




参考:ChatBI完成DeepSeek-R1大模型适配升级,开启大数据分析+大模型新时代-优快云博客
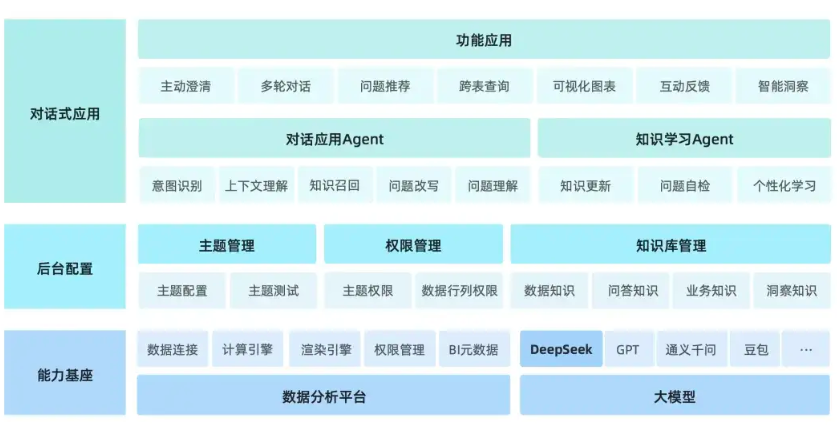
ChatBI 是一款基于大语言模型(LLM)打造的智能数据问答产品,提供意图识别、知识召回、问题理解、数据查询、可视化生成等能力。用户通过自然语言提问,便可获取数据分析结果,实现敏捷决策。有效解决了传统BI的灵活性和门槛问题;DeepSeek-R1模型通过强化学习提升推理能力,支持复杂任务处理,并且具有低成本和高效率等特点。
更准确的自然语言问数:数据分析类产品引入大模型后,显著提升用户模糊语义解析能力(如“分析华南区销售异常原因”),自动拆解为指标归因、趋势对比、关联因素挖掘等多层分析任务,输出结构化结论。并且用户在与 ChatBI 进行对话式分析过程中,大模型能够实时处理用户输入,快速生成分析结果并反馈给用户。同时,根据用户对结果的反馈,如进一步引导追问、调整分析维度等,大模型可以持续优化分析路径,不断迭代输出更符合用户期望的结果。
更敏捷的数据分析效率:一般大模型可结合ChatBI本地化部署能力,企业可在保障数据安全的前提下,以更低算力成本实现分钟级复杂查询响应等。
更个性的企业级知识库:不同行业有独特业务术语与知识体系。 ChatBI 中融合行业知识库,如零售、制造、金融等领域术语,精准识别业务场景中的专业表述,像 “潜客首单转化率”,并自动关联企业私有数据资产,不仅能理解通用的业务语言,还能精准把握行业专属术语和业务逻辑,为客户提供贴合实际业务需求的数据分析结果;并且企业历史分析逻辑(如营销活动复盘模板)、数据口径规则可沉淀至ChatBI知识库,大模型知识库持续学习机制确保模型随业务演进自动优化,解决“重复需求占比70%”的痛点,释放数据团队生产力。
更安全的企业数据生态:ChatBI 支持混合云、私有化等部署模式,敏感数据仅在企业内网流转。借助大模型及ChatBI能力基座,注重数据安全的政企类客户可进行私有化部署,搭建适用于内网环境的场景化问答式BI。
参考:
https://blog.youkuaiyun.com/GUANDATA_/article/details/151114075
基于生成式 AI 的 ChatBI 则具有很强的灵活度和泛化能力,可以适应用户的各种个性化需求和快速变化的业务场景,动态生成全新的内容。
-
ChatBI 具有真正的自然语言理解和交互能力,我们不再需要把“常识”通过各种人工维护的规则教给系统。
-
ChatBI 的目标相比搜索更进一步,希望帮助用户整合信息后直接提供“答案”,而不是一系列参考信息。这从根本上来说就具有更高的效益上限,在产品的扩展性上有很大的想象空间。
ChatBI 在很多复杂查询的场景中具有很大的优势。例如:
上个月 X 品牌会员在抖音渠道的 90 天复购率是多少?
“复购率”这个指标的定义过于复杂了。所以我们往往需要把这类复杂指标“下沉”到数据开发层面去解决,通过开发复杂的 ETL 去提前计算好这类指标。
用户的需求是很个性化的,所以上面的问题会在各个维度出现变化,例如:
24 年 6 月全集团会员的 30 天复购率是多少?电商渠道的复购率呢?去年双十一对比前年双十一的复购率呢?...
ChatBI 类产品的界面和交互都非常简单(不像传统软件功能按钮一大堆),而光问问“昨天销量是多少”的问题也很难看出差异来。我们需要结合前面提到的 ChatBI 带来的业务价值,更有针对性地思考如何评估一个 ChatBI 产品。
接入 ChatBI 之后,我们也会发现各类 ad-hoc 查询的数量随着易用性的提高而上涨。所以底层查询引擎的高性能与高可用能力就显得愈发重要了。这也是专业的面向业务用户场景设计的 BI 产品所具有的优势。
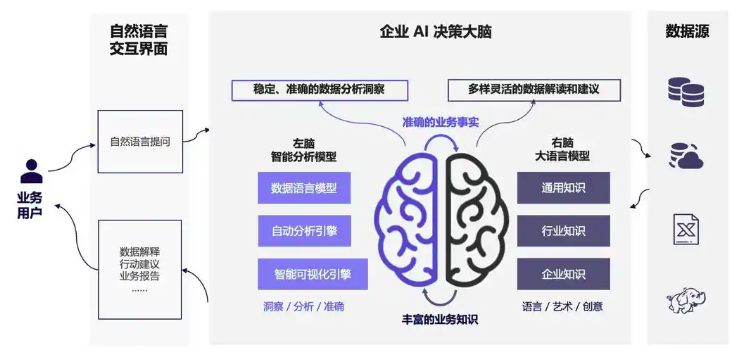
要让一个公开的模型学会企业内部的各种数据分析相关场景的专有知识,我们必须要向其提供企业内部已有的数据分析资产知识。显而易见,这部分知识积累最为丰富的地方就是已有的 BI 系统,我们可以从中抽取到指标定义,业务常用看板/订阅,数据表定义,数据血缘,ETL 定义等等重要的信息。
我们会倾向于在保障用户心理体验的同时,尽可能去提升回答的质量,而把响应速度放在第二位
开始绝大多数人都认为不能把任何数据发送给模型 API 提供商,或许在十多年前,大家也同样认为,企业的数据如果放在云服务、云数据库里,是非常不安全的,必须自建机房。
会精心选取与业务情况无关的“元数据”与大模型发生交互。这也一定程度上限制了某些产品功能的开发,比如让大模型用自然语言总结一下查询的数据之类。
技术路线
Text2DSL
顾名思义,这个路线并不是选择生成 SQL,而是某种中间语言,比如 API/DSL 来调用已有 BI 中定义好的指标或者计算逻辑。
基于查询数据的 API 来“封装一下 SQL”,主要是为了优化一些复杂计算逻辑,比如排名、占比、同环比等。这个方案主要的区别是生成代码的具体形式的不同,以及 DSL 本身可能相比 SQL 会有能力局限。
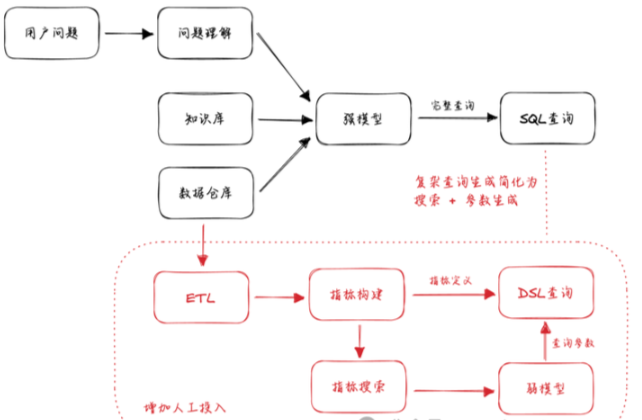
数据分析的本质复杂度并没有发生改变,如果你想让模型生成的内容更简单一些,那么就需要在人工建设方面多投入些,不断建设新的宽表、指标、卡片等,甚至还会因为这类资产的增多花更多力气来知识库的构建上,让模型能够选择正确的资产。这还是把工作量从 AI 转移到了人工上,这里还是会有不少机械重复的投入,没有利用上大模型的知识泛化能力。更重要的是,我们前面提到的 ChatBI 能够敏捷响应业务变化带来的个性化需求的核心收益被大大减少了。
大模型训练过程中见过大量的 SQL 的代码,而自定义的 DSL 往往需要大量的 prompt 甚至 fine tune 来达到接近的效果。而当进入到复杂指标的深水区时,也会发现 SQL 本身的设计已经很优秀了,也难怪这么多年一直是最主流的数据分析使用语言。
数据分析的本质复杂度已经很好地被 SQL 这门语言抓住了,其它大多数的尝试都只是把工作量转移到了数据分析链路的其它地方。对于 ChatBI Agent 来说,模型预训练中最熟悉的语言必定是 SQL,在寻找灵活度,准确度和人工投入的“帕累托最优”中,SQL 仍然是最好的选择。
例如用户在指标平台已经定义了销售额和复购率两个指标,当用户提问复购金额时,基于指标的做法并不能帮用户新建出一个指标出来。而在 SQL 生成场景中,则能够直接生成相应的 SQL,真正体现出“生成式 AI”的特性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









