 布隆过滤器原理与应用
布隆过滤器原理与应用





 布隆过滤器是一种概率型数据结构,用于高效检索集合中元素的存在性,特别适用于大数据场景下的快速判断和防止缓存穿透。其优点在于极高的空间效率和查询速度,但存在一定的误识别率。
布隆过滤器是一种概率型数据结构,用于高效检索集合中元素的存在性,特别适用于大数据场景下的快速判断和防止缓存穿透。其优点在于极高的空间效率和查询速度,但存在一定的误识别率。
简介
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),它实际上是一个很长的二进制向量和一系列随机映射函数。
布隆过滤器可以用于检索一个元素是否在一个集合中,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,逻辑是当布隆过滤器说某个值存在时,这个值 可能不存在;当它说不存在时,那么 一定不存在。
优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
适用场景
1.大数据判断是否存在
HashMap可以判断某个元素是否存,可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。这时候我们就需要考虑布隆过滤器了。
2.解决缓存穿透
什么是缓存穿透就不在这里解释了,在我之前的博客已经讲解过了。https://blog.youkuaiyun.com/wangyunzhao007/article/details/106478806
当有大量的请求访问我们不存在的数据中,缓存失效,会直接访问到数据库,当数据库扛不住压力时,数据库崩溃,这既是缓存穿透。而布隆过滤器可以判断访问的数据是否存在,当存在是才可以访问,不存在直接返回,避免了缓存穿透的发生。
数据结构和原理
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
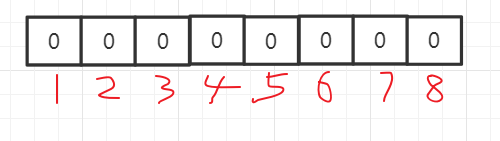
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1
例如针对值 “hello” 和三个不同的哈希函数分别生成了哈希值 1、3、5,这把1,3,5对应的位改为1,则上图转变为:

再存一个值 “world”,如果哈希函数返回 3、4、8 ,我们把3,4,8对应的位改为1

接下来我们判断hello,world,haha,三个是否存在。根据上图的二进制向量图可以判断,三个哈希值对应的位都是1,则认为值存在,有一个零或者多个,则认为值不存在。
布隆过滤器认为当哈希值1,3,5对应的都是1,则认为world存在。
布隆过滤器认为当哈希值 3、4、8对应的都是1,则认为hello存在。
如果我们haha映射的值为3,4,5,布隆过滤器也认为haha存在,但其实是不存在,所以布隆过滤器会误判。
所以布隆过滤器说某个值存在时,这个值 可能不存在;当它说不存在时,那么 一定不存在。
缺点
- 随着数据的增加,误判率随之增加;
- 无法做到删除数据;
- 只能判断数据是否一定不存在,而无法判断数据是否一定存在。
guava实现布隆过滤器
引入pom
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>代码
private static int size = 1000000;//预计要插入多少数据
private static double fpp = 0.01;//期望的误判率
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
//插入数据
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
int count = 0;
for (int i = 1000000; i < 2000000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);
}代码简单分析:
我们定义了一个布隆过滤器,有两个重要的参数,分别是 我们预计要插入多少数据,我们所期望的误判率,误判率不能为0。
我向布隆过滤器插入了0-1000000,然后用1000000-2000000来测试误判率。
运行结果
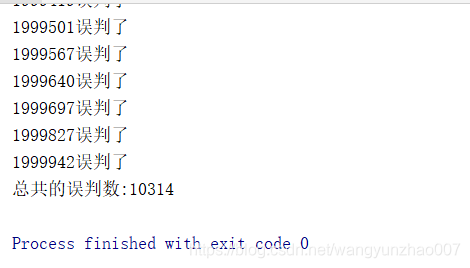
用过判断了100万数据,一共误判10314,误判率10314/1000000=0.010314
和我们定义的期望误判率0.01相差无几

















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









