



 本文介绍了一种常用的监督学习方法——kNN算法,并通过Python代码实现了该算法。算法基于欧式距离度量,采用投票法进行预测。以西瓜数据集3.0α为例,展示了如何读取数据并应用kNN算法进行预测。
本文介绍了一种常用的监督学习方法——kNN算法,并通过Python代码实现了该算法。算法基于欧式距离度量,采用投票法进行预测。以西瓜数据集3.0α为例,展示了如何读取数据并应用kNN算法进行预测。
kNN学习是一种常用的监督学习方法,原理可以说是相当简单了:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测,在分类任务中,一般采用“投票法”。
根据周志华老师在《机器学习》一书中给出的原理,用Python实现这一算法。
距离度量采用欧式距离,预测则采用“投票法”,具体代码如下所示:
import numpy as np
import pandas as pd
import random
from collections import Counter
#使用欧式距离
#使用投票法
#数据类型(x,y),x为向量,y为种类
def kNN(D, k, x):
m = len(D)
dis = [np.linalg.norm(D[i][0]-x) for i in range(m)]
count = 0
mark = []
while count<k:
mark.append(D[dis.index(min(dis))][1])
dis.remove(min(dis))
count = count + 1
markCounter = Counter(mark).most_common(1)
return markCounter[0][0]
#读入数据
pf = pd.read_excel('西瓜数据集3.0a.xlsx')
D = [(np.array([pf.ix[i].values[1],pf.ix[i].values[2]]),pf.ix[i].values[3]) for i in pf.index.values]
x = np.array([random.random(),random.random()])
print('测试数据--密度:',x[0],',含糖率:',x[1])
print('预测结果:', kNN(D, 5, x))
print('预测结果:', kNN(D, 5, np.array([0.639,0.161])))
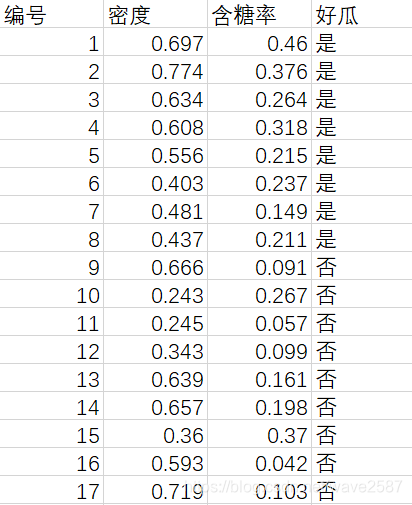
数据集采用的是西瓜数据集3.0α:

















 2558
2558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









