




目录
常见用法
1、字符串的初始化
有以下几种初始化方法:
// 不初始化
string s1;
// 用字符串初始化
string s2("张三");
// 或
string s2 = “李四”; // = 的运算符重载;
// 用字符和数字初始化
string s3('*',10); // 初始化为 10 个 “ * ”
// 拷贝构造
string s4(s3);
string s5 = s4;
// 用另一个字符串的部分来初始化
string s6(s2,1,1); //初始化为 “三”
string s7(s2,0); //第三个参数是缺省参数,如果使用缺省值,一直取到尾。初始化为 “张三”string 的构造函数:

2、输入输出字符串
输出字符串
string 类重载了 << 运算符:
string s1 = "Hello world";
cout<< s1 <<endl;输入字符串
string 类重载了 >> 运算符:
string s1;
cin >> s1;string 的写时复制(COW)优化
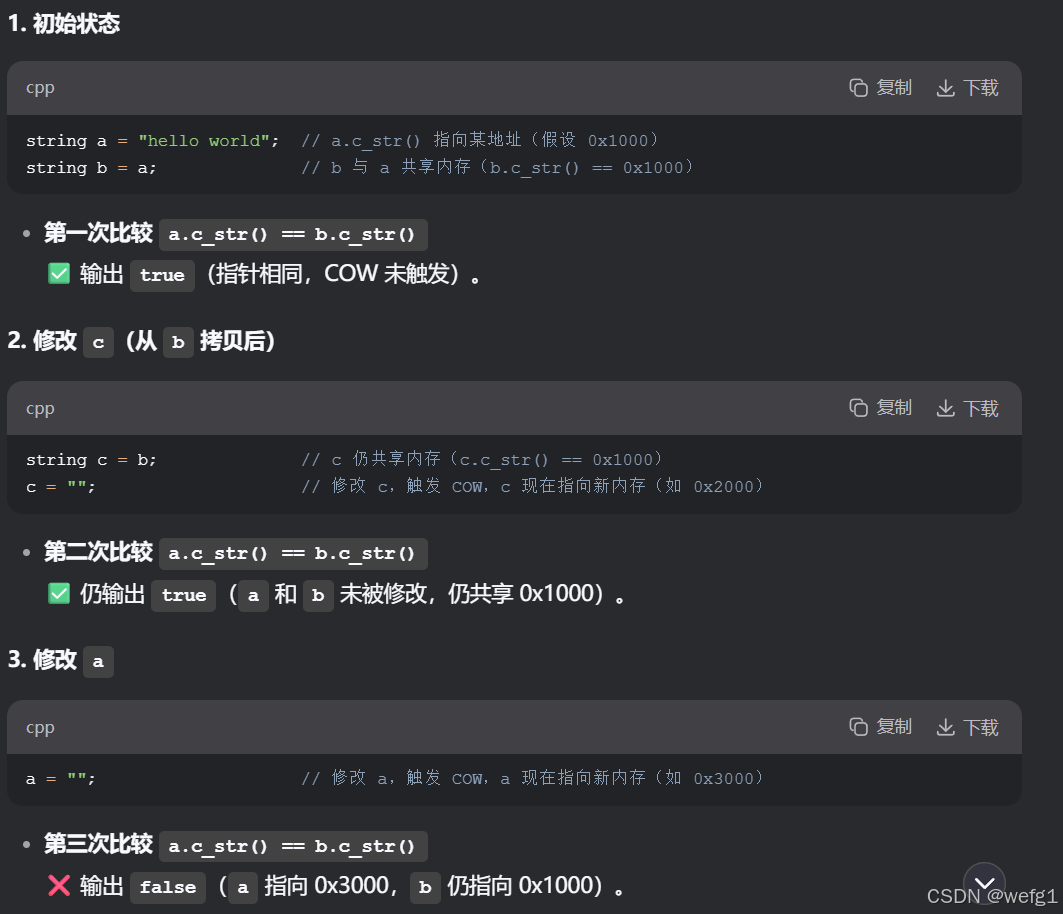
关于代码输出正确的结果是( )(vs2013 环境下编译运行)
int main(int argc, char *argv[])
{
string a="hello world";
string b=a;
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
string c=b;
c="";
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
a="";
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
return 0;
}VS2013 的
std::string可能使用 COW:当
b = a时,b和a共享同一块内存(c_str()返回的指针相同)。当修改
b或a时(如c = ""或a = ""),才会触发 真正的拷贝(此时c_str()指针不同)。
为什么不是所有环境都这样?
COW 行为依赖实现:
- VS2013 的
std::string可能用 COW,但 C++11 标准后禁止 COW(因多线程安全问题)。- 现代编译器(如 GCC/Clang)通常直接输出
false false false(无 COW)。
输入的字符串中有空格的处理
使用 getline 函数:
string s1;
cin >> s1; // 输入 Hello world,s1 为 Hello,world 没有读到
getline(cin,str); // 输入 Hello world,s1 为 Hello world3、字符串比较
string 类重载了关系运算符
s1 > s2;4、字符串的增删查改
字符串的尾插
push_back 函数:尾插一个字符
string s1("hello");
s1.push_back(‘a’); // s1 后面插入 ‘a’ , s1 变为 helloaappend 函数:尾插一个字符串
string s1("hello");
s1.append(" world"); //s1 后面插入" world" , s1 变为 hello worldoperator+= 函数:尾插一个字符或字符串(复用 push_back、append)
string s1("hello");
s1 += “ world”;(assign 函数:用一个字符串覆盖原有的字符串:)
string s1("Hello world");
s1.assign("xxxxxx"); // s1 变为 xxxxxx修改字符串
string 类重载了[ ] 运算符,可以对字符串的任意字符进行修改:
string s1("hello world");
s1[0]++;如果越界访问,会有 assert 错误。
insert 函数
使用 insert 函数可以在字符串的任意位置插入任意的字符或字符串,尽量不要使用头插,效率低
string s1("Hello world");
s1.insert(0,10,'x'); // 在 0 位置之前插入 10 个 ‘x’ ,s1 变为 xxxxxxxxxxHello world
s1.insert(s1.begin(),'x'); // 在 0 位置之前插入 ‘x’ ,s1 变为 xHello world
s1.insert(s1.begin() + 10,'x'); // 在 10 位置之前插入 ‘x’ ,s1 变为 Hello worldxerase 函数
使用 erase 函数可以在字符串的任意位置删除任意长度的字符串(不能越界):
string s1("Hello world");
s1.erase(5,1); // 在 5 位置删除一个字符,s1 变为 Helloworld
s1.erase(5); // 删除 5 位置之后的所有字符,s1 变为 Hello字符串的扩容机制
当字符串需要扩容时,怎么扩容取决于编译器。
reserve 函数
string 类还有一个 reserve 函数用来指定 string 对象的长度:
string s1;
s1.reserve(100);// 指定 s1 的大小是 100使用 reserve 函数的场景:知道字符串的长度,提前为该字符串预留空间,避免频繁开空间降低效率。
使用 reserve 函数指定 string 对象的长度时,对象的实际长度可能比指定的大小要大一些。如果使用该函数来指定一个比原来长度要小的长度,那么长度是否变小取决于编译器(一般不会缩)。
push_back 函数和 append 函数内部如果要扩容,调用的是 reserve 函数
resize 函数
reserve 函数只改变字符串的容量(capacity),不改变字符串的有效字符。而 resize 函数既改变字符串的容量,又对非有效字符进行初始化:
string s1("Hello world");
s1.resize(100); // s1 的 size 变为 100,非有效字符初始化为 \0
s1.resize(100,'x'); // s1 的 size 变为 100,非有效字符初始化为 'x'如果使用该函数来指定一个比原来长度要小的长度,那么只会改变 size 不会改变 capacity。
清除字符串
要清空字符串的有效字符,可以使用 clear 函数:
string s1("hello world");
s1.clear();clear()只是将string中有效字符清空,不改变底层空间大小

5、遍历字符串
string 类重载了 [ ] ,可以用字符串名 [ 下标 ] 的方式访问字符串的一个字符。string 类还有一个 size 函数,用来返回字符串的长度(不包括 \0)。(由于 string 类的编写比 stl 要早,所以 string 类最开始不符合 stl 的标准,string 类最开始使用 length 函数来返回字符串的长度。. size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一 致,一般情况下基本都是用size()。)
string s1("hello world");
for(int i = 0; i < s1.size(); i++)
{
cout << s1[i] ;
}
cout << endl;字符数组的 [ ] 与 string 的 [ ] 的区别:
char s1[] = "hello world";
s1[0]; // 对指针的解引用操作:*(s1 + 0)
string s2("hello world");
s2[0]; // 函数重载:s2.operator[](0)使用 [ ] 访问 string 容器时,只能在 size 以内的地方访问,而不是在开辟的空间内对任意位置进行访问。(operator[] 函数会检查下标是否小于 size ( assert( i < _size);))
使用迭代器遍历:
string s1("hello world");
string::iterator it = s1.begin();
while(it != s1.end())
{
cout << *it ;
++it;
}
cout << endl;反向迭代器:从末尾到开头的遍历
string s1("hello world");
string::reverse_iterator rit = s1.rbegin();
// 使用 auto 简化:auto rit = s1.rbegin();
while(rit != s1.rend)
{
cout << *rit ;
rit++;
}
cout << endl;常对象只能使用常迭代器来遍历
const string s1("hello world");
string const_iterator it = s1.begin;
string const_reverse_iterator it = s1.rbegin;
//...使用范围 for 来遍历:
string s1("hello world");
for(auto e : s1) // auto 也可以是 char
{
cout << e ;
}
cout << endl;6、与 C 语言接口的配合
string 类的 char* 成员可以用 c.str 函数返回,以便与 C 语言配合:
// c的一些接口函数配合
string filename = "test. cpp";
FILE* fout = fopen(filename.c_str(), "r");
7、在一个字符串中寻找
find 函数:
使用 find 函数可以在一个字符串中寻找目标字符串,如果找到了,返回该字符串的第一个位置的下标,如果没有找到,返回 npos。
string s1("Hello world");
size_t ret = s1.find("world"); // 在 0 位置开始寻找 "world",将 ‘w’ 的下标 6 赋给 ret
size_t ret = s1.find("world",1); // 在 1 位置开始寻找 "world",将 ‘w’ 的下标 6 赋给 ret还有一个 rfind 函数,它的功能与 find 一样,只是 rfind 是从后往前找。
可以配合 substr 函数将目标字符串截取出来:
substr 函数:
在str中从pos位置开始,截取n个字符,然后将其返回
string s1("Hello world");
size_t ret = s1.find("world");
string s2 = s1.substr(ret); // 从 ‘w’ 开始到 s1 末尾,截取 “world” 并返回给 s2
string s3 = s1.substr(ret,2); // 截取从 ‘w’ 开始的两个字符 “wo” 返回给 s3解析网址:
将任意的一个网址(字符串)的协议、域名、资源拆分到不同的字符串:
#include<iostream>
#include<string>
using namespace std;
int main()
{
string url("https://mpbeta.youkuaiyun.com/mp_blog/creation/editor/148351479");
//拆分协议到一个字符串
//不能寻找 https,因为协议还有 http、ftp等,应该寻找 "://"
size_t pos1 = url.find("://");
if (pos1 != string::npos) // 检查返回值
{
string protocol = url.substr(0, pos1);
cout << protocol << endl;
}
//拆分域名到一个字符串
//要从"://"的下一个位置开始寻找,不然返回的是"://"中‘/’的位置
size_t pos2 = url.find('/',pos1 + 3);
if (pos2 != string::npos) // 检查返回值
{
string domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << domain << endl;
string uri = url.substr(pos2 + 1);
cout << uri << endl;
}
return 0;
}substr 函数: 在str中从pos位置开始,截取n个字符,然后将其返回
8、字符串转换函数
数字转 string
to_string 函数可以将任何类型的数值转换为 string 类,然后返回转换后的 string 类对象:

使用示例:
string s = to_string(1234);string 转数字
有以下接口,stoi 的意思就是 string to integer。

使用示例:
string s("-123456");
int ret = stoi(s);9、字符串oj题

class Solution {
public:
string addBinary(string a, string b) {
int t = 0;
string ret("");
int cur1 = a.size() - 1;
int cur2 = b.size() - 1;
while(cur1 >= 0 || cur2 >= 0 || t)
{
if(cur1 >= 0) t += a[cur1--] - '0';
if(cur2 >= 0) t += b[cur2--] - '0';
ret += t % 2 + '0'; // 不要使用头插,效率低
t /= 2;
}
reverse(ret.begin(),ret.end());
return ret;
}
};模拟实现
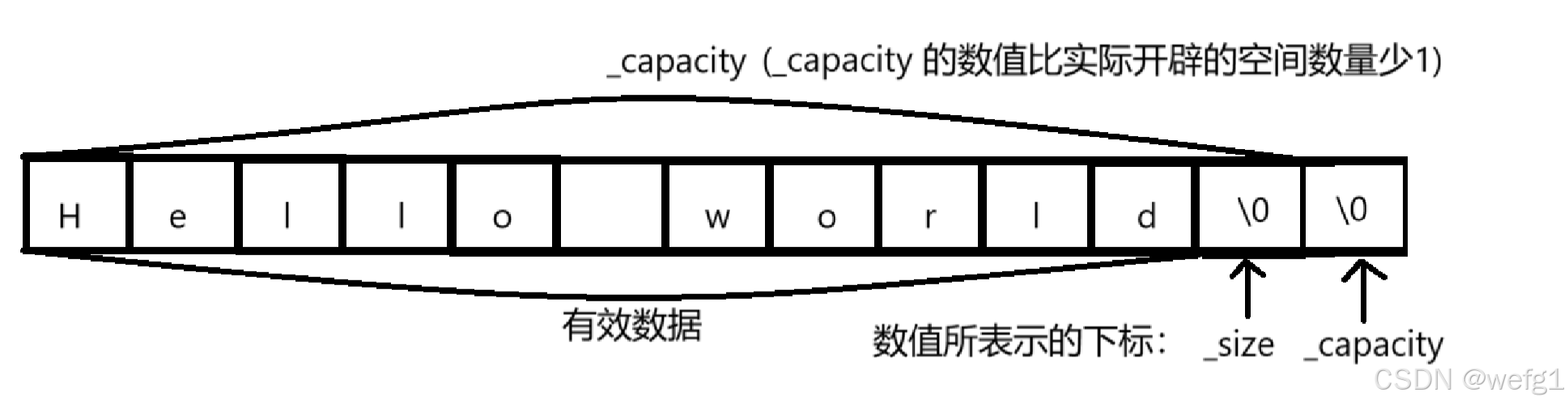
_size 和 _capacity 的说明
代码和注释
头文件:
#pragma once
#include<iostream>
#include<string.h>
#include<assert.h>
using namespace std;
namespace My_string
{
class string
{
friend ostream& operator<<(ostream& _cout, const My_string::string& s);
friend istream& operator>>(istream& _cin, My_string::string& s);
public:
typedef char* iterator;
typedef const char* const_iterator;
string(const char* str = "");
string(const string& s);
string& operator=(string tmp);
~string();
// iterator
iterator begin();
iterator end();
iterator begin()const;
iterator end()const;
// modify
void push_back(char c);
string& operator+=(char c);
void append(const char* str);
string& operator+=(const char* str);
void clear();
void swap(string& s);
const char* c_str()const;
// capacity
size_t size()const;
size_t capacity()const;
bool empty()const;
void resize(size_t n, char c = '\0');
void reserve(size_t n);
// access
char& operator[](size_t index);
const char& operator[](size_t index)const;
size_t size();
//relational operators
bool operator<(const string& s);
bool operator<=(const string& s);
bool operator>(const string& s);
bool operator>=(const string& s);
bool operator==(const string& s);
bool operator!=(const string& s);
// 返回c在string中第一次出现的位置
size_t find(char c, size_t pos = 0) const;
// 返回子串s在string中第一次出现的位置
size_t find(const char* s, size_t pos = 0) const;
// 在pos位置上插入字符c/字符串str,并返回该字符的位置
iterator insert(size_t pos, char c);
iterator insert(size_t pos, size_t num, char c);
iterator insert(size_t pos, const char* str);
// 删除pos位置上的元素,并返回该元素的下一个位置
iterator erase(size_t pos, size_t len = 1);
char* _str;//放在 public 便于调试
private:
size_t _capacity;
// _capacity 是开辟的空间的最后的元素的下标,该位置永远为'\0'预留,实际的空间大小 = _capacity + 1;
size_t _size;
// _size 是最后一个有效字符的下标 + 1;
};
}
函数实现:
#define _CRT_SECURE_NO_WARNINGS 1
#include "Mystring.h"
My_string::string::string(const char* str):
_str(new char[strlen(str) + 1]),// 多开一个空间来存储 '\0'
// 注意头文件中声明的_capacity和_size的意义
_capacity(strlen(str)),
_size(strlen(str))
{
strcpy(_str, str);// strcpy 会拷贝 '\0'
}
My_string::string::string(const string& s)
{
// 深拷贝
_str = new char[s._capacity + 1];
memcpy(_str, s._str, s._capacity + 1);
// 为什么不使用 strcpy ?因为 string 对象的长度由 _size 决定,不由 '\0' 决定,strcpy遇到第一个'\0'就停止了。
_capacity = s._capacity;
_size = s._size;
}
My_string::string& My_string::string::operator=(string tmp)
{
// tmp 是通过拷贝构造的临时对象,是等号右边的对象的深拷贝
swap(tmp);
return *this;
// tmp 被析构
}
My_string::string::~string()
{
delete[] _str;
_size = 0;
_capacity = 0;
}
void My_string::string::push_back(char c)
{
if (_capacity == _size)
{
// 如果对象是用 "" 初始化的,那么 _size 和 _capacity 都是 0,不能直接 reserve(_capacity * 2)
// 2 倍扩容,减少扩容次数
reserve((_capacity == 0 ? 15 : _capacity) * 2);
}
_str[_size] = c;
_str[_size + 1] = '\0';
_size++;
}
const char* My_string::string::c_str() const
{
return _str;
}
void My_string::string::append(const char* str)
{
if (_size + strlen(str) > _capacity)
{
// reserve(_capacity * 2) 可能还是小了,至少要开 _size + strlen(str) + 1 的空间
reserve((_capacity + strlen(str)) * 2);
}
// 字符串拼接函数
strcat(_str, str);
_size += strlen(str);
_str[_size] = '\0';
}
My_string::string& My_string::string::operator+=(char c)
{
push_back(c);
return *this;
}
My_string::string& My_string::string::operator+=(const char* str)
{
append(str);
return *this;
}
void My_string::string::clear()
{
_size = 0;
_str[_size] = '\0';
}
size_t My_string::string::size()const
{
return _size;
}
size_t My_string::string::capacity()const
{
return _capacity;
}
bool My_string::string::empty()const
{
if (_size == 0)
{
return true;
}
else
{
return false;
}
}
void My_string::string::reserve(size_t n)
{
if (n > _capacity)
{
// 注意要开 n + 1 个空间,而不是 n 个空间,为'\0'留位置
char* tmp = new char[n + 1];
// strcpy(tmp, _str); 错误
memcpy(tmp, _str, _capacity + 1);
delete[] _str;
_capacity = n;
_str = tmp;
}
}
void My_string::string::resize(size_t n, char c)
{
if (n < _size) // 缩小
{
_size = n;
_str[_size] = '\0';
}
else if (n > _size) // 扩大
{
if (n > _capacity)
{
reserve(n * 2);
}
for(size_t i = _size; i < n; i++)
{
_str[i] = c;
}
_size = n;
_capacity = 2 * n;
_str[_size] = '\0';
}
}
char& My_string::string::operator[](size_t index)
{
assert(index < _size); //只能访问有效字符
return _str[index];
}
const char& My_string::string::operator[](size_t index)const
{
assert(index < _size); //只能访问有效字符
return _str[index];
}
bool My_string::string::operator<(const string& s)
{
//
// 如果在两个字符串较小的长度内有字符不同,比如 |aaa|aaa 和 |bbb|,memcmp 可以在相同的长度内比较出大小
// 如果在两个字符串较小的长度内字符相同,比如:
// Hello 和 Hello false
// Helloxxx 和 Hello false
// Hello 和 Helloxxx true
// memcmp 就不能在相同的长度内比较出大小,此时谁的长度长谁就大
return memcmp(_str, s._str, _size > s._size ? s._size : _size) && _size < s._size;
}
bool My_string::string::operator<=(const string& s)
{
return (*this < s) || (*this == s);
}
bool My_string::string::operator>(const string& s)
{
return !(*this <= s);
}
bool My_string::string::operator>=(const string& s)
{
return !(*this < s);
}
bool My_string::string::operator==(const string& s)
{
// 先比较长度更好
return _size == s._size && memcmp(_str, s._str, _size) == 0;
}
bool My_string::string::operator!=(const string& s)
{
return !(*this == s);
}
size_t My_string::string::find(char c, size_t pos) const
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
{
return i;
}
}
//如果没有找到就返回 -1;
return -1;
}
size_t My_string::string::find(const char* s, size_t pos) const
{
assert(pos < _size);
// strstr 函数:例如 strstr(s1,s2); 作用是检查在 s1 字符串中是否有完整的 s2 字符串
// 如果有,返回 s2 第一次出现在 s1 的位置指针,如果没有,返回NULL;
if (strstr(_str + pos, s) != NULL)
{
// strstr 函数返回的是指针,该函数要返回下标,所以通过指针减指针的方式获取下标。
return strstr(_str + pos, s) - _str;
}
//如果没有找到就返回 -1;
return -1;
}
My_string::string::iterator My_string::string::insert(size_t pos, char c)
{
// 如果 string 是空的,直接 assert(pos < _size);会报错
if (_size != 0)
{
assert(pos < _size);
}
else
{
*this += c;
}
//扩容
if (_size == _capacity)
{
reserve(_capacity * 2);
}
// 挪数据
for (int i = (int)_size; i >= (int)pos; i--)
{
_str[i + 1] = _str[i];
}
// 插入字符
_str[pos] = c;
_size++;
// 返回更新后的迭代器
return &_str[pos];
}
My_string::string::iterator My_string::string::insert(size_t pos, size_t num, char c)
{
// 如果 string 是空的,直接 assert(pos < _size);会报错
if (_size != 0)
{
assert(pos < _size);
}
else
{
while (num--)
{
*this += c;
}
return &_str[pos];
}
// 扩容
if (_size + num > _capacity)
{
reserve((_capacity + num) * 2);
}
// 挪数据
for (int i = (int)_size - 1; i >= (int)pos; i--)
{
_str[i + num] = _str[i];
}
// 插入字符串
for (int i = (int)pos; i <= (int)pos + num - 1; i++)
{
_str[i] = c;
}
_size += num;
_str[_size] = '\0';
// 返回更新后的迭代器
return &_str[pos];
}
My_string::string::iterator My_string::string::insert(size_t pos, const char* str)
{
// 如果 string 是空的,直接 assert(pos < _size);会报错
if (_size != 0)
{
assert(pos < _size);
}
else // 如果 string 是空的,可以使用append函数
{
append(str);
return &_str[pos];
}
int num = (int)strlen(str);
// 扩容
if ((int)_size + num > (int)_capacity)
{
reserve((_capacity + num) * 2);
}
// 挪数据
for (int i = (int)_size - 1; i >= (int)pos; i--)
{
_str[i + num] = _str[i];
}
// 插入字符串
int j = 0;
for (int i = (int)pos; i <= (int)pos + num - 1; i++)
{
_str[i] = str[j];
j++;
}
_size += num;
_str[_size] = '\0';
// 返回更新后的迭代器
return &_str[pos];
}
void My_string::string::swap(string& s)
{
char* tmp = _str;
_str = s._str;
s._str = tmp;
size_t tmp1 = _size;
_size = s._size;
s._size = tmp1;
size_t tmp2 = _capacity;
_capacity = s._capacity;
s._capacity = tmp2;
}
// 左闭右开 [begin , end)
My_string::string::iterator My_string::string::begin()
{
return _str;
}
My_string::string::iterator My_string::string::end()
{
// 不能 return _str +_size - 1; 注意左闭右开
return _str + _size;
}
// 左闭右开 [begin , end)
My_string::string::iterator My_string::string::begin() const
{
return _str;
}
My_string::string::iterator My_string::string::end() const
{
// 不能 return _str +_size - 1; 注意左闭右开
return _str + _size;
}
My_string::string::iterator My_string::string::erase(size_t pos, size_t len)
{
assert(pos + len - 1 < _size);
if (_size > 0)
{
for (int i = (int)(pos + len); i < (int)_size; i++)
{
_str[i - len] = _str[i];
}
_size -= len;
_str[_size] = '\0';
}
// 返回更新后的迭代器
return &_str[pos];
}
size_t My_string::string::size()
{
return _size;
}
ostream& My_string::operator<<(ostream& _cout, const My_string::string& s)
{
if (s.size() > 0)
{
for (size_t i = 0; i < s.size(); i++)
{
_cout << s[i];
}
/*for (auto ch : s)
{
_cout << ch;
}*/
}
return _cout;
}
istream& My_string::operator>>(istream& in, string& s)
{
s.clear();
char ch = in.get();
// 处理前缓冲区前面的空格或者换行
while (ch == ' ' || ch == '\n')
{
ch = in.get();
}
//in >> ch;
char buff[128];
int i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
buff[i] = '\0';
s += buff;
i = 0;
}
//in >> ch;
ch = in.get();
}
if (i != 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}
















 2256
2256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









