




 本文探讨了AIAgent的不同架构,如React的环境反馈机制、ChainofThought的推理过程和TreeofThought的树状结构,以及Reflexion如何增强强化学习。还介绍了Self-Ask和Plan-and-executeagents的特点及局限性。
本文探讨了AIAgent的不同架构,如React的环境反馈机制、ChainofThought的推理过程和TreeofThought的树状结构,以及Reflexion如何增强强化学习。还介绍了Self-Ask和Plan-and-executeagents的特点及局限性。
目录
如何理解一个 agent?
目前与AI的交互形式基本上都是你输入指令,AI模型会根据你的指令内容做出响应,这样就是导致你每次在进行提供有效的提示词才能达到你想要的效果。
而AI Agent则不同,它被设计为具有独立思考和行动能力的AI程序。你只需要提供一个目标,比如写一个游戏、开发一个网页,他就会根据环境的反应和独白的形式生成一个任务序列开始工作。就好像是人工智能可以自我提示反馈,不断发展和适应,以尽可能最好的方式来实现你给出的目标。
Agent架构
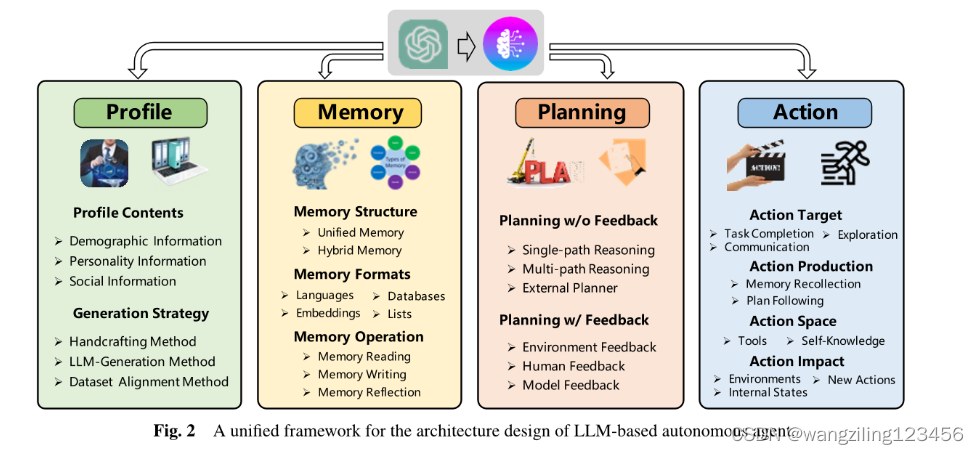
配置模块
内存模块
规划模块
1.无反馈规划
1)单路径规划 2) 多路径规划
Chain Of Thought Tree Of Thought
2.有反馈规划
1)环境反馈
来自客观世界或虚拟环境。例如,它可能是游戏的任务完成信号或代理采取行动后的观察结果
React
2) 人类反馈
除了从环境中获取反馈外,与人直接互动也是增强代理规划能力的一种直观策略
3) 模型反馈
来自代理自身的内部反馈的利用
提出了一种自我改进机制。该机制由三个关键组件组成:输出、反馈和改进。首先,代理人生成一个输出。然后,它使用 LLM 对输出进行反馈,并提供如何改进输出的指导。最后,输出通过反馈和改进得到改善。这个输出-反馈-改进过程会迭代直到达到某些期望条件。
动作模块
什么是React?
环境反馈
ReAct 实际上是一种通过多次调用 LLM 以交错的方式生成推理轨迹和特定于任务的动作,从而实现两者之间更大的协同作用
推理轨迹帮助模型归纳、跟踪和更新行动计划以及处理异常,而操作允许它与外部源(例如知识库或外部环境、API)交互,以收集附加信息。
由此上面的定义可知,ReAct需要迭代的使用 3 类元素:
Thought (思考)。LLM基于用户提出的问题进行推理(Reasoning),并根据推理的结果采取某种行为,类似人类大脑的思考、决策过程。
Action (行为)。LLM将决策行为动作的指令发送给外部源(比如调用知识库、外部的API),这就是行为。在上面的例子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









