




 本文提出了一种新模型,通过判断文本span之间的关系来处理不连续和重叠实体。模型包括识别entityfragment和对fragment间关系分类两个步骤,使用了AGGCN增强词向量表示。实验表明,该模型在处理不连续实体时表现优于传统方法,但在某些情况下提升有限。
本文提出了一种新模型,通过判断文本span之间的关系来处理不连续和重叠实体。模型包括识别entityfragment和对fragment间关系分类两个步骤,使用了AGGCN增强词向量表示。实验表明,该模型在处理不连续实体时表现优于传统方法,但在某些情况下提升有限。
原文链接:https://aclanthology.org/2021.acl-long.372.pdf
ACL 2021
介绍
问题
对于不连续和嵌套类的实体,目前存在的两种范式:超图和基于过渡(transition-based models)的模型,虽然能够灵活的应用于不同的任务,但是这些模型需要手动定义图的节点、边或过渡方法,并且这些模型随着句子中的词来建立图或生成过渡,可能存在误差传播的情况。
IDEA
本文通过对span之间的关系进行判断,来解决不连续实体的问题。具体地,本文提出了一个能够解决overlap和不连续实体的模型,该模型主要包括以下两步:1)遍历所有可能的文本span来识别实体fragment;2)对给出的一对实体fragment进行关系分类,来判断该fragment是重叠的还是继承的。
方法
本文所提出的整体结构如下图所示,主要有两个部分:1)列举所有可用的span,然后利用多分类策略来确定一个span是否为entity fragment以及实体的类型;2)对所有的实体fragment之间的关系进行分类,识别它们之间的关系继承、重叠还是其他(虽然第一步中的枚举已经能够得到嵌套的实体,这里还对fragment之间的关系进行嵌套的分类是为了再次识别嵌套实体)。
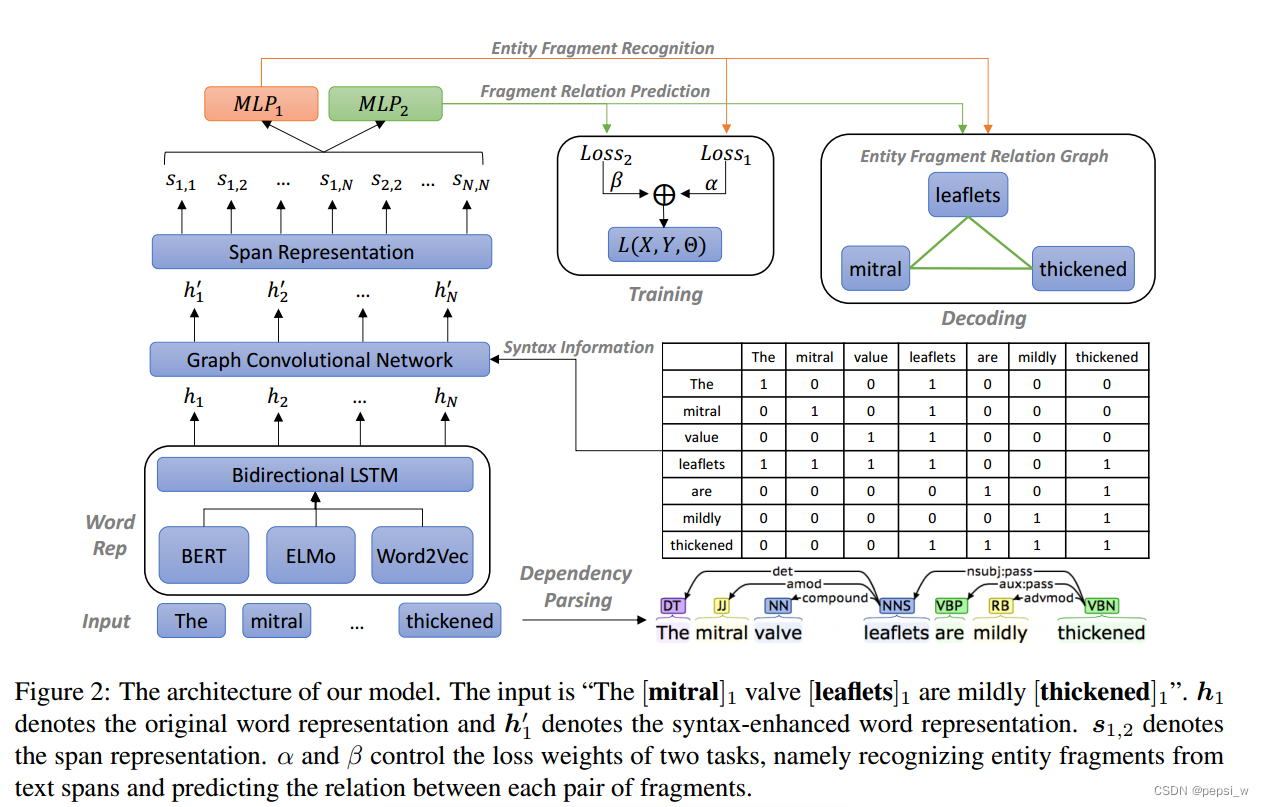
Word Representation
给定输入:,将每个单词拆分为word pieces后送入到BERT中(输出中一个word对应多个pieces),并将开始的word piece视为word表征,例如”fevers“被拆分为”fever“和”##s“,则将”fever”的表征视为整个单词的表征。因此句子x的输出对应矩阵
,
表示每个向量的维度。
Graph Convolutional Network
图卷积网络使用attention-guided GCN(AGGCN),输入,在标准的GCN中按以下方式进行更新:
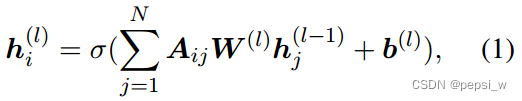
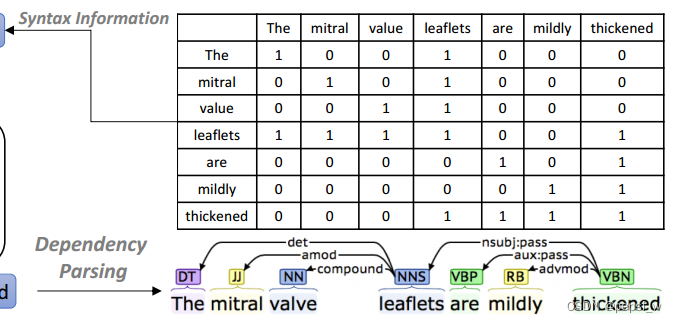
w和b都是l层的权重和偏置,表示图的邻接矩阵,由相应依赖语法树生成:
而在AGGCN中,高层中的A使用多头自注意力机制来进行更新。是第t个头的最新邻接矩阵。计算公式如下所示:
![]()
对于每个头t,AGGCN使用和一个densely连接层(输出表示为
)来更新词向量,最后使用一个线性combination层来结合每个头的输出,即AGGCN最终的输出表示为:
AGGCN的输出与原始word表征
组成最终的word表征:
Span Representation
生成span的方法依旧是通过枚举所有span,(i-j)span的表征表示为:
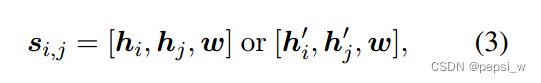
其中,w是一个20维的embedding,表示了span的跨度。
Decoding
decoding包括两步,先识别所有有效的实体fragment,然后对它们之间的关系进行分类。
这两步中都分别使用一个MLP进行简单的分类,P1表示实体类型的可能性,p2表示属于“继承”“重叠”“其他”这三类的可能性。
![]()
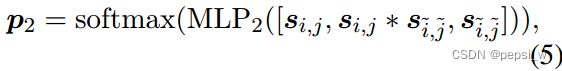
解码部分的算法如下所示(感觉这部分理解起来挺简单的,为啥要写个伪代码?而且这个伪代码也太伪了吧):

可以看出,预测的最终结果其实就是一个实体fragment关系图。解码的目标就是找到所有的子图,在这些子图中,每个节点都与其他任何节点相连,这些子图也就是一个实体。
Training
损失函数由两部分组成,实体fragment识别和fragment关系预测:和
表示text span和span pairs的golden lable。
![]()
实验
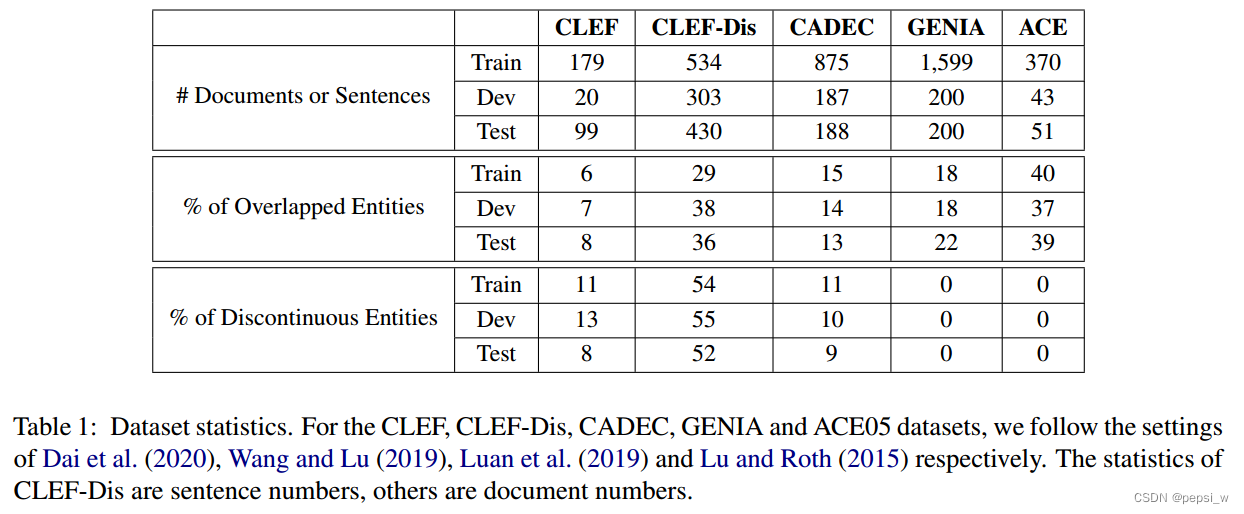
作者在多个数据集上进行了实验, 数据集的具体情况如下所示:
在overlap和disconnected数据集上的对比实验:
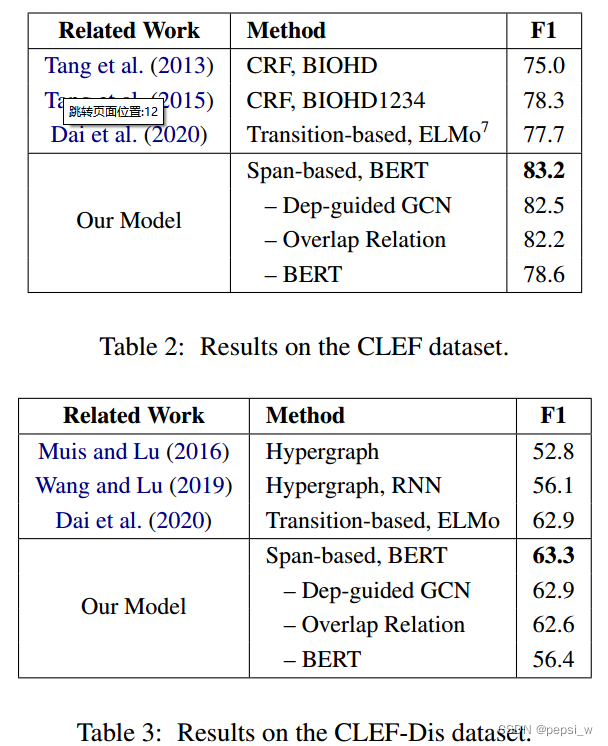
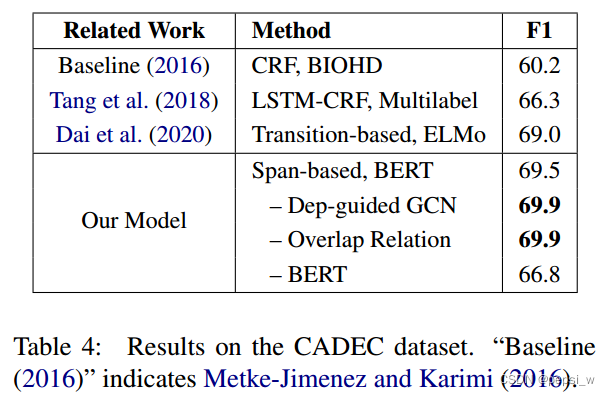
为了说明建立一个模型来同时识别规则的、重叠的和不连续的实体的必要性,作者对CLEF-Dis数据集中的实体进行分类,如下图所示(只考虑flat NER时 对两个模型的效果进行了对比 其他情况都是作者提出模型的实验结果):
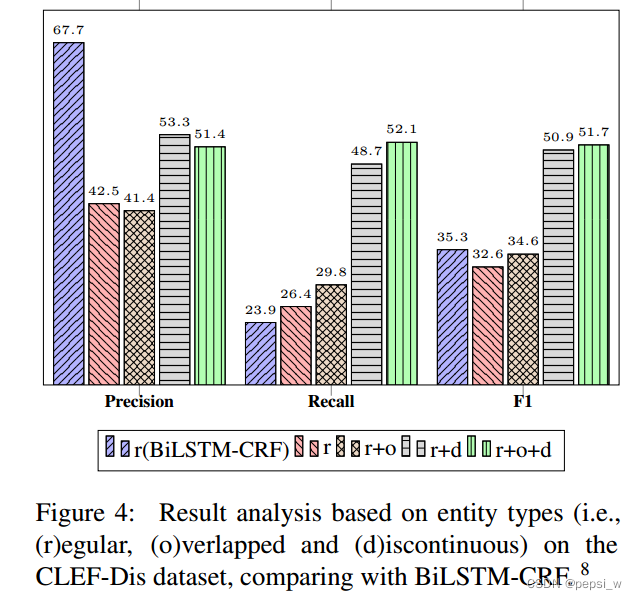
BiLSTM-CRF在辨别flat的NER时,precision值达到了最高,然后作者提出的模型有更高的recall,缩短了两个模组之间的差距。在加入重叠实体后,我们的模型效果得到了一个极大的提升;考虑三种类型的实体时,我们的模型在此基础上又增加了0.8%。(这不是废话吗?你模型就是用来解决不连续实体的,增加不连续实体,效果肯定会好啊)
与基于过度方法的模型进行了对比:
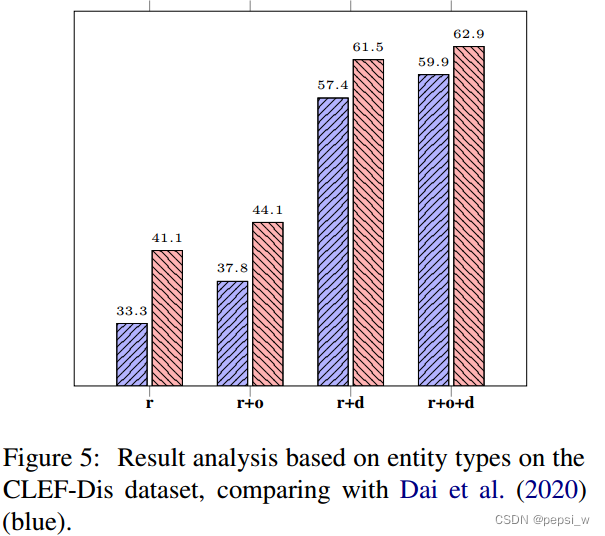
这里作者是对该模型进行了复现,而不是直接引用论文给出的结果,复现会稍差一点。而在加入不连续实体后,作者提出的模型并没有对比模型好(加入d后,作者的模型只提升了1.4 而对比模型提升了2.5)
在flat和overlap数据集上进行对比实验
作者在GENIA和ACE05两个数据集(只包括flat和重叠的实体)上进行了实验,结果如下所示:
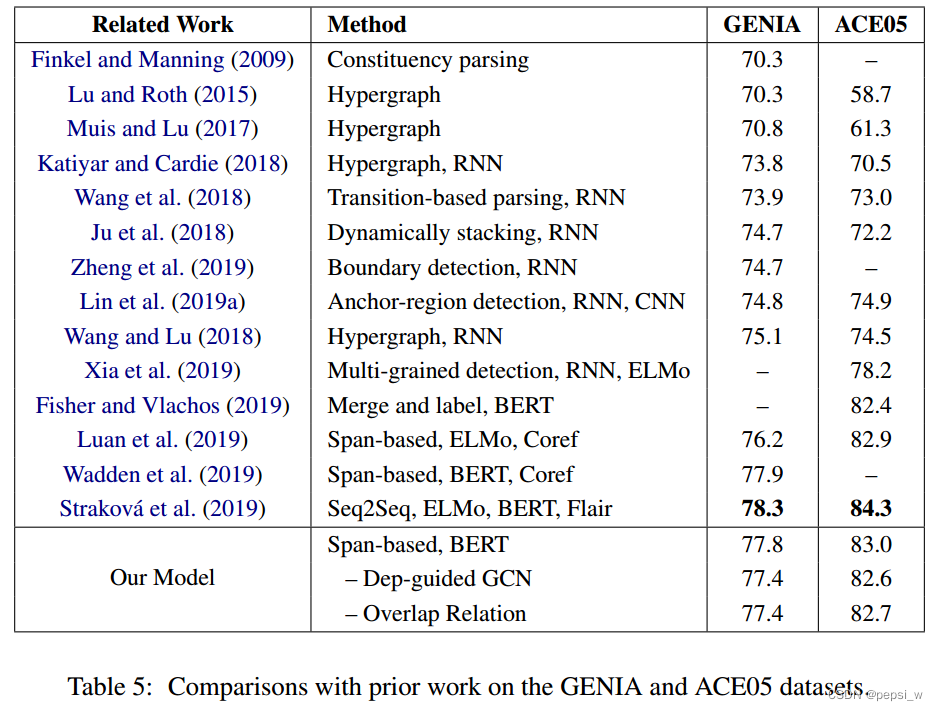
总结
整体来看,虽然作者提出了一种新的逻辑,提出了基于span的模型来解决disconnected的实体(思路倒是比较靠谱),但文中作者对使用了AGGCN来增加了word 表征进行了着重介绍(我感觉哈),对于fragment的判断反而采用最简单的方法,有点奇奇怪怪的。而且实验结果也并没有很好,将提出的AGGCN和overlap relation进行了消融实验,对模型的影响都不是很大,也就是说其实效果并没有很好?(个人见解,如有不对 还请指出)


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









