




各位读者大家好,经过前面六篇章节的分析梳理相信各位应该掌握了常见的sql脚本的书写。但是如果想要把脚本写的“健壮”,掌握前面的知识还是不够的。在遇到大数据量的业务场景的时候,如果相关的脚本没设计好,sql执行起来就会发觉“特别累”。
这章节开篇 索引。
读者可以把索引理解为优化过顺序的指针和索引列的组合。通过他们可以快速定位到需要的数据。
我们先通过sql脚本新增张大表:
begin
for i in 1.. 15000000 loop
insert into mytable1 values ('李'|| i, trunc(dbms_random.value(100, 1+ 1)));
if mod(i,5000) = 0 then
commit;
end if;
end loop;
commit;
end;
上述脚本片段前章节有讲解过,脚本中使用了oracle的函数trunc(dbms_random.value(100, 1+ 1))可随机生成1到100的整数。使用该脚本往表里新增一千五百万条数据。表中没加任何索引,我们看看等值查找和范围查找sql的执行速度如何。
select rowid, m.* from mytable1 m where name = '李1698155' ;
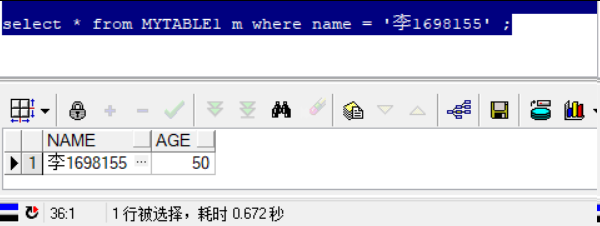
执行时间在0.5秒左右。各位是不是觉得这个执行效率还行。这其中原因之一是我这个测试表只有2个字段,一个字符串类型,一个数值类型。虽然表记录条数有一千五百万。但是整体来说表还是相对较小的。如果是个一般的业务表,有十个以上的字段,那么执行时间至少会达到大几秒以上。
select * from mytable1 m where m.name in( '李1331690', '李7888888', '李3555555', '李13690');
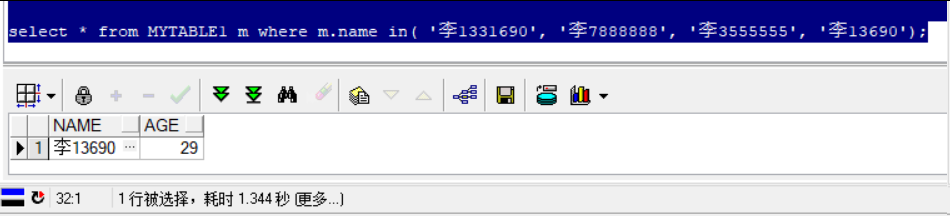
耗时时间在1.3秒之多。如果一个系统里面每条sql的平均执行时间都超过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











