




 本文详细解析了ElasticSearch中字符串类型的text与keyword区别,文本搜索、关键词搜索的应用场景,以及如何设置不同类型的字段,如text用于全文搜索,keyword适合结构化数据。了解如何为文本、数字、日期等数据类型选择合适映射和存储策略。
本文详细解析了ElasticSearch中字符串类型的text与keyword区别,文本搜索、关键词搜索的应用场景,以及如何设置不同类型的字段,如text用于全文搜索,keyword适合结构化数据。了解如何为文本、数字、日期等数据类型选择合适映射和存储策略。
一、字段类型概述
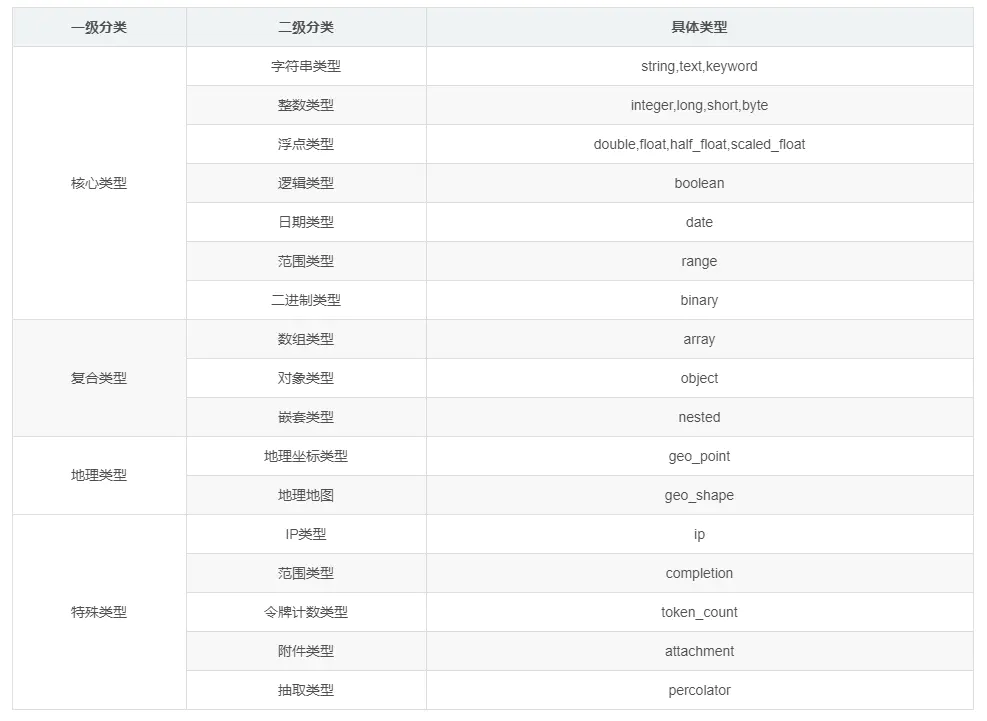
二、字符串类型ElasticSearch对字符串拥有两种完全不同的搜索方式. 你可以按照整个文本进行匹配, 即关键词搜索(keyword search), 也可以按单个字符匹配, 即全文搜索(full-text search).
text用于全文搜索的, 而keyword用于关键词搜索.
Text:
会分词,然后进行索引
支持模糊、精确查询
不支持聚合keyword:
不进行分词,直接索引
支持模糊、精确查询
支持聚合
text
当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
}
}
}
}
}
}如果不指定类型,ElasticSearch字符串将默认被同时映射成text和keyword类型,会自动创建下面的动态映射(dynamic mappings):
{
"foo": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}ignore_above忽略长度超过256字符串。
这就是造成部分字段还会自动生成一个与之对应的“.keyword”字段的原因。
一个字符串字段可以映射为text字段用于全文本搜索,也可以映射为keyword字段用于排序或聚合,这时候需要用到fields设置多字段。如果业务关系中,需要该字段支持两种类型的查询,可以设置为如下形式:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
}name.raw字段是name字段的keyword版本。
keyword
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。
{
"foo": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}整数类型
byte short integer long
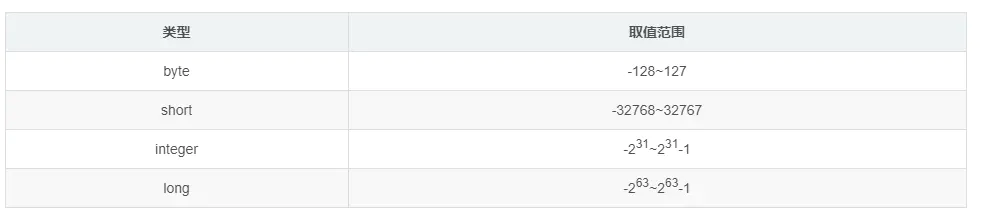
浮点类型
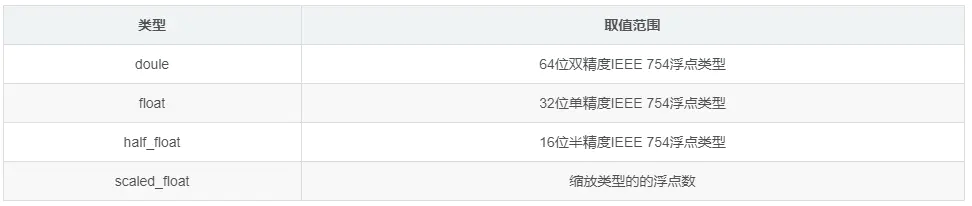
date类型
1.日期格式的字符串,比如 “2018-01-13” 或 “2018-01-13 12:10:30” 2.long类型的毫秒数( milliseconds-since-the-epoch,epoch就是指UNIX诞生的UTC时间1970年1月1日0时0分0秒) 3.integer的秒数(seconds-since-the-epoch)
ElasticSearch 内部会将日期数据转换为UTC,并存储为milliseconds-since-the-epoch的long型整数。
"properties": {
"postdate":{
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
boolean类型
逻辑类型(布尔类型)可以接受true/false/”true”/”false”值
"properties": { "empty":{ "type":"boolean" } }
binary类型
二进制字段是指用base64来表示索引中存储的二进制数据,可用来存储二进制形式的数据,例如图像。默认情况下,该类型的字段只存储不索引。二进制类型只支持index_name属性。
array类型
在ElasticSearch中,没有专门的数组(Array)数据类型,但是,在默认情况下,任意一个字段都可以包含0或多个值,这意味着每个字段默认都是数组类型,只不过,数组类型的各个元素值的数据类型必须相同。在ElasticSearch中,数组是开箱即用的(out of box),不需要进行任何配置,就可以直接使用。
在同一个数组中,数组元素的数据类型是相同的,ElasticSearch不支持元素为多个数据类型:[ 10, “some string” ],常用的数组类型是:
字符数组: [ “one”, “two” ]
整数数组: productid:[ 1, 2 ]
对象(文档)数组:
“user”:[ { “name”: “Mary”, “age”: 12 }, { “name”: “John”, “age”: 10 }],
ElasticSearch内部把对象数组展开为
{“user.name”: [“Mary”, “John”], “user.age”: [12,10]}ip类型
PUT my-index
{
"mappings": {
"properties": {
"ip_addr": {
"type": "ip"
}
}
}
}
PUT my-index/_doc/1
{
"ip_addr": "192.168.1.1"
}IPv4 的 IP 地址含有4个 bytes,而每个 byte 含有8个 digits。/16 即表示前面的 16 位的 digits,也即 192.168。我们可以这么说任何一个 IP 地址位于 192.168.0.0 至 192.168.255.255 都在这个范围内。
GET my-index/_search
{
"query": {
"term": {
"ip_addr": "192.168.0.0/16"
}
}
}
store 属性
store 默认是 no,是否在 _source 之外在独立存储一份。 _source 这是源文档,当你索引数据的时候, elasticsearch 会保存一份源文档到 _source。如果文档的某一字段设置了 store 为 yes (默认为 no),这时候会在 _source 存储之外再为这个字段独立进行存储。
目的主要是针对内容比较多的字段,放到 _source 返回的话,因为_source 是把所有字段保存为一份文档,命中后读取只需要一次 IO,包含内容特别多的字段会很占带宽影响性能。
通常我们也不需要完整的内容返回(可能只关心摘要),这时候就没必要放到 _source 里一起返回了(当然也可以在查询时指定返回字段)。
对内容太长的字段,将 store 设置为 yes ,一般来说还应该在 _source 排除 exclude 掉这个字段,这时候索引的字段,不会保存在 _source 里了,会独立存储一份。查询时 _source 里也没有这个字段了,但是还是可以通过指定返回字段来获取,但是会有额外的 IO 开销,因为 _source 的读取只有一次 IO ,而已经 exclude 并设置 store 的字段,是独立存储的需要一个新的 IO 。
值得注意的是,虽然这个字段没有存储在 _source 了,但是这个字段还是可以 match 和高亮的。当然如果 _source 不存储,并且 store 也为 no 这时候,数据就不会返回了,也不能高亮了。但是还是可以 match 的,前提是这个字段映射时 index 属性设置了 analyzed ,lucence 对这个字段建立了倒排索引。如果 index 设置为 no 这时候等于就是没有映射这个字段了,既不能查询,也不能得到返回。设置为 not_analyzed 不会建立倒排索引,但是可以被查询到。
查看如下网址继续学习
https://www.cnblogs.com/haixiang/p/12040272.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









