




文章大纲
Lagent 自定义你的 Agent 智能体
Lagent 介绍
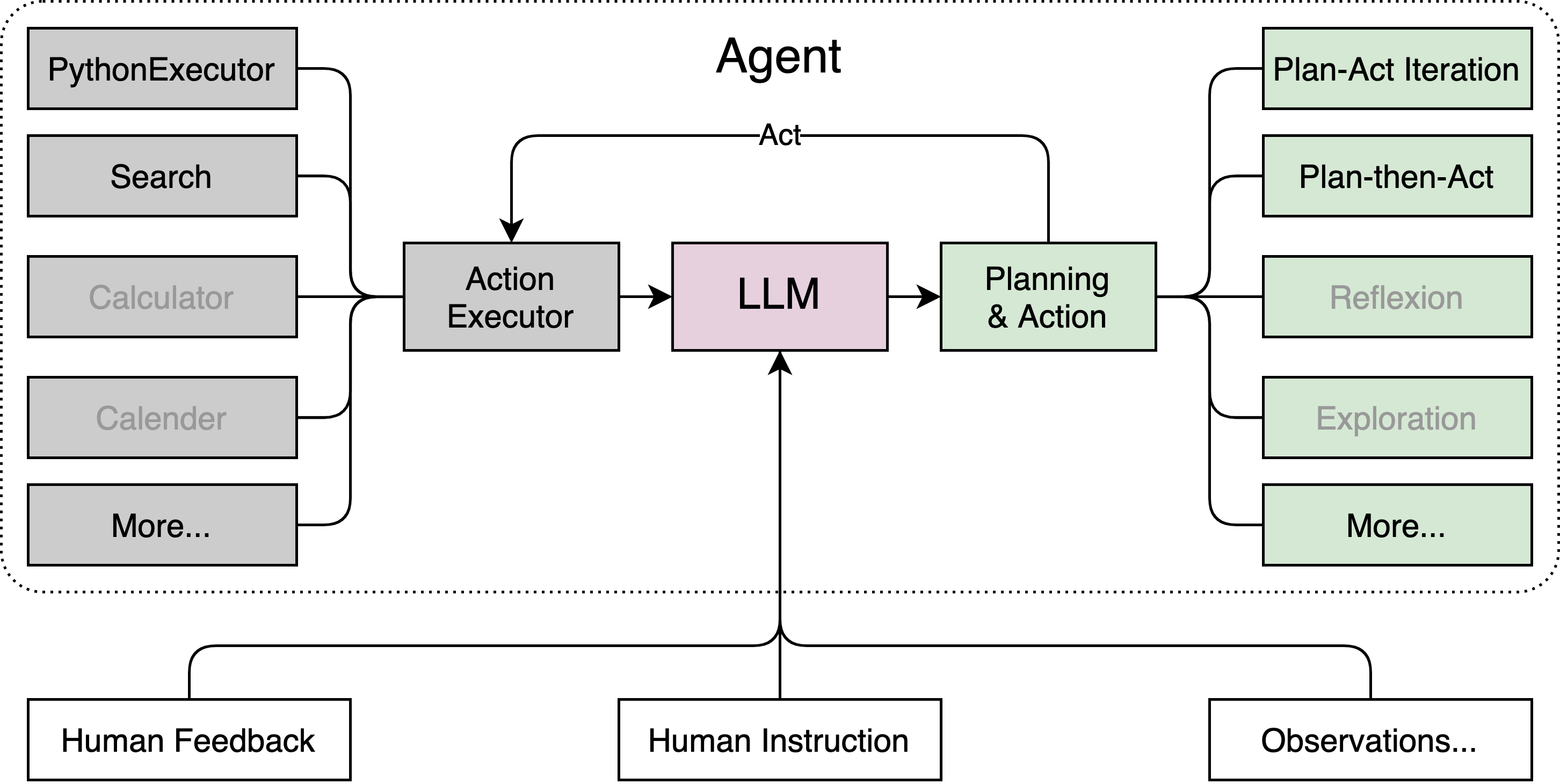
Lagent 是一个轻量级开源智能体框架,旨在让用户可以高效地构建基于大语言模型的智能体。同时它也提供了一些典型工具以增强大语言模型的能力。
Lagent 目前已经支持了包括 AutoGPT、ReAct 等在内的多个经典智能体范式,也支持了如下工具:
- Arxiv 搜索
- Bing 地图
- Google 学术搜索
- Google 搜索
- 交互式 IPython 解释器
- IPython 解释器
- PPT
- Python 解释器
其基本结构如下所示:
环境配置
开发机选择 30% A100,镜像选择为 Cuda12.2-conda。
首先来为 Lagent 配置一个可用的环境。
# 创建环境
conda create -n agent_camp3 python=3.10 -y
# 激活环境
conda activate agent_camp3
# 安装 torch
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖包
pip install termcolor==2.4.0
pip install lmdeploy==0.5.2
接下来,我们通过源码安装的方式安装 lagent。
# 创建目录以存放代码
mkdir -p /root/agent_camp3
cd /root/agent_camp3
git clone https://github.com/InternLM/lagent.git
cd lagent && git checkout 81e7ace && pip install -e . && cd ..
Lagent Web Demo 使用
接下来,我们将使用 Lagent 的 Web Demo 来体验 InternLM2.5-7B-Chat 的智能体能力。
首先,我们先使用 LMDeploy 部署 InternLM2.5-7B-Chat,并启动一个 API Server。
conda activate agent_camp3
lmdeploy serve api_server /share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat --model-name internlm2_5-7b-chat
然后,我们在另一个窗口中启动 Lagent 的 Web Demo。
cd /root/agent_camp3/lagent
conda activate agent_camp3
streamlit run examples/internlm2_agent_web_demo.py
在等待两个 server 都完全启动(如下图所示)后,我们在 本地 的 PowerShell 中输入如下指令来进行端口映射:
ssh -CNg -L 8501:127.0.0.1:8501 -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p <你的 SSH 端口号>
| LMDeploy api_server | Lagent Web Demo |
|---|---|
 |  |
接下来,在本地浏览器中打开 localhost:8501,并修改模型名称一栏为 internlm2_5-7b-chat,修改模型 ip一栏为127.0.0.1:23333。
[!IMPORTANT]
输入后需要按下回车以确认!
然后,我们在插件选择一栏选择 ArxivSearch,并输入指令“帮我搜索一下 MindSearch 论文”。
最后,可以看到,模型已经回复了相关信息。

模型要选择正确

基于 Lagent 自定义智能体
在本节中,我们将带大家基于 Lagent 自定义自己的智能体。
Lagent 中关于工具部分的介绍文档位于 https://lagent.readthedocs.io/zh-cn/latest/tutorials/action.html 。
使用 Lagent 自定义工具主要分为以下几步:
- 继承
BaseAction类 - 实现简单工具的
run方法;或者实现工具包内每个子工具的功能 - 简单工具的
run方法可选被tool_api装饰;工具包内每个子工具的功能都需要被tool_api装饰
下面我们将实现一个调用 MagicMaker API 以完成文生图的功能。
首先,我们先来创建工具文件:
cd /root/agent_camp3/lagent
touch lagent/actions/magicmaker.py
然后,我们将下面的代码复制进入 /root/agent_camp3/lagent/lagent/actions/magicmaker.py
import json
import requests
from lagent.actions.base_action import BaseAction, tool_api
from lagent.actions.parser import BaseParser, JsonParser
from lagent.schema import ActionReturn, ActionStatusCode
class MagicMaker(BaseAction):
styles_option = [
'dongman', # 动漫
'guofeng', # 国风
'xieshi', # 写实
'youhua', # 油画
'manghe', # 盲盒
]
aspect_ratio_options = [
'16:9', '4:3', '3:2', '1:1',
'2:3', '3:4', '9:16'
]
def __init__(self,
style='guofeng',
aspect_ratio='4:3'):
super().__init__()
if style in self.styles_option:
self.style = style
else:
raise ValueError(f'The style must be one of {self.styles_option}')
if aspect_ratio in self.aspect_ratio_options:
self.aspect_ratio = aspect_ratio
else:
raise ValueError(f'The aspect ratio must be one of {aspect_ratio}')
@tool_api
def generate_image(self, keywords: str) -> dict:
"""Run magicmaker and get the generated image according to the keywords.
Args:
keywords (:class:`str`): the keywords to generate image
Returns:
:class:`dict`: the generated image
* image (str): path to the generated image
"""
try:
response = requests.post(
url='https://magicmaker.openxlab.org.cn/gw/edit-anything/api/v1/bff/sd/generate',
data=json.dumps({
"official": True,
"prompt": keywords,
"style": self.style,
"poseT": False,
"aspectRatio": self.aspect_ratio
}),
headers={'content-type': 'application/json'}
)
except Exception as exc:
return ActionReturn(
errmsg=f'MagicMaker exception: {exc}',
state=ActionStatusCode.HTTP_ERROR)
image_url = response.json()['data']['imgUrl']
return {'image': image_url}
最后,我们修改 /root/agent_camp3/lagent/examples/internlm2_agent_web_demo.py 来适配我们的自定义工具。
- 在
from lagent.actions import ActionExecutor, ArxivSearch, IPythonInterpreter的下一行添加from lagent.actions.magicmaker import MagicMaker - 在第27行添加
MagicMaker()。
from lagent.actions import ActionExecutor, ArxivSearch, IPythonInterpreter
+ from lagent.actions.magicmaker import MagicMaker
from lagent.agents.internlm2_agent import INTERPRETER_CN, META_CN, PLUGIN_CN, Internlm2Agent, Internlm2Protocol
...
action_list = [
ArxivSearch(),
+ MagicMaker(),
]
接下来,启动 Web Demo 来体验一下吧!我们同时启用两个工具,然后输入“请帮我生成一幅山水画”
然后,我们再试一下“帮我搜索一下 MindSearch 论文”。
任务
-
https://github.com/InternLM/Tutorial/blob/camp3/docs/L2/Lagent/task.md
-
使用 Lagent 自定义一个智能体,并使用 Lagent Web Demo 成功部署与调用,记录复现过程并截图。




把这个风景画变成国画风格

以下是输出结果,感觉模型不太会转化


{
"name": "MagicMaker.generate_image",
"parameters": {
"keywords": "秦岭 小写意 山水画"
}
}

其他学习内容
参考文献
大模型实战营 地址
- https://openxlab.org.cn/models/InternLM/subject
本人学习系列笔记
第二期
- 《书生·浦语大模型实战营》第1课 学习笔记:书生·浦语大模型全链路开源体系
- 《书生·浦语大模型实战营》第2课 学习笔记:轻松玩转书生·浦语大模型趣味 Demo
- 《书生·浦语大模型实战营》第3课 学习笔记:搭建你的 RAG 智能助理(茴香豆)
- 《书生·浦语大模型实战营》第4课 学习笔记:XTuner 微调 LLM:1.8B、多模态、Agent
- 《书生·浦语大模型实战营》第5课 学习笔记:LMDeploy 量化部署 LLM 实践
- 《书生·浦语大模型实战营》第6课 学习笔记:Lagent & AgentLego 智能体应用搭建
- 《书生·浦语大模型实战营》第7课 学习笔记:OpenCompass 大模型评测实战
第三期
入门岛
- 《书生大模型实战营第3期》入门岛 学习笔记与作业:Linux 基础知识
- 《书生大模型实战营第3期》入门岛 学习笔记与作业:Git 基础知识
- 《书生大模型实战营第3期》入门岛 学习笔记与作业:Python 基础知识
基础岛
- 《书生大模型实战营第3期》基础岛 第1关 :书生大模型全链路开源体系
- 《书生大模型实战营第3期》基础岛 第2关 :8G 显存玩转书生大模型 Demo
- 《书生大模型实战营第3期》基础岛 第3关 :浦语提示词工程实践
- 《书生大模型实战营第3期》基础岛 第4关 :InternLM + LlamaIndex RAG 实践
- 《书生大模型实战营第3期》基础岛 第5关 :XTuner 微调个人小助手认知
- 《书生大模型实战营第3期》基础岛 第6关 :OpenCompass 评测 InternLM-1.8B 实践
课程资源
第三期 学院闯关手册
- https://aicarrier.feishu.cn/wiki/XBO6wpQcSibO1okrChhcBkQjnsf
第三期 作业提交
- https://aicarrier.feishu.cn/share/base/form/shrcnZ4bQ4YmhEtMtnKxZUcf1vd
第二期 学员手册
- https://aicarrier.feishu.cn/wiki/KamPwGy0SiArQbklScZcSpVNnTb
算力平台
- https://studio.intern-ai.org.cn/console/dashboard
- https://studio.intern-ai.org.cn/
课程文档
- https://github.com/InternLM/Tutorial/tree/camp3
- https://github.com/InternLM/Tutorial/tree/camp2
课程视频
- https://www.bilibili.com/video/BV15m421j78d
代码仓库
- https://github.com/InternLM/Tutorial
- https://github.com/InternLM/Tutorial/tree/camp2
优秀项目展示与学习
- https://aicarrier.feishu.cn/wiki/DoKWwqslwiyjjKkHhqJcvXAZnwd?table=tblyxy5MZV7gJ7yS&view=vew0rj0WuN
论文
其他参考
原始视频
- https://www.bilibili.com/video/BV18142187g5/?vd_source=d7bc15cac5976d766ca368e2f081b28b
原始文档
https://github.com/InternLM/Tutorial/blob/camp3/docs/L0/Linux/readme.md
本人博客:


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











