




 本文详细介绍了Redis中四种核心数据结构的实现和特性:SDS提供常数时间长度获取和二进制安全性,避免缓冲区溢出;AdList实现双端链表,支持不同类型值;Dict利用哈希表处理键值对,通过链地址法解决冲突并支持渐进式rehash;ZSkipList是跳跃表,用于有序集合,以多层索引加速查找。这些高效的数据结构支撑了Redis的高性能。
本文详细介绍了Redis中四种核心数据结构的实现和特性:SDS提供常数时间长度获取和二进制安全性,避免缓冲区溢出;AdList实现双端链表,支持不同类型值;Dict利用哈希表处理键值对,通过链地址法解决冲突并支持渐进式rehash;ZSkipList是跳跃表,用于有序集合,以多层索引加速查找。这些高效的数据结构支撑了Redis的高性能。
下表列出了 Redis 源码中, 各个数据结构的实现文件:
|
文件 |
内容 |
|---|---|
|
|
Redis 的动态字符串实现。 |
|
|
Redis 的双端链表实现。 |
|
|
Redis 的字典实现。 |
|
|
Redis 的跳跃表实现。 |
redis的数据结构,先抛出几个概念:字符串(SDS),链表(AdList),字典(Dict),跳跃表(zskiplist)
字符串(sds)
redis在c的基础上重新定义了字符串,用于数据库存储和缓冲区存储使用,那为什么要这么费劲呢,就要看看它和C的字符串有什么区别:
1 常数复杂度获取字符串长度
这就需要先看一下redis字符串是如何设计的,主要关注的行为点是什么
存储结构,不考虑具体header的情况下:
uint64_t len; /* 已使用 */
uint64_t alloc; /* 已分配,不包括末尾null */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
两条设计思路:
空字符:sds仍然沿用了c的以空字符串结尾的特性,主要从设计角度考虑复用;
长度:通过使用空间换时间的方式来存储字符串长度;
2 杜绝缓冲区溢出
什么是缓冲区,什么是缓冲区溢出
缓冲区可以简单的理解为字节数组,并已经为字节数组提前做好了内存分配;由于C对于数组越界没有检测机制,你将超出数组长度的字符串放入之后,它会将超出数组长度的内容输出到数组长度后面紧跟的存储区域,导致覆盖后面的内容;
那sds是通过什么手段才能避免出现这种溢出问题呢?
答案就要看它是怎么进行内存分配管理的,看下面👇
3 减少内存重分配
什么是内存重分配,什么情况下会出现内存重分配,通过什么方式减少了重分配的?
内存重分配:在C中操作字符串时,为了避免出现缓冲区溢出的现象,针对增长字符串在内存中重新分配空间,为了避免出现内存泄漏,针对缩短字符串也需要重新进行内存分配
减少重分配:即通过sds存储结构中的alloc属性,它的设计作用就是将数组长度与实际的字节数组解耦,通过len,alloc两个逻辑属性来描述字节数组,通过对接下来的相关行为提供了基础,主要策略包括:空间预分配和惰性空间释放,预分配和惰性释放,其实就是把内存重分配概率降低了,如果新增长度会优先使用未分配部分,如果之后没有发生变更会不会发生内存浪费和碎片呢?其实redis也想到了,sds提供了对应api来实现释放sds.h -> sdsRemoveFreeSpace
4 二进制安全
什么是二进制安全?C的字符串必须满足某种编码格式并且只能是末尾有空字符,使用场景太小了,所谓的二进制安全,就是redis处理字符串内容时会按照二进制的方式处理,所以sds结构中的buf实际存储的是二进制数据。
链表(adlist)
链表由链表和列表节点两部分构成,结构体如下
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
有几个点可以注意一下:
1 通过listnode看出来,它是一个双端链表
2 又是以空间换时间,存储了长度计数器
3 可以保存不同类型的值
字典(dict)
字典是redis数据库和哈希键的底层实现,好,那我们先跑出两个问题,字典的底层实现是什么呢,谈到hash,避不开键冲突和rehash,是怎么实现的呢,我们往下看。
字典使用哈希表作为底层实现,同java一样,hash表中包含entry,存储对应的key和value,结构如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /*解决键冲突时,构建单向链表*/
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table; /*这是一个数组*/
unsigned long size; /*hash表大小*/
unsigned long sizemask;
unsigned long used; /*已经使用的*/
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; /*rehash时使用*/
long rehashidx; /* rehash的进度 rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
我们主要看一下上面抛出的两个问题,键冲突和rehash
键冲突
采用链地址法,可以看到dictEntry中的next属性,
rehash
分配 - 迁移(计算)- 交换
从上面的结构体可以看到一个dict包含两个hashtable,rehash时首先会分配一个新的hashtable1,将hashtable0的key重新计算到hashtable1,进行swap,并分配一个空的hashtable给hashtable1。
rehash的触发条件是什么,期间发生了读写怎么办,rehash过程中如何保证数据的完整性或者说正确性
扩展触发时机:当RDB持久化模式下发生bgsave或者AOF持久化模式下bgrewriteaof发生时(这两个是通过主线程fork出子线程,用来处理后台持久化) ,同时factor(used / size)大于等于5
扩展触发时机:当未发生上面两个事件时,factor大于等于1
收缩触发时机:factor小于0.1时,自动执行收缩
渐进式:整个hashtable过大,rehash过程产生的计算量会影响服务,通过分治的方式分散到增删改查的操作中,例如rehash过程中的新增会直接hash到table1,避免重复计算
跳表(skiplist)
跳表的本质就是一个多层索引结构的链表,可以参考下面一张图片
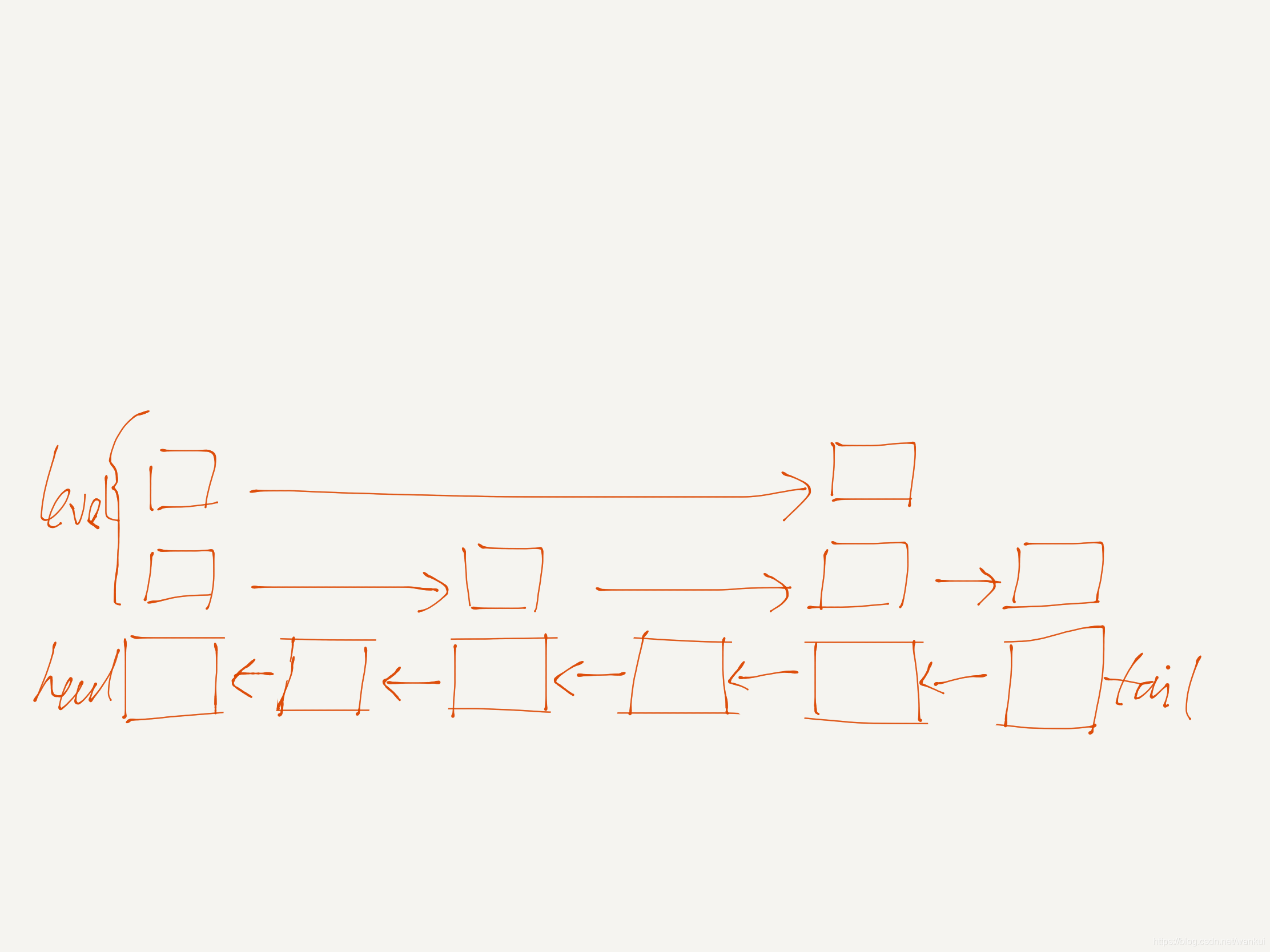
跳表的存储结构:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
跳表的设计可以快速的通过header,tail找到表头节点和表尾节点,同时通过空间换时间存储了链表长度。我们主要看一下跳表节点
层:每次插入节点数据时,随机初始化节点的层数
Randomization
- Allows for some imbalance (like the +1 -1 in AVL trees)
- Expected behavior (over the random choices) remains the same as with perfect skip lists.
- Idea: Each node is promoted to the next higher level with probability 1/2
Expect 1/2 the nodes at level 1
Expect 1/4 the nodes at level 2 ...
- Therefore, expect # of nodes at each level is the same as with perfect skip lists.
- Also: expect the promoted nodes will be well distributed across the list
分数:跳表的节点是按照score进行排序的
前进指针:因为是挂接在level上,所以前进指针是可以跳跃查找的
后退指针:只能从tail向header一步一步查找


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









