




 本文讨论了在SQL Server中如何使用递归查询删除包含下级部门的记录,并提出了一种优化数据库设计的方法,通过code和parentCode字段替代parentId来简化层级关系查询,避免递归操作,提高效率。
本文讨论了在SQL Server中如何使用递归查询删除包含下级部门的记录,并提出了一种优化数据库设计的方法,通过code和parentCode字段替代parentId来简化层级关系查询,避免递归操作,提高效率。
预设条件:公司下设置三级部门信息,部门表Department字段设计如下,其中有四个字段(公司ID未体现):
id:部门ID,自增主键;
name:部门名字;
parentId:父级部门ID;
deleted:是否删除,0未删除,1已删除。
现在要删除部门信息,可以想到在删除部门信息的时候,如果删除的是一级部门,那么它下面的二级部门和三级部门也要删除。这时,我需要根据要删除的部门的部门ID,得到此部门的下级部门ID们。
现有表数据如下(一级部门的parentId设置为0):

我们可以看到它的部门结构如下:

如果在删除部门的接口中,我们传入的部门id为10003,我们希望把部门ID为10003, 10004,10005, 10006, 10008的数据一起删除。这里使用了SQL server的递归查询获取所有的下级部门ID:
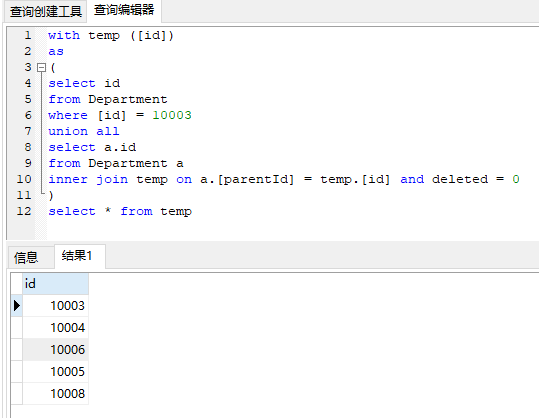
可以看到查询出了部门Id为10003的所有下级部门ID和他自己本身的ID。上面的ID可以放到Set里面,这样我们可以根据Set进行批量删除。
上面展示的sql如下:
with temp ([id])
as
(
select id
from Department
where [id] = 10003
union all
select a.id
from Department a
inner join temp on a.[parentId] = temp.[id] and deleted = 0
)
select * from temp
数据库设计优化:
在设计数据库的时候,涉及到一级二级三级的信息,又是存储在同一张表里面的,可以不设置parentId字段,用code和parentCode两个字段来展示上下级的关系(此处省去公司信息)。如下所示:
| id | name | code | parentCode | deleted |
| 1 | 技术部 | 100 | 0 | 0 |
| 2 | 前端 | 100100 | 100 | 0 |
| 3 | 后端 | 100101 | 100 | 0 |
| 4 | Java开发 | 100101100 | 100101 | 0 |
| 5 | python开发 | 100101101 | 100101 | 0 |
| 6 | 财务部 | 101 | 0 | 0 |
| 7 | 人事部 | 102 | 0 | 0 |
code用固定的位数来表示,同一个公司下的一级部门从100开始,每增加一个一级部门,就在已有的最大部门code上加1,二级部门为上级部门code后面加上三位,加的三位也是从100开始。以此类推。这样同一公司的一级部门有999个位置,每个部门的下级部门也有999个位置。如果数据量大的,可以给一级设置为4位的code,这样每级都有9999个位置。
这样当我们获取某部门和它的下级部门的id的时候,我们就不需要递归查询,而是用一个简单的子查询就可以了:
SELECT id FROM Department WHERE (SELECT code from Department WHERE id = 1) = LEFT(code,3);
可以看出,层级关系更加鲜明了。

















 6649
6649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









