。在单向链表中,每个节点通过其指针域指向下一个节点,从而形成一个线性序列。在双向链表中,每个节点还包含指向前一个节点的指针,这使得从链表的任何节点都可以向前或向后遍历。在循环链表中,最后一个节点的指针指向链表的第一个节点(或头节点),形成一个环形结构。
测试代码:
#include "date.h"
#include <stdio.h>
#include <stdlib.h>
// 定义结构体 ListNode,包含一个整型数据 data 和一个指向下一个节点的指针 next。
typedef struct ListNode {
int data;
struct ListNode* next;
} ListNode;
// 创建节点的函数 createNode(int data),该函数会为新节点分配内存并初始化数据,返回新节点的指针。
ListNode* createNode(int data) {
ListNode* newNode = (ListNode*)malloc(sizeof(ListNode));
if (!newNode) {
printf("Memory allocation failed!\n");
exit(1);
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 向链表尾部添加节点的函数 appendNode(ListNode** head, int data),根据传入的链表头指针和数据,在链表尾部添加新节点。
void appendNode(ListNode** head, int data) {
ListNode* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
ListNode* temp = *head;
while (temp->next != NULL) {
temp = temp->next;
}
temp->next = newNode;
}
}
// 打印链表信息的函数 printList(ListNode* head),遍历链表并输出每个节点的地址、数据和下一个节点的地址。
void printList(ListNode* head) {
ListNode* current = head;
while (current != NULL) {
printf("Node Address: %p\n", (void*)current);
printf("Node Data: %d\n", current->data);
if (current->next != NULL) {
printf("Next Node Address: %p\n", (void*)current->next);
} else {
// 链表最后一个节点地址为NULL
printf("Next Node is NULL\n");
}
printf("\n"); // 添加空行以便区分不同的节点信息
current = current->next;
}
}
// 释放链表内存的函数 freeList(ListNode* head),遍历链表并释放每个节点的内存。
void freeList(ListNode* head) {
ListNode* temp;
while (head != NULL) {
temp = head;
head = head->next; // 移动到下一个节点
free(temp); // 释放当前节点的内存
}
}
int main() {
int time = getTime();
// 初始化链表(初始化头指针)
ListNode* head = NULL; // 链表一开始是空的
// 向链表添加节点和数据
appendNode(&head, 10);
appendNode(&head, 2);
appendNode(&head, 50);
appendNode(&head, 6);
appendNode(&head, 38);
// 打印整个链表的信息
printList(head);
// 释放链表的内存
freeList(head);
return 0;
}
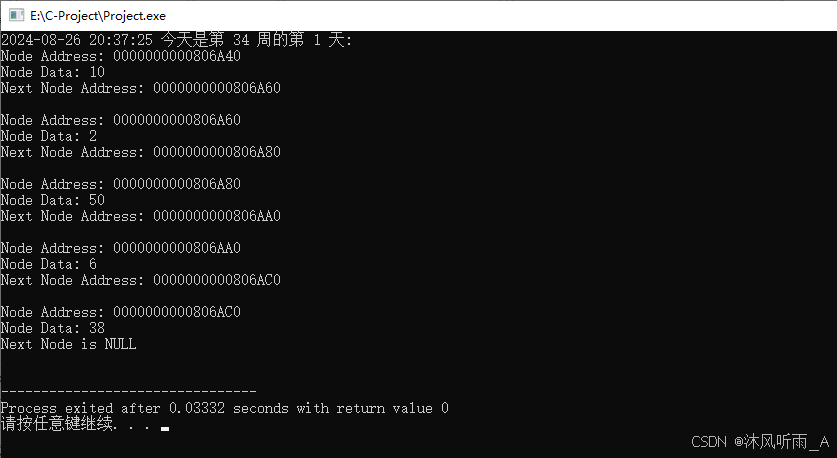
运行结果如下:

















 2498
2498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









