




 本文通过实例讲解如何手写数据结构,如停车系统、浏览器历史、哈希集合和电话簿管理系统,提升编程基础。涉及栈与队列、哈希表、动态规划应用,适合提升算法理解与实现能力。
本文通过实例讲解如何手写数据结构,如停车系统、浏览器历史、哈希集合和电话簿管理系统,提升编程基础。涉及栈与队列、哈希表、动态规划应用,适合提升算法理解与实现能力。
编程总结
在刷题之前需要反复练习的编程技巧,尤其是手写各类数据结构实现,它们好比就是全真教的上乘武功
手写完成后,我们针对性的进行练习,练习题如下:

1. 入门
1603. 设计停车系统
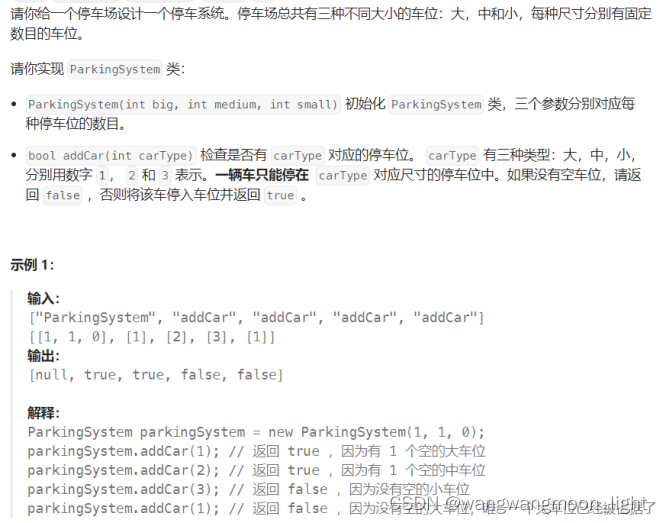
typedef struct {
int bigCar;
int mediumCar;
int smallCar;
} ParkingSystem;
// 1.建立停车系统
ParkingSystem *parkingSystemCreate(int bigCar, int mediumCar, int smallCar)
{
ParkingSystem *sys = (ParkingSystem *)malloc(sizeof(ParkingSystem));
sys->bigCar = bigCar;
sys->mediumCar = mediumCar;
sys->smallCar = smallCar;
return sys;
}
// 2.增加汽车停车
bool parkingSystemAddCar(ParkingSystem *obj, int carType)
{
if (carType == 1) {
if (obj->bigCar > 0) {
obj->bigCar--;
} else {
return false;
}
} else if (carType == 2) {
if (obj->mediumCar > 0) {
obj->mediumCar--;
} else {
return false;
}
} else if (carType == 3) {
if (obj->smallCar > 0) {
obj->smallCar--;
} else {
return false;
}
} else {
return false;
}
return true;
}
// 3.释放汽车停车系统
void parkingSystemFree(ParkingSystem *obj)
{
free(obj);
}
2. 栈与队列
1427. 设计浏览器历史记录
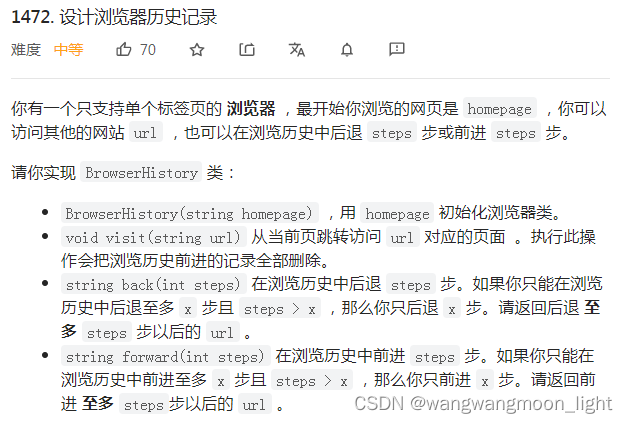
typedef struct {
int top;
int cur;
char url[5001][21];
} BrowserHistory;
BrowserHistory *browserHistoryCreate(char *homepage)
{
BrowserHistory *obj = (BrowserHistory *)malloc(sizeof(BrowserHistory));
obj->top = -1;
obj->top++;
obj->cur = obj->top;
strcpy(obj->url[obj->cur], homepage);
return obj;
}
void browserHistoryVisit(BrowserHistory *obj, char *url)
{
obj->cur++;
strcpy(obj->url[obj->cur], url);
obj->top = obj->cur; // 将浏览历史前进的记录删除,更新了Top
}
char *browserHistoryBack(BrowserHistory *obj, int steps)
{
if (steps > obj->cur) {
steps = obj->cur;
}
obj->cur = obj->cur - steps;
return obj->url[obj->cur];
}
char *browserHistoryForward(BrowserHistory *obj, int steps)
{
if ((obj->top - obj->cur) < steps) {
steps = obj->top - obj->cur;
}
obj->cur = obj->cur + steps;
return obj->url[obj->cur];
}
void browserHistoryFree(BrowserHistory *obj)
{
free(obj);
}
1756. 设计最近使用(MRU)队列
设计一种类似队列的数据结构,该数据结构将最近使用的元素移到队列尾部。
实现 MRUQueue 类:
MRUQueue(int n) 使用 n 个元素: [1,2,3,…,n] 构造 MRUQueue 。
fetch(int k) 将第 k 个元素(从 1 开始索引)移到队尾,并返回该元素。
示例 1:
输入:
[“MRUQueue”, “fetch”, “fetch”, “fetch”, “fetch”]
[[8], [3], [5], [2], [8]]
输出:
[null, 3, 6, 2, 2]
解释:
MRUQueue mRUQueue = new MRUQueue(8); // 初始化队列为 [1,2,3,4,5,6,7,8]。
mRUQueue.fetch(3); // 将第 3 个元素 (3) 移到队尾,使队列变为 [1,2,4,5,6,7,8,3] 并返回该元素。
mRUQueue.fetch(5); // 将第 5 个元素 (6) 移到队尾,使队列变为 [1,2,4,5,7,8,3,6] 并返回该元素。
mRUQueue.fetch(2); // 将第 2 个元素 (2) 移到队尾,使队列变为 [1,4,5,7,8,3,6,2] 并返回该元素。
mRUQueue.fetch(8); // 第 8 个元素 (2) 已经在队列尾部了,所以直接返回该元素即可。
思路:将第K个元素移到队尾
- [k, obj->size] 前移一个位置
- 将第k个元素放置在末尾
typedef struct {
int queue[20001];
int size;
} MRUQueue;
MRUQueue* mRUQueueCreate(int n)
{
MRUQueue* obj = (MRUQueue*)malloc(sizeof(MRUQueue));
memset(obj, 0, sizeof(MRUQueue));
obj->size = n;
for (int i = 1; i <= n; ++i) {
obj->queue[i] = i;
}
return obj;
}
// 将第 k 个元素(从 1 开始索引)移到队尾,并返回该元素
int mRUQueueFetch(MRUQueue* obj, int k)
{
int tmp = obj->queue[k];
// [k, obj->size] 前移一个位置
for (int i = k + 1; i <= obj->size; ++i) {
obj->queue[i - 1] = obj->queue[i];
}
// 将第k个元素放置在末尾
obj->queue[obj->size] = tmp;
return tmp;
}
void mRUQueueFree(MRUQueue* obj)
{
free(obj);
}
3. 哈希
705. 设计哈希集合

typedef struct {
int hash[1000001];
} MyHashSet;
MyHashSet *myHashSetCreate()
{
MyHashSet *obj = (MyHashSet *)calloc(sizeof(MyHashSet), 1);
return obj;
}
void myHashSetAdd(MyHashSet *obj, int key)
{
obj->hash[key] = 1;
}
void myHashSetRemove(MyHashSet *obj, int key)
{
obj->hash[key] = 0;
}
bool myHashSetContains(MyHashSet *obj, int key)
{
return obj->hash[key];
}
void myHashSetFree(MyHashSet *obj)
{
free(obj);
}
211. 添加与搜索单词
请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。
实现词典类 WordDictionary :
WordDictionary() 初始化词典对象
void addWord(word) 将 word 添加到数据结构中,之后可以对它进行匹配
bool search(word) 如果数据结构中存在字符串与 word 匹配,则返回 true ;否则,返回 false 。word 中可能包含一些 ‘.’ ,每个 . 都可以表示任何一个字母。
示例:
输入:
[“WordDictionary”,“addWord”,“addWord”,“addWord”,“search”,“search”,“search”,“search”]
[[],[“bad”],[“dad”],[“mad”],[“pad”],[“bad”],[“.ad”],[“b…”]]
输出:
[null,null,null,null,false,true,true,true]
解释:
WordDictionary wordDictionary = new WordDictionary();
wordDictionary.addWord(“bad”);
wordDictionary.addWord(“dad”);
wordDictionary.addWord(“mad”);
wordDictionary.search(“pad”); // 返回 False
wordDictionary.search(“bad”); // 返回 True
wordDictionary.search(“.ad”); // 返回 True
wordDictionary.search(“b…”); // 返回 True
提示:
1 <= word.length <= 25
addWord 中的 word 由小写英文字母组成
search 中的 word 由 ‘.’ 或小写英文字母组成
最多调用 10^4 次 addWord 和 search
思路1:HASH_FIND_STR 的应用
思路2:判断字符’.’ , 用HASH_ITER遍历判断
int Cmp(const void* a, const void* b)
{
char *aa = (char *)a;
char *bb = (char *)b;
return *bb - *aa;
}
typedef struct {
int len;
char name[26];
UT_hash_handle hh;
} WordDictionary;
WordDictionary *g_obj = NULL;
int g_idx = 0;
WordDictionary *wordDictionaryCreate()
{
g_obj = NULL;
WordDictionary *obj = (WordDictionary *)malloc(sizeof(WordDictionary));
obj = NULL;
return obj;
}
void wordDictionaryAddWord(WordDictionary *obj, char *word)
{
WordDictionary *tmp;
HASH_FIND_STR(g_obj, word, tmp);
if (tmp == NULL) {
tmp = (WordDictionary *)malloc(sizeof(WordDictionary));
tmp->len = strlen(word);
strcpy(tmp->name, word);
HASH_ADD_STR(g_obj, name, tmp); // name是结构体字段 不是变量
}
}
bool IsSame(char *newWord, char *oldWord, int len)
{
for (int i = 0; i < len; i++) {
if ((oldWord[i] != '.') && (newWord[i] != oldWord[i])) {
return false;
}
}
return true;
}
bool wordDictionarySearch(WordDictionary *obj, char *word)
{
WordDictionary* current, * temp;
int len = strlen(word); // strlen很耗时,循环里面慎用
HASH_ITER(hh, g_obj, current, temp) {
if (current != NULL) {
if (len != current->len) {
continue;
}
if (IsSame(current->name, word, len)) {
return true;
}
}
}
return false;
}
void wordDictionaryFree(WordDictionary *obj)
{
;
}
void PrintAllUsers()
{
WordDictionary *current, *temp;
HASH_ITER(hh, g_obj, current, temp) {
printf("User:%s, LEN: %d\n", current->name, current->len);
}
}
244. 最短单词距离Ⅱ
请设计一个类,使该类的构造函数能够接收一个字符串数组。然后再实现一个方法,该方法能够分别接收两个单词,并返回列表中这两个单词之间的最短距离。
实现 WordDistanc 类:
WordDistance(String[] wordsDict) 用字符串数组 wordsDict 初始化对象。
int shortest(String word1, String word2) 返回数组 worddict 中 word1 和 word2 之间的最短距离。
示例 1:
输入:
[“WordDistance”, “shortest”, “shortest”]
[[[“practice”, “makes”, “perfect”, “coding”, “makes”]], [“coding”, “practice”], [“makes”, “coding”]]
输出:
[null, 3, 1]
解释:
WordDistance wordDistance = new WordDistance([“practice”, “makes”, “perfect”, “coding”, “makes”]);
wordDistance.shortest(“coding”, “practice”); // 返回 3
wordDistance.shortest(“makes”, “coding”); // 返回 1
注意:
1 <= wordsDict.length <= 3 * 10^4
1 <= wordsDict[i].length <= 10
wordsDict[i] 由小写英文字母组成
word1 和 word2 在数组 wordsDict 中
word1 != word2
shortest 操作次数不大于 5000
typedef struct {
char key[102];
int pos[102];
int cnt;
UT_hash_handle hh;
} WordDistance;
WordDistance *g_user = NULL;
WordDistance *wordDistanceCreate(char **wordsDict, int wordsDictSize)
{
g_user = NULL;
for (int i = 0; i < wordsDictSize; i++) {
WordDistance *temp = NULL;
HASH_FIND_STR(g_user, wordsDict[i], temp);
if (temp == NULL) {
temp = (WordDistance *)malloc(sizeof(WordDistance));
strcpy(temp->key, wordsDict[i]);
temp->pos[0] = i;
temp->cnt = 1;
HASH_ADD_STR(g_user, key, temp);
} else { // 如果重复出现了,则更新位置
temp->pos[temp->cnt] = i;
temp->cnt++;
}
}
return NULL;
}
int wordDistanceShortest(WordDistance *obj, char *word1, char *word2)
{
int ans = INT_MAX;
WordDistance *cur = NULL;
WordDistance *tmp = NULL;
HASH_FIND_STR(g_user, word1, cur);
HASH_FIND_STR(g_user, word2, tmp);
if (cur != NULL && tmp != NULL) {
int len1 = cur->cnt;
int len2 = tmp->cnt;
for (int i = 0; i < len1; i++) {
for (int j = 0; j < len2; j++) {
int res = abs(cur->pos[i] - tmp->pos[j]);
ans = fmin(ans, res);
}
}
}
return ans;
}
void wordDistanceFree(WordDistance *obj)
{
WordDistance *cur = NULL;
WordDistance *tmp = NULL;
HASH_ITER(hh, g_user, cur, tmp) {
if (cur != NULL) {
HASH_DEL(g_user, cur);
free(cur);
}
}
}
379. 电话目录管理系统
- get: 分配给用户一个未被使用的电话号码,获取失败请返回 -1
- check: 检查指定的电话号码是否被使用
- release: 释放掉一个电话号码,使其能够重新被分配

思路:HASH的应用
#define PHONE_OCCUPY 2 // 未被使用赋值为 2,已占用赋值为1
#define PHONE_FREE 1
// 号码节点的定义
typedef struct Node_t {
int valid;
int val;
} Node;
// 电话目录的定义
typedef struct {
Node *node;
int capacity;
} PhoneDirectory;
// 1.电话目录的初始化
PhoneDirectory *phoneDirectoryCreate(int maxNumbers)
{typedef struct {
int key;
int used;
UT_hash_handle hh;
} PhoneDirectory;
PhoneDirectory *g_table = NULL;
PhoneDirectory *phoneDirectoryCreate(int maxNumbers)
{
g_table = NULL;
for (int i = 0; i < maxNumbers; i++) {
PhoneDirectory *tmp = (PhoneDirectory *)malloc(sizeof(PhoneDirectory));
tmp->key = i;
tmp->used = 0;
HASH_ADD_INT(g_table, key, tmp);
}
return NULL;
}
int phoneDirectoryGet(PhoneDirectory *obj)
{
PhoneDirectory *cur = NULL;
PhoneDirectory *tmp = NULL;
HASH_ITER(hh, g_table, cur, tmp) {
if (cur != NULL) {
if (cur->used == 0) {
cur->used = 1;
return cur->key;
}
}
}
return -1;
}
bool phoneDirectoryCheck(PhoneDirectory *obj, int number)
{
PhoneDirectory *tmp = NULL;
HASH_FIND_INT(g_table, &number, tmp);
if ((tmp != NULL) && (tmp->used == 0)) {
return true;
}
return false;
}
void phoneDirectoryRelease(PhoneDirectory *obj, int number)
{
PhoneDirectory *temp = NULL;
HASH_FIND_INT(g_table, &number, temp);
if (temp != NULL) {
temp->used = 0;
}
return;
}
void phoneDirectoryFree(PhoneDirectory *obj)
{
PhoneDirectory *cur = NULL;
PhoneDirectory *tmp = NULL;
HASH_ITER(hh, g_table, cur, tmp) {
if (cur != NULL) {
HASH_DEL(g_table, cur);
free(cur);
}
}
}
1396. 设计地铁系统

数据结构
#define MAX_SIZE 10000
#define STANAME_LEN 12
// 乘客结构体
typedef struct {
int passenger_id;
char start_station[STANAME_LEN];
char end_station[STANAME_LEN];
double start_time;
double end_time;
} Passenger;
// 地铁系统
typedef struct {
int passenger_num;
Passenger passenger[MAX_SIZE];
} UndergroundSystem;
主函数
// 创建地铁系统
UndergroundSystem *undergroundSystemCreate()
{
UndergroundSystem *obj = (UndergroundSystem *)malloc(sizeof(UndergroundSystem) * 1);
memset(obj, 0, sizeof(UndergroundSystem));
if (!obj) {
return NULL;
}
obj->passenger_num = 0;
return obj;
}
// 通行卡ID等于id的乘客,在时间t,从stationName站进入
void undergroundSystemCheckIn(UndergroundSystem *obj, int id, char *stationName, int t)
{
obj->passenger[obj->passenger_num].passenger_id = id;
strcpy(obj->passenger[obj->passenger_num].start_station, stationName);
obj->passenger[obj->passenger_num].start_time = t;
obj->passenger_num++;
return;
}
// 通行卡ID等于id的乘客,在时间t,从stationName站离开
void undergroundSystemCheckOut(UndergroundSystem *obj, int id, char *stationName, int t)
{
int pnum = obj->passenger_num;
// 找到id的乘客
for (int i = 0; i < obj->passenger_num; i++) {
if (obj->passenger[i].passenger_id == id) {
if (obj->passenger[i].end_station[0] != '\0') {
continue;
}
pnum = i;
break;
}
}
// 如果找到的ID合法,则记录下离开站与时间
if (pnum != obj->passenger_num) {
strcpy(obj->passenger[pnum].end_station, stationName);
obj->passenger[pnum].end_time = t;
}
return;
}
// 返回从startStation站到endStation站的平均时间
double undergroundSystemGetAverageTime(UndergroundSystem *obj, char *startStation, char *endStation)
{
double num = 0.0;
double sum = 0.0;
for (int i = 0; i < obj->passenger_num; i++) {
if (!strcmp(startStation, obj->passenger[i].start_station)
&& !strcmp(endStation, obj->passenger[i].end_station)) {
num++;
sum += obj->passenger[i].end_time - obj->passenger[i].start_time;
}
}
return sum / num;
}
// 释放
void undergroundSystemFree(UndergroundSystem* obj)
{
free(obj);
return;
}
635. 设计日志存储系统

strncmp 总结需要
这题巧用了 strncmp 函数,用来比较带size的字符串,且
int strncmp(const char *str1, const char *str2, size_t n);
// 如果返回值 < 0,则表示 str2 大于 str1
// 如果返回值 > 0,则表示 str2 小于 str1
数据结构
#define MAXSIZE 500
// 日志存储数据结构
typedef struct {
char *timeStamp[MAXSIZE];
int id[MAXSIZE];
int count;
} LogSystem;
主函数
// 初始化LogSystem对象
LogSystem *logSystemCreate(void)
{
LogSystem *gLogsys = (LogSystem *)malloc(sizeof(LogSystem));
gLogsys->count = 0;
memset(gLogsys, 0, sizeof(LogSystem));
for (int i = 0; i < MAXSIZE; i++) {
gLogsys->timeStamp[i] = (char *)malloc(sizeof(char) * (MAXSIZE));
memset(gLogsys->timeStamp[i], 0, sizeof(char) * (MAXSIZE));
}
return gLogsys;
}
// 给定日志的id和timestamp,将这个日志存入你的存储系统中
void logSystemPut(LogSystem *obj, int id, char *timestamp)
{
obj->id[obj->count] = id;
memcpy(obj->timeStamp[obj->count], timestamp, strlen(timestamp) + 1);
obj->count++;
return;
}
// 检索给定时间区间[start, end](包含两端)内的所有日志的id
int *logSystemRetrieve(LogSystem *obj, char *start, char *end, char *granularity, int *retSize)
{
int i;
int len = 0;
char *classification[6] = { "Year", "Month", "Day", "Hour", "Minute", "Second" };
int classLength[6] = { 4, 7, 10, 13, 16, 19 }; // 上述时间的字符串长度
for (i = 0; i < 6; i++) {
// granularity表示考虑的时间粒度(例如,精确到 Day、Minute 等)
if (strcmp(granularity, classification[i]) == 0) {
len = classLength[i];
break;
}
}
int *ret = (int *)malloc(sizeof(int) * (obj->count));
memset(ret, 0, sizeof(int)*obj->count);
// 如果返回值 < 0,则表示 str2 大于 str1
// 如果返回值 > 0,则表示 str2 小于 str1
for (i = obj->count; i >= 0; i--) { // 由于题目要求输出的顺序,所以这里从后往前了.
if (strncmp(start, obj->timeStamp[i], len) <= 0 && strncmp(end, obj->timeStamp[i], len) >= 0) {
ret[(*retSize)++] = obj->id[i];
}
}
return ret;
}
void logSystemFree(LogSystem *obj)
{
memset(obj, 0, sizeof(LogSystem));
obj->count = 0;
}
1845. 座位预约管理系统
请你设计一个管理 n 个座位预约的系统,座位编号从 1 到 n 。
请你实现 SeatManager 类:
SeatManager(int n) 初始化一个 SeatManager 对象,它管理从 1 到 n 编号的 n 个座位。所有座位初始都是可预约的。
int reserve() 返回可以预约座位的 最小编号 ,此座位变为不可预约。
void unreserve(int seatNumber) 将给定编号 seatNumber 对应的座位变成可以预约。
示例 1:
输入:
[“SeatManager”, “reserve”, “reserve”, “unreserve”, “reserve”, “reserve”, “reserve”, “reserve”, “unreserve”]
[[5], [], [], [2], [], [], [], [], [5]]
输出:
[null, 1, 2, null, 2, 3, 4, 5, null]
解释:
SeatManager seatManager = new SeatManager(5); // 初始化 SeatManager ,有 5 个座位。
seatManager.reserve(); // 所有座位都可以预约,所以返回最小编号的座位,也就是 1 。
seatManager.reserve(); // 可以预约的座位为 [2,3,4,5] ,返回最小编号的座位,也就是 2 。
seatManager.unreserve(2); // 将座位 2 变为可以预约,现在可预约的座位为 [2,3,4,5] 。
seatManager.reserve(); // 可以预约的座位为 [2,3,4,5] ,返回最小编号的座位,也就是 2 。
seatManager.reserve(); // 可以预约的座位为 [3,4,5] ,返回最小编号的座位,也就是 3 。
seatManager.reserve(); // 可以预约的座位为 [4,5] ,返回最小编号的座位,也就是 4 。
seatManager.reserve(); // 唯一可以预约的是座位 5 ,所以返回 5 。
seatManager.unreserve(5); // 将座位 5 变为可以预约,现在可预约的座位为 [5] 。
提示:
1 <= n <= 10^5
1 <= seatNumber <= n
每一次对 reserve 的调用,题目保证至少存在一个可以预约的座位。
每一次对 unreserve 的调用,题目保证 seatNumber 在调用函数前都是被预约状态。
对 reserve 和 unreserve 的调用 总共 不超过 10^5 次。
typedef struct {
int key;
UT_hash_handle hh;
} SeatManager;
SeatManager *g_table;
SeatManager *seatManagerCreate(int n)
{
g_table = NULL;
SeatManager *tmp;
SeatManager *obj = (SeatManager *)malloc(sizeof(SeatManager));
for (int i = 1; i <= n; i++) {
tmp = (SeatManager *)malloc(sizeof(SeatManager));
tmp->key = i;
HASH_ADD_INT(g_table, key, tmp);
}
return obj;
}
int seatManagerReserve(SeatManager *obj)
{
SeatManager *tmp, *cur;
int ret = 0;
HASH_ITER(hh, g_table, cur, tmp) {
ret = cur->key;
HASH_DEL(g_table, cur);
break; // 返回最上面的元素
}
return ret;
}
int Cmp(const void *a, const void *b)
{
SeatManager *aa = (SeatManager *)a;
SeatManager *bb = (SeatManager *)b;
return (aa->key - bb->key);
}
void seatManagerUnreserve(SeatManager* obj, int seatNumber)
{
SeatManager *tmp;
HASH_FIND_INT(g_table, &seatNumber, tmp);
if (tmp == NULL) {
tmp = (SeatManager *)malloc(sizeof(SeatManager));
tmp->key = seatNumber;
HASH_ADD_INT(g_table, key, tmp); // 恢复一个元素
}
// 重新排序
HASH_SORT(g_table, Cmp);
}
void seatManagerFree(SeatManager *obj)
{
free(obj);
return;
}
可信考试不考试算法,本题题解建议使用最小堆优化,而可信不考试算法,所以先书写HASH表的使用即可

729. 我的日程安排表 I
实现一个 MyCalendar 类来存放你的日程安排。如果要添加的日程安排不会造成 重复预订 ,则可以存储这个新的日程安排。
当两个日程安排有一些时间上的交叉时(例如两个日程安排都在同一时间内),就会产生 重复预订 。
日程可以用一对整数 startTime 和 endTime 表示,这里的时间是半开区间,即 [startTime, endTime), 实数 x 的范围为, startTime <= x < endTime 。
实现 MyCalendar 类:
MyCalendar() 初始化日历对象。
boolean book(int startTime, int endTime) 如果可以将日程安排成功添加到日历中而不会导致重复预订,返回 true 。否则,返回 false 并且不要将该日程安排添加到日历中。
示例:
输入:
[“MyCalendar”, “book”, “book”, “book”]
[[], [10, 20], [15, 25], [20, 30]]
输出:
[null, true, false, true]
解释:
MyCalendar myCalendar = new MyCalendar();
myCalendar.book(10, 20); // return True
myCalendar.book(15, 25); // return False ,这个日程安排不能添加到日历中,因为时间 15 已经被另一个日程安排预订了。
myCalendar.book(20, 30); // return True ,这个日程安排可以添加到日历中,因为第一个日程安排预订的每个时间都小于 20 ,且不包含时间 20 。
提示:
0 <= start < end <= 10^9
每个测试用例,调用 book 方法的次数最多不超过 1000 次。
typedef struct {
int start;
int end;
UT_hash_handle hh;
} MyCalendar;
MyCalendar *g_table;
MyCalendar *myCalendarCreate()
{
g_table = NULL;
MyCalendar *obj = (MyCalendar *)malloc(sizeof(MyCalendar));
return obj;
}
bool myCalendarBook(MyCalendar *obj, int startTime, int endTime)
{
MyCalendar *cur, *tmp;
HASH_ITER(hh, g_table, cur, tmp) {
if (!((startTime >= cur->end) || (endTime <= cur->start))) { // 不重叠的条件取反,则是判断重叠则返回
return false;
}
}
tmp = (MyCalendar *)malloc(sizeof(MyCalendar));
tmp->start = startTime;
tmp->end = endTime;
HASH_ADD_INT(g_table, start, tmp);
return true;
}
void myCalendarFree(MyCalendar *obj)
{
MyCalendar *cur, *tmp;
HASH_ITER(hh, g_table, cur, tmp) {
if (cur != NULL) {
HASH_DEL(g_table, cur);
free(cur);
}
}
}
731. 我的日程安排表 II
实现一个程序来存放你的日程安排。如果要添加的时间内不会导致三重预订时,则可以存储这个新的日程安排。
当三个日程安排有一些时间上的交叉时(例如三个日程安排都在同一时间内),就会产生 三重预订。
事件能够用一对整数 startTime 和 endTime 表示,在一个半开区间的时间 [startTime, endTime) 上预定。实数 x 的范围为 startTime <= x < endTime。
实现 MyCalendarTwo 类:
MyCalendarTwo() 初始化日历对象。
boolean book(int startTime, int endTime) 如果可以将日程安排成功添加到日历中而不会导致三重预订,返回 true。否则,返回 false 并且不要将该日程安排添加到日历中。
typedef struct {
int start;
int end;
UT_hash_handle hh;
} MyCalendarTwo;
MyCalendarTwo *g_table1, *g_table2;
MyCalendarTwo *myCalendarTwoCreate()
{
g_table1 = NULL;
g_table2 = NULL;
MyCalendarTwo *obj = (MyCalendarTwo *)malloc(sizeof(MyCalendarTwo));
return obj;
}
bool myCalendarTwoBook(MyCalendarTwo *obj, int startTime, int endTime)
{
MyCalendarTwo *cur1, *tmp1;
MyCalendarTwo *cur2, *tmp2;
// 1. 二重区间里查找是否重叠
HASH_ITER(hh, g_table2, cur2, tmp2) {
if (!((startTime >= cur2->end) || (endTime <= cur2->start))) { // 不重叠的条件取反,则是判断重叠则返回
return false;
}
}
// 2. 判断当前点是否有
HASH_ITER(hh, g_table1, cur1, tmp1) {
if (!((startTime >= cur1->end) || (endTime <= cur1->start))) { // 不重叠的条件取反,则是判断重叠则返回
if ((cur1->start < startTime) && (cur1->end > startTime)) {
tmp2 = (MyCalendarTwo *)malloc(sizeof(MyCalendarTwo));
tmp2->start = startTime;
tmp2->end = fmin(cur1->end, endTime); // 手法处理,这里要注意!
HASH_ADD_INT(g_table2, start, tmp2);
} else if ((cur1->start >= startTime) && (cur1->end <= endTime)) {
tmp2 = (MyCalendarTwo *)malloc(sizeof(MyCalendarTwo));
tmp2->start = fmax(cur1->start, startTime);
tmp2->end = fmin(cur1->end, endTime);
HASH_ADD_INT(g_table2, start, tmp2);
} else if ((cur1->start < endTime) && (cur1->end > endTime)) {
tmp2 = (MyCalendarTwo *)malloc(sizeof(MyCalendarTwo));
tmp2->start = fmax(cur1->start, startTime); // 手法处理,这里要注意!
tmp2->end = endTime;
HASH_ADD_INT(g_table2, start, tmp2);
}
} else {
; // 完全不重叠
}
}
tmp1 = (MyCalendarTwo *)malloc(sizeof(MyCalendarTwo));
tmp1->start = startTime;
tmp1->end = endTime;
HASH_ADD_INT(g_table1, start, tmp1);
return true;
}
void myCalendarTwoFree(MyCalendarTwo*obj)
{
MyCalendarTwo *cur, *tmp;
HASH_ITER(hh, g_table1, cur, tmp) {
if (cur != NULL) {
HASH_DEL(g_table1, cur);
free(cur);
}
}
HASH_ITER(hh, g_table2, cur, tmp) {
if (cur != NULL) {
HASH_DEL(g_table2, cur);
free(cur);
}
}
}
int main()
{
MyCalendarTwo *obj = myCalendarTwoCreate();
printf("%d\n", myCalendarTwoBook(obj, 10, 20));
printf("%d\n", myCalendarTwoBook(obj, 50, 60));
printf("%d\n", myCalendarTwoBook(obj, 10, 40));
printf("%d\n", myCalendarTwoBook(obj, 5, 15));
printf("%d\n", myCalendarTwoBook(obj, 5, 10));
printf("%d\n", myCalendarTwoBook(obj, 25, 55));
return 0;
}
4. 缓存
146. LRU 缓存机制

C语言优秀库uthash底层本身就是用双向链表实现的hash
至于题目中说的当达到容量时,先删除最久未使用的数据,这个最久未使用就在双向链表的表头,可以自己写一些add测试下,综上分析,无需一个 表示使用次数的变量,而是利用uthash底层的数据结构就可以实现
typedef struct {
int key;
int val;
UT_hash_handle hh;
} LRUCache;
LRUCache *g_table = NULL;
int g_size;
// 1.初始化
LRUCache *lRUCacheCreate(int capacity)
{
LRUCache *obj = (LRUCache *)malloc(sizeof(LRUCache));
g_size = capacity;
return obj;
}
// 2.如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1
int lRUCacheGet(LRUCache *obj, int key)
{
LRUCache *tmp = NULL;
HASH_FIND_INT(g_table, &key, tmp);
// 因为链表表头存的是最久为使用的数据,所以get一次就要把它更新到链表末尾
// 秒啊,get存在的key,则该key被使用了一次,因此需要先删后入,满足LRU
if (tmp != NULL) {
HASH_DEL(g_table, tmp);
HASH_ADD_INT(g_table, key, tmp);
return tmp->val;
}
// 如果没有找到,则返回-1
return -1;
}
// 3.如果关键字 key 已经存在,则变更其数据值 value
void lRUCachePut(LRUCache *obj, int key, int value)
{
LRUCache *cur = NULL, *next = NULL;
HASH_FIND_INT(g_table, &key, cur);
if (cur != NULL) { // 更新
HASH_DEL(g_table, cur);
cur->key = key;
cur->val = value;
HASH_ADD_INT(g_table, key, cur);
}
else { // 新插入
int cnt = HASH_COUNT(g_table);
// 如果已经满size了
if (cnt == g_size) {
HASH_ITER(hh, g_table, cur, next) {
HASH_DEL(g_table, cur);
free(cur);
break; // 只删除一个元素
}
}
LRUCache *new = (LRUCache *)malloc(sizeof(LRUCache));
new->key = key;
new->val = value;
HASH_ADD_INT(g_table, key, new);
}
return;
}
void lRUCacheFree(LRUCache *obj)
{
LRUCache *cur = NULL, *next = NULL;
HASH_ITER(hh, g_table, cur, next) {
HASH_DEL(g_table, cur);
free(cur);
}
}

















 8280
8280




 到【灌水乐园】发言
到【灌水乐园】发言







