



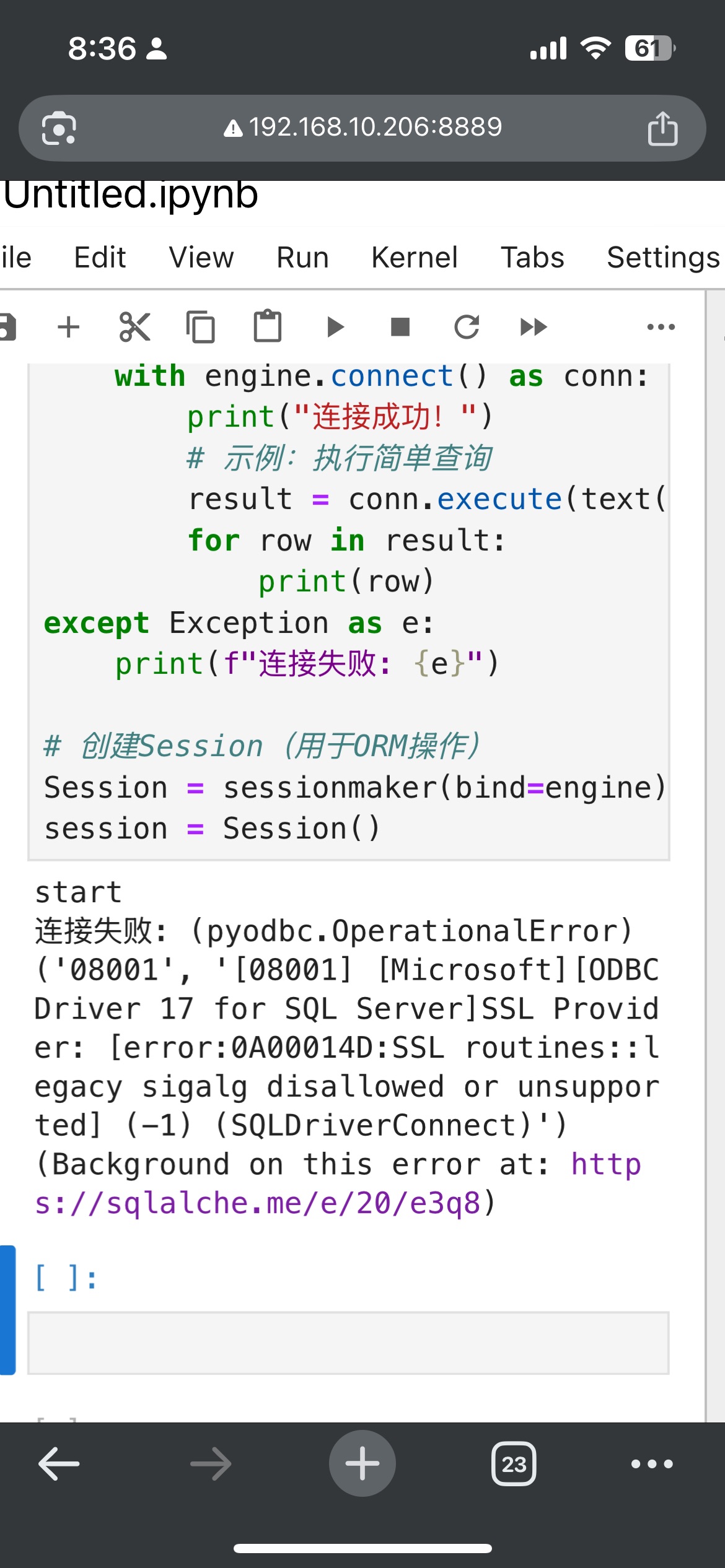
连接失败: (pyodbc.OperationalError) ('08001', '[08001] [Microsoft][ODBC Driver 17 for SQL Server]SSL Provider: [error:0A00014D:SSL routines::legacy sigalg disallowed or unsupported] (-1) (SQLDriverConnect)')
(Background on this error at: https://sqlalche.me/e/20/e3q8)
driver = 'ODBC Driver 17 for SQL Server' # 根据实际驱动版本调整
# 创建连接字符串
connection_string =f"mssql+pyodbc://{username}:{password}@{server}/{database}?Encrypt=no&TrustServerCertificate=no&driver={driver}"
Hi微软,实例没有加密就不让连了吗

















 2339
2339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









