




 本文介绍了如何使用SQL的group by、having、elt和INTERVAL函数来实现对数据的高级统计分析。包括找出发博量大于1000的用户并排序,计算平均发博量,以及利用elt和INTERVAL进行发博区间的人数统计。INTERVAL函数用于区间定位,而elt函数则用于根据给定的下标获取数组值。
本文介绍了如何使用SQL的group by、having、elt和INTERVAL函数来实现对数据的高级统计分析。包括找出发博量大于1000的用户并排序,计算平均发博量,以及利用elt和INTERVAL进行发博区间的人数统计。INTERVAL函数用于区间定位,而elt函数则用于根据给定的下标获取数组值。
基本需求
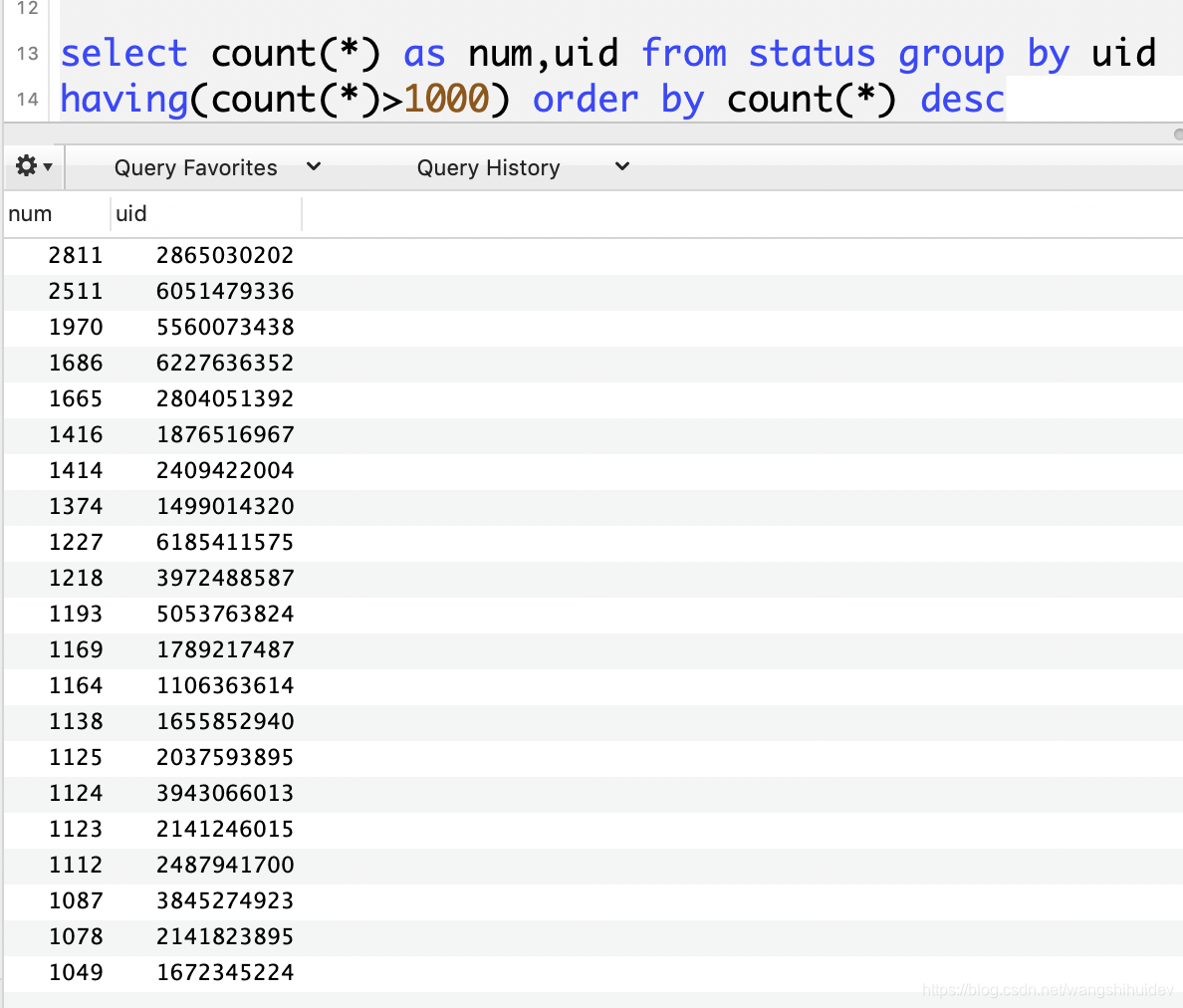
找到发博量大于1000的用户并排序:group by + having
select count(*) as num,uid from status group by uid
having(count(*)>1000) order by count(*) desc
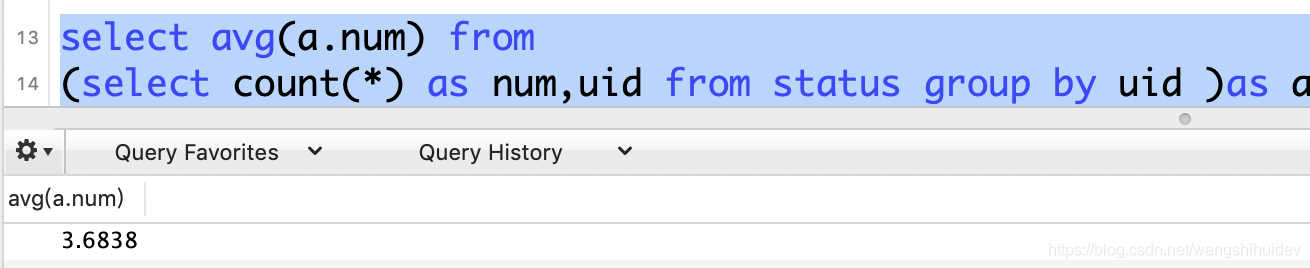
统计平均发博量:group by+子查询
select avg(a.num) from
(select count(*) as num,uid from status group by uid )as a
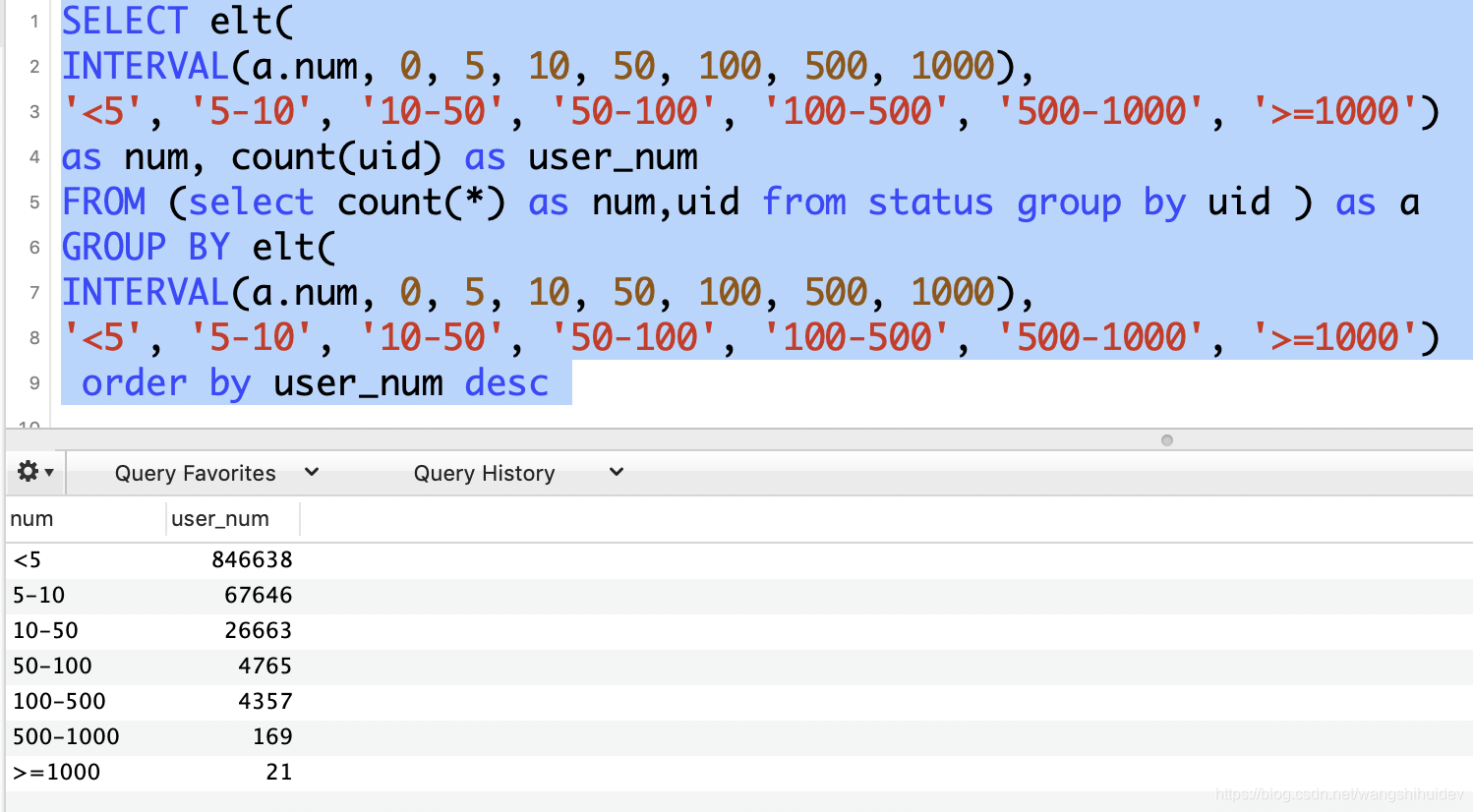
进阶需求
按照发博区间统计人数:elt+INTERVAL
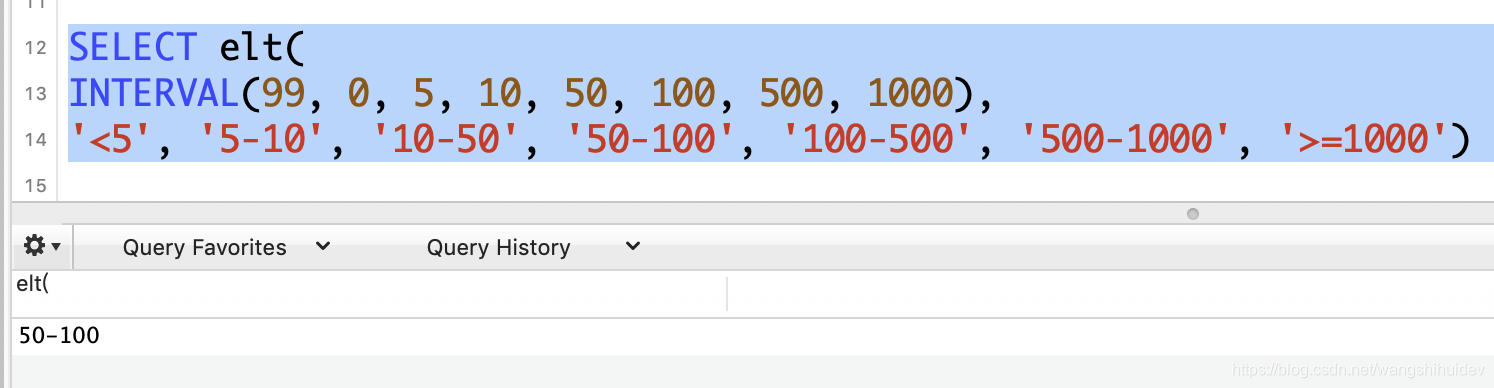
SELECT elt(
INTERVAL(a.num, 0, 5, 10, 50, 100, 500, 1000),
'<5', '5-10', '10-50', '50-100', '100-500', '500-1000', '>=1000')
as num, count(uid) as user_num
FROM (select count(*) as num,uid from status group by uid ) as a
GROUP BY elt(
INTERVAL(a.num, 0, 5, 10, 50, 100, 500, 1000),
'<5', '5-10', '10-50', '50-100', '100-500', '500-1000', '>=1000')
order by user_num desc
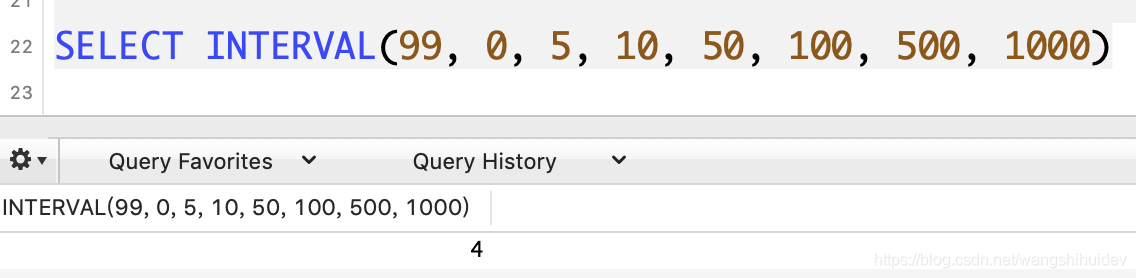
INTERVAL:区间定位
INTERVAL(N,N1,N2,N3,…)
INTERVAL()函数用于定位N在后续N1、N2、N3…组成区间的位置,列表值要求满足N1<N2<N3…。返回所在区间下标。
elt:数组取值
ELT(N,N1,N2,N3,…)
如果N=1则返回N1,如果N=2则返回N2,如果N=3则返回N3
elt+INTERVAL

















 5650
5650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









