




 提出一种改进的TextBoxes方法,能够预测任意四边形或多方向文本,通过增加倾斜矩形及四边形的边界框回归损失,提高检测精度。
提出一种改进的TextBoxes方法,能够预测任意四边形或多方向文本,通过增加倾斜矩形及四边形的边界框回归损失,提高检测精度。
- https://www.cnblogs.com/lillylin/p/9955264.html
方法亮点
把原本只能做水平的TextBoxes改为可以预测任意四边形的多方向文本检测
除了常规的分类、回归损失,还增加了四边形的最外接矩形的回归损失(增加监督信息量)
方法概述
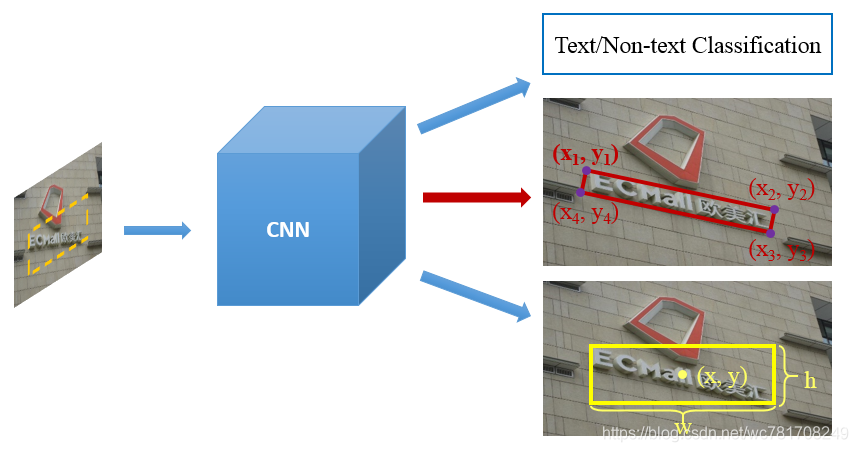
本文方法是对TextBoxes(水平文字检测)进行改进,用于多方向文字检测。和SSD一样,该方法是one-stage的端到端模型,测试时只需运行网络+NMS即可得到检测结果(倾斜矩形或者任意四边形)。
方法主要改进点有:
第一,预测的目标从水平框的 ( x , y , w , h ) (x, y, w, h) (x,y,w,h) 变成了任意四边形 ( x 1 , y 1 , x 2 , y 2 , x 3 , y 3 , x 4 , y 4 ) (x_1, y_1, x_2, y_2, x_3, y_3, x_4, y_4) (x1,y1,x2,y2,x3,y3,x4,y4) 或 倾斜矩形 ( x 1 , y 1 , x 2 , y 2 , h ) (x1, y1, x2, y2, h) (x1,y1,x2,y2,h);
第二,回归损失除了增加oriented-text的位置regression loss,还增加了包含oriented-text的boundingBox(最小外接正矩形)的regression loss;
方法细节
网络结构
网络结构如下,VGG-16的前13层 + 10个额外卷积层 + 6个Text-box层 = 29层(和TextBoxes类似,FPN结构)

Default box
(实际是水平的default box,以下为方便可视化后面预测的 q {q} q or r {r} r 故配图使用倾斜框)
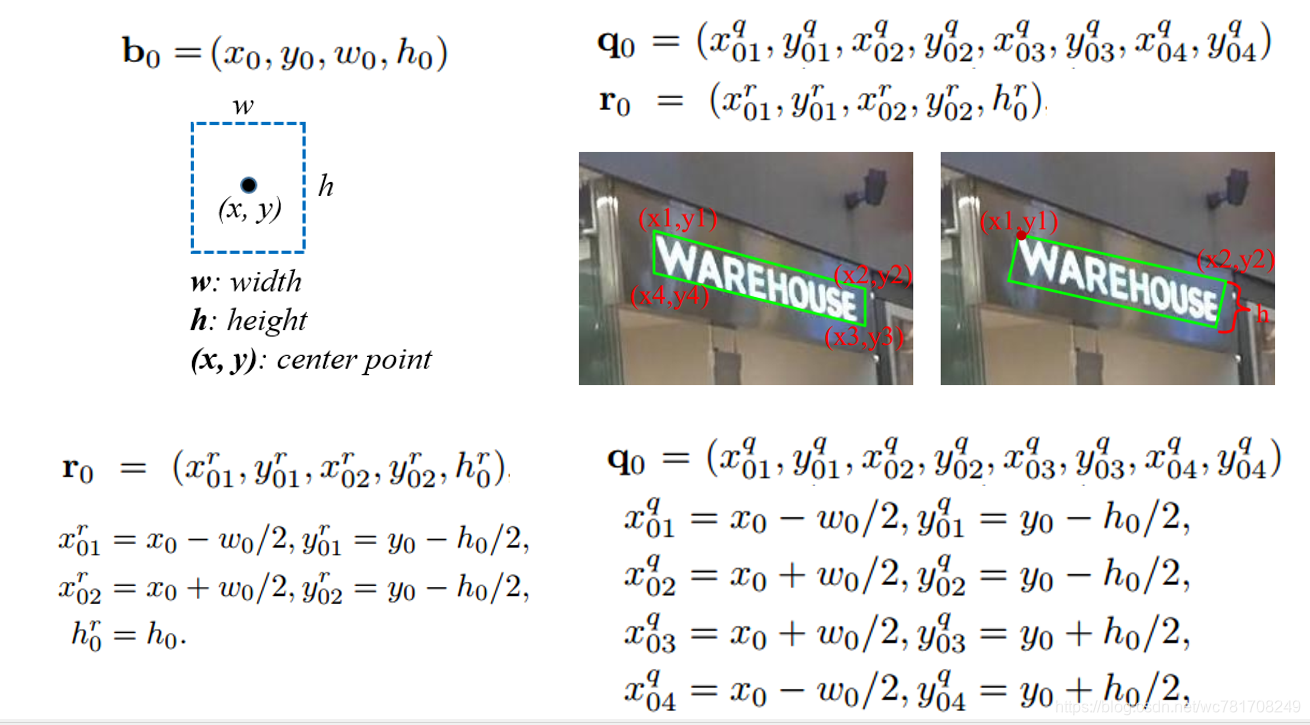
预测四边形和倾斜矩形
默认的anchor 任然是正常的anchor 未加上旋转;计算IOU使用旋转框的最小外接矩形来计算的 而不是使用旋转矩形来计算
下图Fig.3中,黄色实线框为oriented bounding boxes q {q} q or r {r} r ,绿色实线框为minimum horizontal bounding rectangles b {b} b,绿色虚线框为对应match的default box。
predict的${b} , q ,{q} ,q , r {r} r 与default box的regression shift计算公式如下(下标为0表示是default box的相应值)
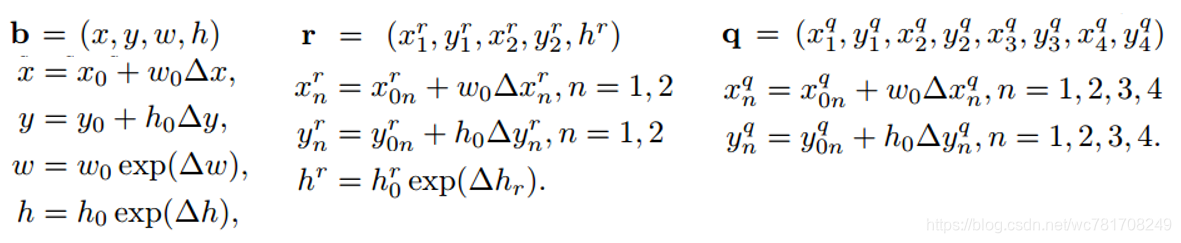
其他细节点
default box的aspect ratio从1,2,3,5,7 换成1,2,3,5, 1 2 \frac{1}{2} 21, 1 3 \frac{1}{3} 31, 1 5 \frac{1}{5} 51
vertical offset和textBoxes一样(竖直的step更小,更dense一些而已)
text-box layer的convolutional filter从 1 x 5 1x5 1x5变成 3 x 5 3x5 3x5
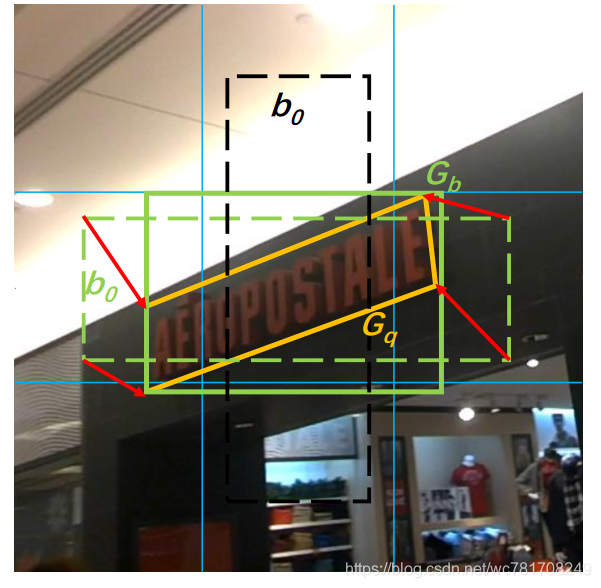
如何统一四边形的四个点的顺序?
简单说,首先算出四个点的最外接正矩形 G b = ( b 1 , b 2 , b 3 , b 4 ) G_b = (b_1, b_2, b_3, b_4) Gb=(b1,b2,b3,b4), 正矩形有top-left点的概念(最左上角点)。然后依次算出 G q = ( q 1 , q 2 , q 3 , q 4 ) G_q = (q_1, q_2, q_3, q_4) Gq=(q1,q2,q3,q4)的四个点和 G b G_b Gb的四个点的欧氏距离(都按顺时针或者逆时针方式连接点),求出使得欧氏距离和最小的时对应的 G q G_q Gq的点顺序即为最终四个点的关系(此时,第一个点可以认为是top-left点)。如下图所示,左图比右图距离和更小,故采用左图的点顺序关系。
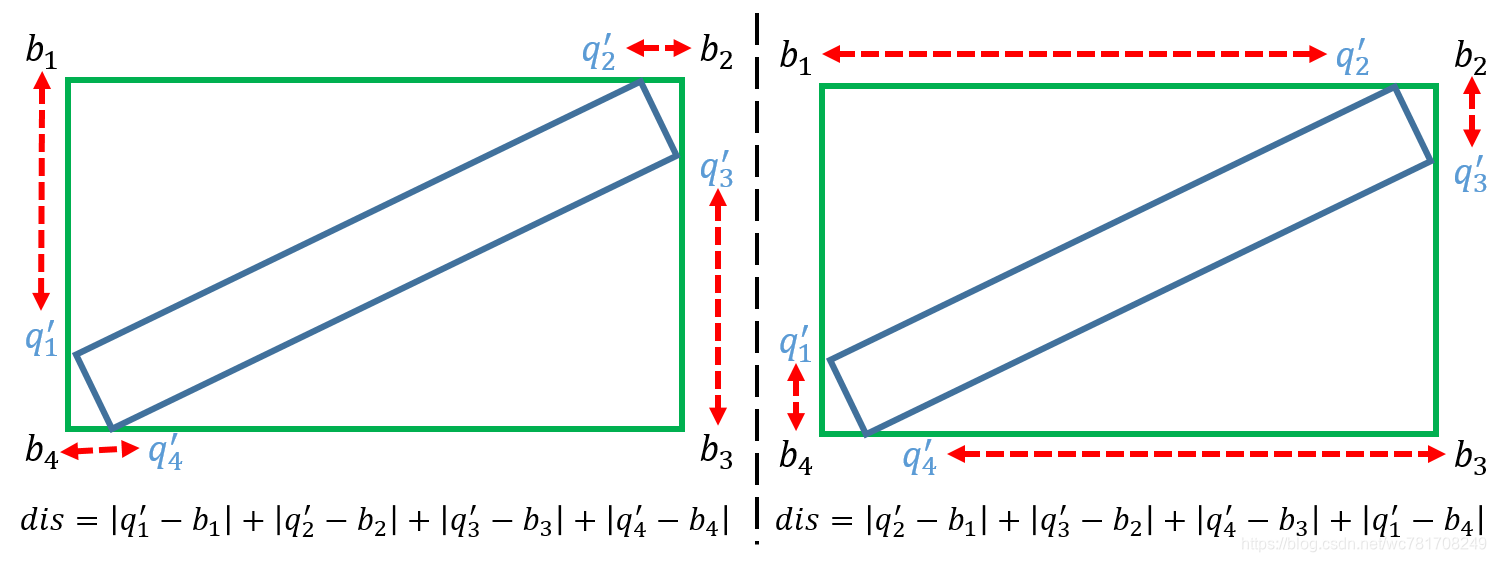
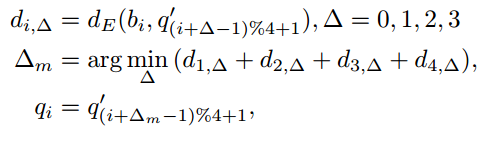
使用 ( x , y , w , h , θ ) (x, y, w, h, \theta) (x,y,w,h,θ)还是 ( x 1 , y 1 , x 2 , y 2 , h ) (x_1, y_1, x_2, y_2, h) (x1,y1,x2,y2,h)?
使用 θ \theta θ具有数据集的偏向性(某些数据集可能水平文字比较多, θ \theta θ普遍比较小,那么模型学出来的 θ \theta θ也比较小),而采用 ( x 1 , y 1 , x 2 , y 2 , h ) (x_1, y_1, x_2, y_2, h) (x1,y1,x2,y2,h)方式则会避免该问题。
However, due to the bias of the dataset, there is usually an uneven distribution on θ, which may make the model dataset-dependent.
在data augmentation时,除了用Jaccard overlap作为crop的标准外(小目标仅用IOU会导致小目标可能占了全图比例过大?),增加object overlap标准来判断是否crop。->个人认为,其实是增加一个指标/参数,控制目标在整张图中的比例不至于过大。
训练的前期可以用小的scale,后期用大的scale,可以加速
NMS加速
先使用四边形的boundingBox来做NMS_bb(速度更快),阈值可取大如0.5。再在剩下的四边形做NMS_polygon,阈值可取小一些如0.2。
检测+识别的综合打分
s d = 0.6 , s r = 0.005 s_d = 0.6,s_r = 0.005 sd=0.6,sr=0.005,使用指数更平滑,检测+识别取平均更好。

















 5515
5515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









