




 本文介绍了一种新的强化学习算法DropoutQ,它在REDQ的基础上引入随机dropout和层归一化,以提高算法的样本效率。DropoutQ通过减少集成Q模型的数量,同时保持计算效率,与REDQ相比有更高的性能优化。
本文介绍了一种新的强化学习算法DropoutQ,它在REDQ的基础上引入随机dropout和层归一化,以提高算法的样本效率。DropoutQ通过减少集成Q模型的数量,同时保持计算效率,与REDQ相比有更高的性能优化。
Introduction
update-to-date(UTD)指智能体更新次数与环境交互次数的比值。高UTD能够在较少交互步数下多次更新Q价值,进而帮助提高算法的sample efficiency,例如MBPO的UTD在20-40。REDQ则是利用Q集成,实现在model-free下的高UTD。然而集成Q在SAC的计算效率(computational efficiency)较低,因此本文在REDQ基础提出Dropout Q、在一个较少数量的集成Q模型中,对价值网络添加随机dropout以及layer normalization,进一步提高算法的sample efficiency。
Method
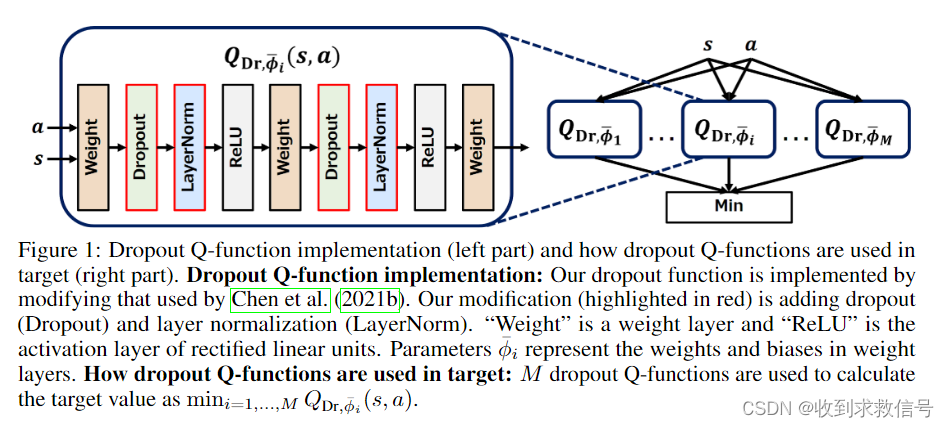

算法维持M个 Q D r Q_{Dr} QDr网络,网络结构中包含Dropout以及Layer Normalization。
在REDQ中,对target Q的估计是从N个不带Dropout的Q函数中,随机sample出M个预测值,选取其最小值作为估计的target_Q。而DroQ则是直接设置M个 Q D r Q_{Dr} QDr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









