




 本文全面解析Kafka消息队列系统,涵盖其基本概念、工作原理、消费方式、Broker角色、分区策略、存储机制及顺序性保障。深入探讨Kafka如何通过高效的数据管理和消费组机制,实现大规模数据流处理。
本文全面解析Kafka消息队列系统,涵盖其基本概念、工作原理、消费方式、Broker角色、分区策略、存储机制及顺序性保障。深入探讨Kafka如何通过高效的数据管理和消费组机制,实现大规模数据流处理。
1、kafka基本概念
kafka是一个支持离线和在线的、分布式、可分区、可复制消息队列。
producer1,producer2 -----(topic)----->kafka cluster-----(topic)----->consumer1,consumer2
client与server通过TCP协议通信
2、producer
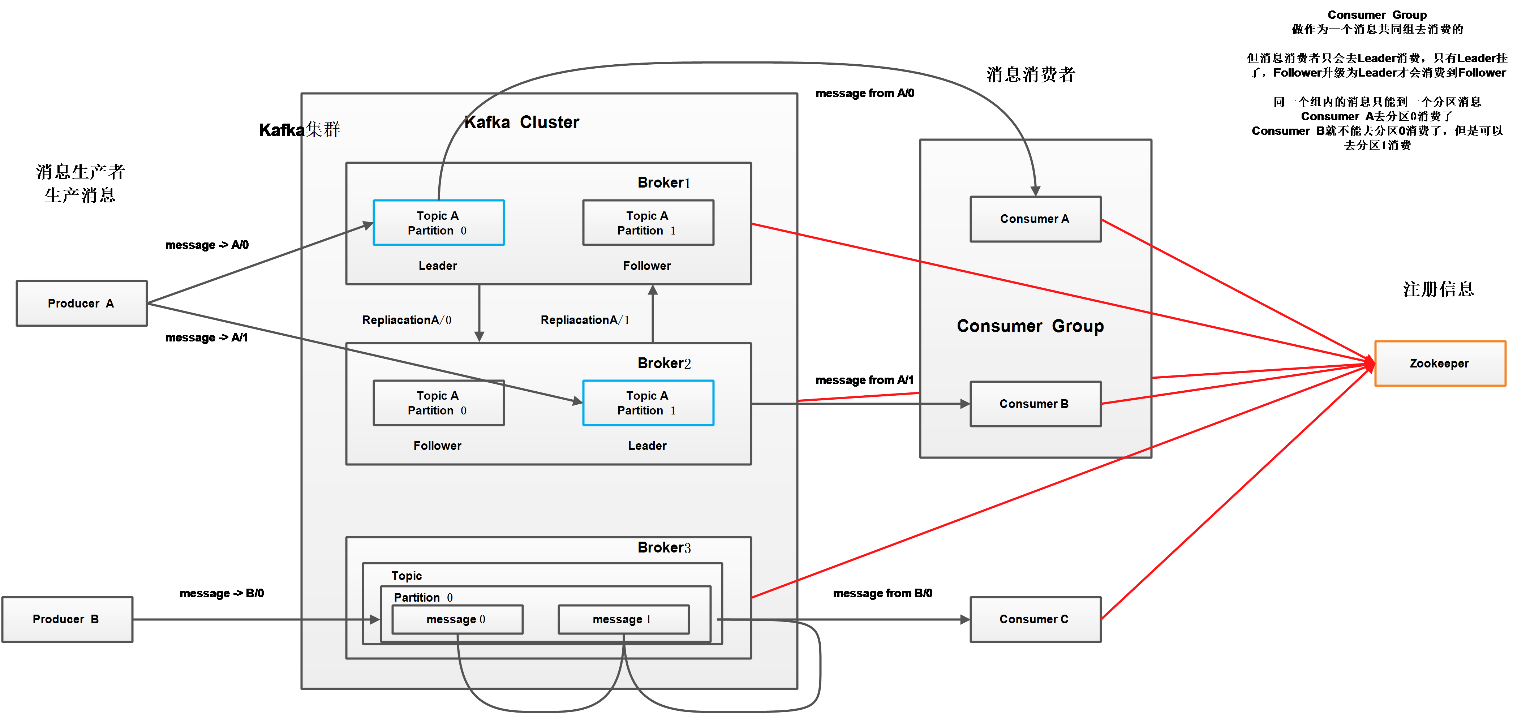
producer通过topic将消息发送到消息队列,consumer通过订阅topic从消息队列消费对应的消息。
3、consumer
一对多的消费模式中,多个消费者都属于一个消费组。订阅对应topic的消费者,在收到对应topic消息过来时,消息会在所有的消费者之间实现负载均衡。如果消费者具有不同的组,消息会被以广播形式发送给“发布-订阅”中的订阅者。(没懂,感觉类似)
kafka不会维护producer和consumer的状态信息,保活通过zookeeper完成。
4、消费方式
传统的消息传递有两种方式: 队列方式(queuing)、发布-订阅(publish-subscribe)方式.
队列方式:一组消费者从机器上读消息,每个消息只传递给这组消费者中的一个。
分布-订阅方式:消息被广播到所有的消费者。Kafka提供了一个消费组(consumer group)的说法来概括这两种方式。
5、broker
一台kafka server就是一个broker
一个broker包含多个topic
6、partition
(1)为什么要分区?
订阅同一个topic的消息者,通过不同partion实现隔离。
以partition为单位读写,提高高并发。
kafka replication策略是基于partition的, 而不是基于topic。
(2)分区原则
a)指定了partition则直接使用。
b)未指定partition,但指定了key,对key的value进行一次hash出一个partition。
c)patition和key均未指定,rotate一个partition。
提供者和消费者是一对多的映射关系,每个topic被划分为多个partition,从而映射到多个消费者。每个消费者会被分配一个分区,消费者数目不会超过分区数。partition之间相互隔离,每个partition在存储层面就是append log。
(3) partition中文件存储方式
partition在物理上被切分成多个大小相等的segment组成,每个segment消息数不一定相等。这样方便老的segment生命周期管理。
上图来源于网络, 如有侵权,请联系删除。
7、topics & logs
发送到partition的消息会被以log形式追加到log尾部。消息在存储文件中的位置称为偏移量offset,offset唯一地标记一条消息。
Anatomy of topic:
patition0 0 1 2 3 4 5 6 7 8 9 10 (<-----write )
patition1 0 1 2 3 4 5 6 7 8 9 10 (<-----write )
patition2 0 1 2 3 4 5 6 7 8 9 10 (<-----write )
old------------------->new
8、distribution
一个Topic 的多个partitions,被分布在kafka 集群中的多个server 上;每个server(kafka 实例)负责partitions中消息的读写操作;此外kafka 还可以配置partitions 需要备份的个数(replicas),每个partition 将会被备份到多台机器上,以提高可用性。
如果Topic 的"replication factor"(备份因子)为N,那么允许N-1 个kafka实例失效。
基于replicated(冗余) 方案,那么就意味着需要对多个备份进行调度;每个partition 都有一个机器为"leader";零个或多个机器作为follower。leader 负责所有的读写操作,follower执行leader的指令。如果leader 失效,那么将会有其他follower 来接管(成为新的leader);follower只是单调的和leader 跟进,同步消息即可。由此可见作为leader 的server 承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定。
9、存储策略
被消费掉的消息并不会被立即删除,文件系统会根据broker中配置,定时删除已消费的和未被消费的消息,从而减少磁盘空间和IO开销。
Kafka有两种策略:
(1)基于时间:log.retention.hours=168
(2)基于大小:log.retention.bytes=1073741824
kafka读取特定消息时间复杂度为O(1),与文件系统大小无关,所以删除过期文件对提升kafka性能无关?
10、顺序性
kafka保证一个分区内的消息是顺序消费的。
对于消费者而言,它们消费消息的顺序和日志中消息顺序一致。
所以,如果要保证消息是全局有序的,可以设置topic只有一个分区,但这也意味着只有一个消费者。
11、kafka节点保活

















 2700
2700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









