




 本文深入探讨了链表(包括单向链表、双向链表和循环链表)与数组的存储结构和优缺点。数组在查询上速度快,但增删操作慢且长度固定;链表则提供灵活的内存管理,增删操作高效,但查找效率较低。思考如何结合两者优点,如Java的HashMap类,以实现更高效的存储结构。
本文深入探讨了链表(包括单向链表、双向链表和循环链表)与数组的存储结构和优缺点。数组在查询上速度快,但增删操作慢且长度固定;链表则提供灵活的内存管理,增删操作高效,但查找效率较低。思考如何结合两者优点,如Java的HashMap类,以实现更高效的存储结构。
链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域(单链表只有后指针,双向链表有前后两个指针)。
链表的分类:单向链表、双向链表及循环链表
单向链表
链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值。

双向链表
一种更复杂的链表是“双向链表”或“双面链表”。每个节点有两个连接:一个指向前一个节点,(当此“连接”为第一个“连接”时,指向空值或者空列表);而另一个指向下一个节点,(当此“连接”为最后一个“连接”时,指向空值或者空列表)

循环链表
它的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环。这种方式在单向和双向链表中皆可实现。要转换一个循环链表,你开始于任意一个节点然后沿着列表的任一方向直到返回开始的节点。再来看另一种方法,循环链表可以被视为“无头无尾”。这种列表很利于节约数据存储缓存, 假定你在一个列表中有一个对象并且希望所有其他对象迭代在一个非特殊的排列下。

数组
所谓数组,是有序的元素序列。 若将有限个类型相同的变量的集合命名,那么这个名称为数组名。组成数组的各个变量称为数组的分量,也称为数组的元素,有时也称为下标变量。用于区分数组的各个元素的数字编号称为下标。数组是在程序设计中,为了处理方便, 把具有相同类型的若干元素按有序的形式组织起来的一种形式。 这些有序排列的同类数据元素的集合称为数组。
链表与数组的存储结构
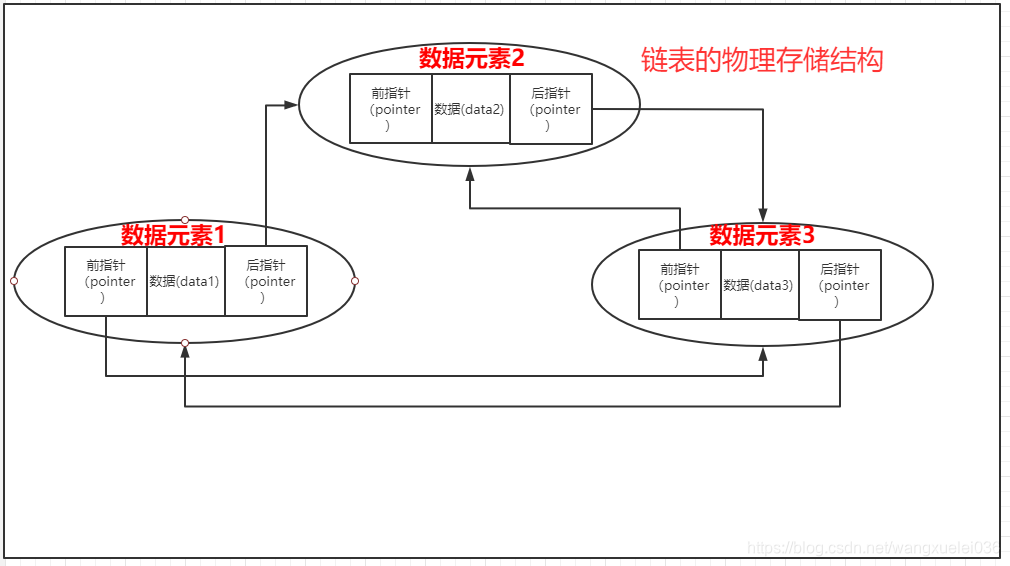
存储结构为链式的存储结构,物理存储结构上是离散型
其中存储数据元素信息的域称作数据域(设域名为data),存储直接前后继存储位置的域称为指针域(设pointer)。指针域中存储的信息又称做指针或链。
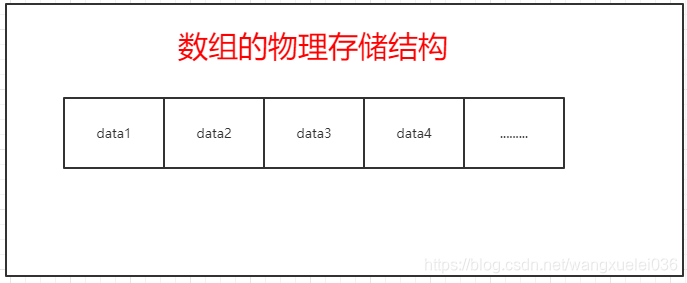
数组是连续的存储结构
因为数组的空间大小开始都已经确定,所以在物理存储分配的时候,可以分配一块连续的存储地址
链表与数组的优缺点比较
技术的优缺点都和设计原理直接相关,我们刚刚看到了数组和链表的实现原理,我们其实大概已经知道了大部分了,但这里我们还是统一集中归纳下:
数组
优点:
因为它在空间上是连续分布的,因此,查询快(注:物理存储上连续,可以根据指针偏移量(每个元素大小*元素坐标) 来取得相应的存储地址),查询时间为O(1)
缺点:
也正是因为空间上连续,在进行增删元素的操作慢,不友善(注:因为增加或删除中间某个元素,会涉及到后面元素的移动)
数组长度固定,不灵活(如果要扩容需要重新分配一整块更大的空间,并将原来的数据copy过去,java 中的ArrayList扩容即如此)
链表
优点:
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
由于不必须按顺序存储,链表在插入或删除元素节点的时候可以达到O(1)的复杂度(注:只需要修改前后指针指向,不用移动其他元素),比另一种线性表顺序表快得多,
缺点:
相比于数组顺序存储结构,首先,操作复杂。
但是由于空间分布上是离散型,无法通过指针偏移量来直接获取元素地址,因此,查找一个节点或者访问特定编号的节点则需要O(n)的时间,失去了数组随机读取的优点(必须从头节点一个个查询)
同时链表由于增加了结点的指针域,空间开销比较大。
思考:
既然数组和链表各有所长,那如何使用他们设计出更加性能优异的存储结构呢?因此,就出现了比如 java中的HashMap类等这些结构体。

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









