



1.简述
ELK集群可以由以下列组件组成:
Logstash(采集+处理)>> Elasticsearch (存储) >> Kibana (展示)
Filebeat (采集) >> Logstash (处理) >> Elasticsearch >> Kibana
Filebeat >> Kafka(缓存)>> Logstash >> Elasticsearch >> Kibana
Logstash 组件核心功能:
①采集数据
支持多样化输入:可从日志文件、数据库(如 MySQL、PostgreSQL)、消息队列(如 Kafka、RabbitMQ)、网络协议(如 TCP/UDP)等来源实时采集数据。
流式传输能力:以连续流模式处理数据,适合实时日志监控场景(如服务器日志、应用性能指标)。
② 数据清洗与转换
字段解析:通过 Grok 插件从非结构化日志中提取结构化字段(如 IP、时间戳、错误码)。
格式标准化:支持日期格式化、字段重命名、数据类型转换(如字符串转数值)等操作,确保数据一致性。
敏感数据处理:支持数据脱敏、字段过滤(删除冗余或无意义字段)。
③灵活数据输出
多目标适配:处理后的数据可输出至 Elasticsearch(用于搜索与分析)、Kafka(缓冲与分发)、文件系统(长期存储)等,满足不同下游需求。
动态路由:根据数据内容或标签将特定日志分发至不同存储或分析系统(如错误日志发往告警平台。
Elasticsearch 组件核心功能:
①数据存储
近实时存储:支持秒级延迟写入数据,基于倒排索引实现高效全文检索。
分片与副本机制:通过横向分片和副本备份保障高可用性与容错能力。
②索引与搜索
复杂查询:支持全文检索、聚合分析(如统计 PV/UV)、地理空间查询等。
RESTful API:提供标准化接口供外部系统集成(如 Kibana 或自定义应用)。
Kibana 组件核心功能:
①交互式分析
仪表盘定制:通过拖拽组件(折线图、柱状图、热力图等)创建可视化看板。
灵活查询:支持 KQL(Kibana Query Language)和 Lucene 语法快速筛选数据。
②运维监控
告警配置:基于阈值或异常检测规则触发通知(如 CPU 使用率超限)。
日志追踪:通过 Discover 功能直接检索原始日志,支持字段过滤与高亮显示。
Kafka 组件核心功能:
①流量削峰与缓冲
削峰平谷:在高并发日志场景(如业务高峰期)下,Kafka 作为缓冲层暂存日志数据,避免 Logstash 或 Elasticsearch 因瞬时流量过大导致崩溃。
异步处理:日志生产者(如 Filebeat、Rsyslog)将数据写入 Kafka 后即可释放资源,下游的 Logstash 按自身处理能力消费数据,实现异步解耦 。
②可靠性与容错性
持久化存储:Kafka 将日志持久化到磁盘,即使下游服务(如 Logstash、Elasticsearch)故障或重启,数据也不会丢失 。
高可用保障:Kafka 的分布式架构支持多副本机制,单节点故障时自动切换副本,保障日志传输连续性 。
③扩展性与多消费者支持
多消费者并行处理:支持多个 Logstash 实例同时消费同一 Kafka Topic 的数据,提升日志处理吞吐量(如分片消费模式) 。
灵活路由:通过不同 Topic 对日志分类(如按业务类型、日志级别),实现精细化分发与处理 。
Filebeat 组件核心功能:
①轻量级与资源高效性
低资源消耗:相比 Logstash,Filebeat 占用的 CPU 和内存资源更少,适用于资源敏感的环境(如容器、虚拟机或边缘节点)。
高性能采集:通过异步发送机制和背压控制(Backpressure),保障高并发场景下数据采集的稳定性,避免因下游处理延迟导致系统崩溃 。
②实时日志采集与连续性保障
实时监听与传输:持续监控指定日志文件的变化,实时捕获新增内容并发送至下游(如 Elasticsearch、Logstash 或 Kafka)。
断点续传:通过 注册表(Registrar) 记录已采集日志的位置,即使服务中断,重启后也能从中断处继续采集,确保数据完整性。
③模块化与自动化适配
预置解析模块:内置 Apache、Nginx、MySQL 等通用日志格式解析模块,简化日志结构化处理流程。
动态服务发现:在容器化环境中自动识别新容器或服务,并启动日志采集,无需手动配置更新。
④灵活输出与架构解耦
多目标分发:支持将日志直接发送至 Elasticsearch(快速存储与分析)、Logstash(复杂清洗)或 Kafka(缓冲与异步处理),适配不同架构需求 。
负载均衡:通过多节点部署和轮询策略,实现采集任务的横向扩展,提升吞吐量 。
2.背景描述
将AAS中间件中输出的日志进行收集,统一分析查看
3.环境准备
麒麟V10服务器操作系统
AAS中间件
ELK - 7.2.0 版本套件(包含Filebeat)
4.Elasticsearch部署
-
创建组和用户
groupadd es
useradd -d -m /home/es -s /bin/bash -g es es- 将已下载的二进制安装包解压、创建软链接、创建数据目录、修改所属组所有者
tar -xzvf elasticsearch-7.2.0-linux-x86_64.tar.gz
ln -s elasticsearch-7.2.0 elasticsearch
mkdir elasticsearch/data -p
chown -R es:es elasticsearch
chown -R es:es elasticsearch-7.2.0
- 修改elasticsearch.yml 配置文件 如下:
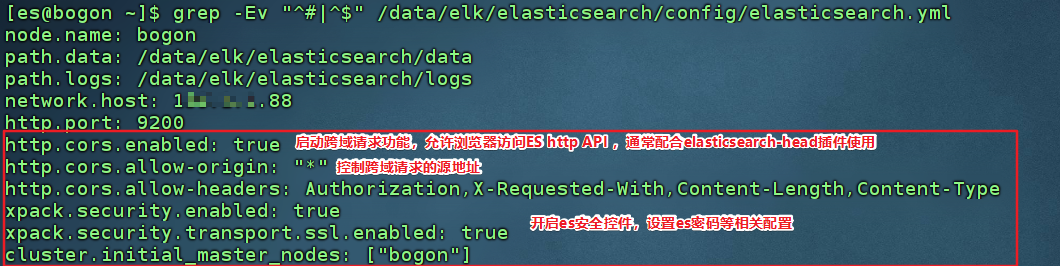
- 修改系统参数和es参数
vim /etc/security/limit.conf
[追加后重启生效]
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
[执行立即生效,重启失效]
ulimit -n 65535
vim /etc/sysctl.conf
vm.max_map_count=655360 [追加]
sysctl -p [执行立即生效]
- 启动服务,开启密码认证并设置密码后,访问http://ip:9200 验证即可
./elasticsearch -d
./elasticsearch-setup-passwords interactive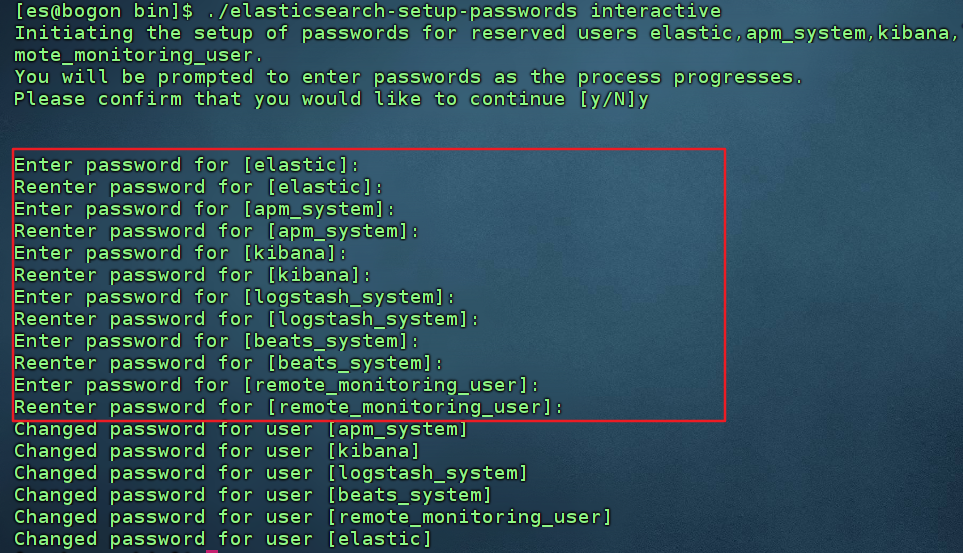
5.kibana部署
- 将已下载的二进制安装包解压、修改所有者和所属组、修改kibana配置文件

- 修改kibana配置文件
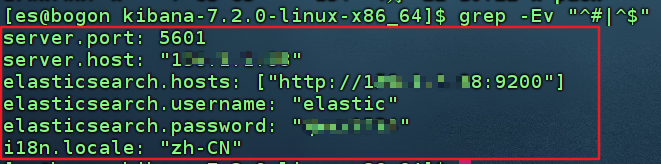
- 启动服务,访问http://ip:5601验证
6.Filebeat部署
- 安装filebeat rpm安装包

- 修改配置文件,将收集的日志发送给logstash进行处理
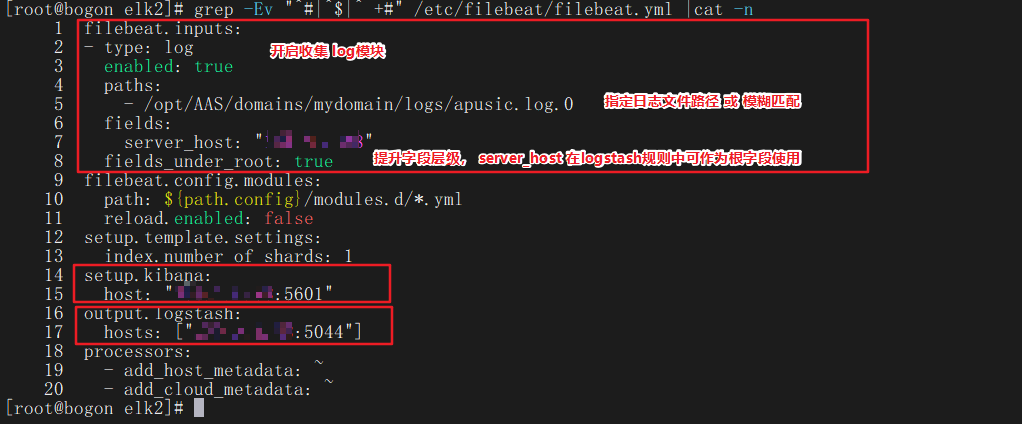
- 启动服务并查看启动日志,提示连接logstash超时,因为logstash还未进行启动配置,可以等logstash配置完成启动后,在启动filebeats服务
systemctl start filebeat.service
journalctl -u filebeat -f 
7.Logstash部署
- 安装logstash rpm安装包

- 配置文件介绍
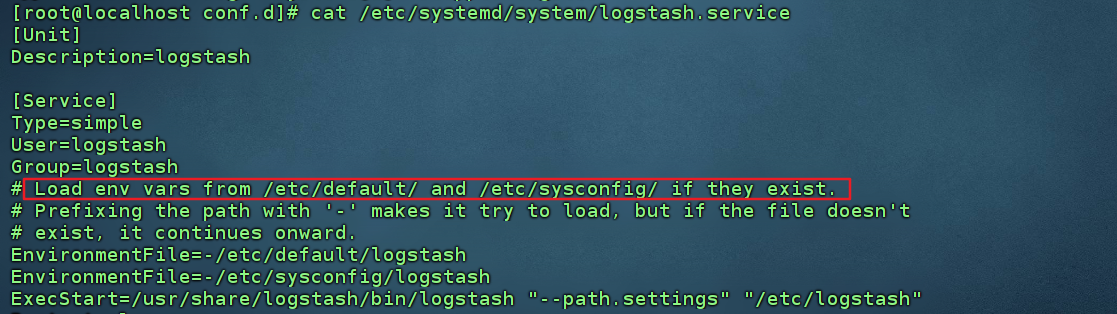

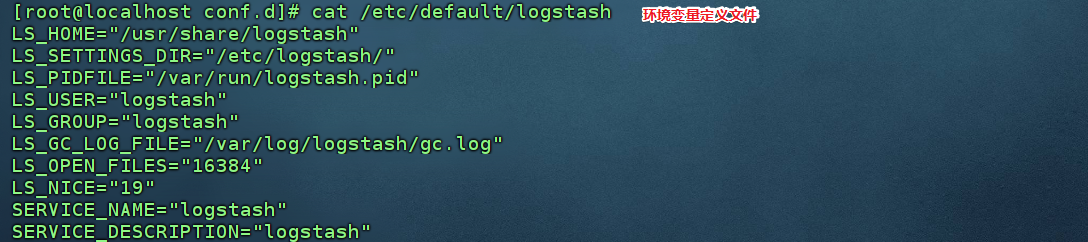
-- 修改jvm.options : 根据实际服务器内存大小设置jvm启动参数

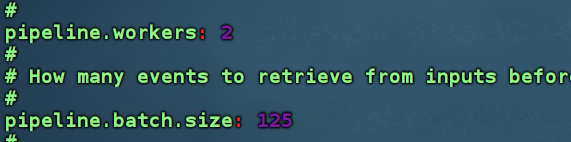
-- 修改logstash.yml : 根据cpu核心数设置
-- 复制 logstash-sample.conf 到 /etc/logstash/conf.d/下,启动后默认读取该路径下的配置文件进行数据获取 输出(此配置文件中未包含过滤规则)
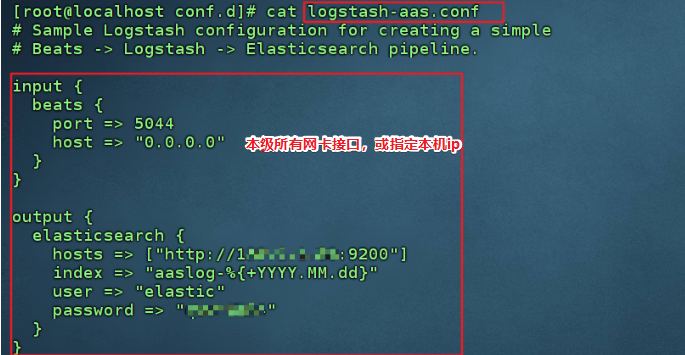
- 检测配置文件是否存在问题 使用参数: --config.test_and_exit
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash-aas.conf --config.test_and_exit
- 启动logstash服务,检测日志,通过kibana查看是否创建索引及数据情况
systemctl start logstash.service
journalctl -u logstash -f 

8.验证
- 登录kibana >> 开发者工具 ,查看索引是否创建

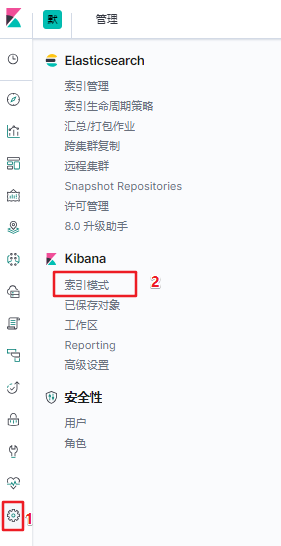
- 登录kibana >> 管理 >> 索引模式,创建索引模式,关联索引数据

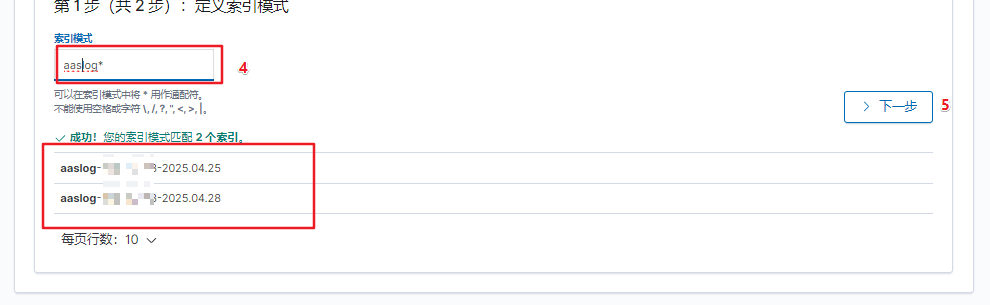
- 创建完成后,点击kibana >> discover 即可查看到所采集到的各个指标的参数
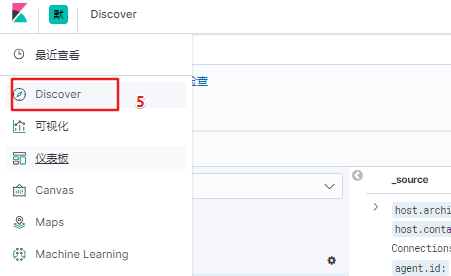
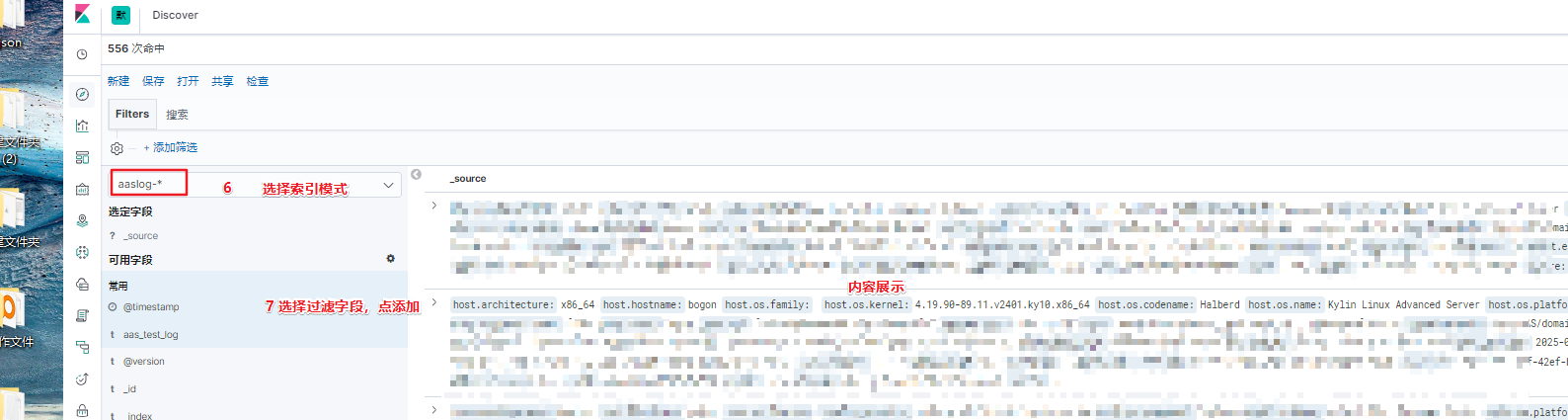
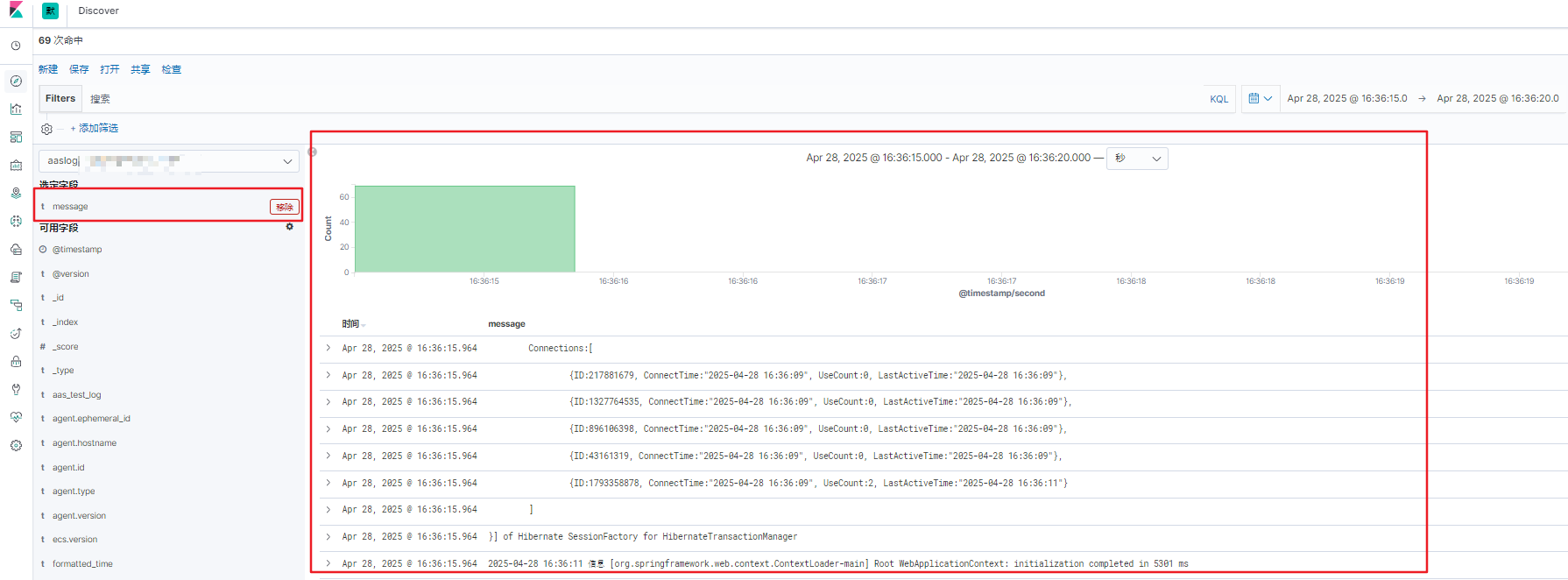
- 添加 message 指标,查看输出的内容,默认为该文件的内容(未进行过滤筛选等配置)

9.补充:Logstash过滤规则 验证
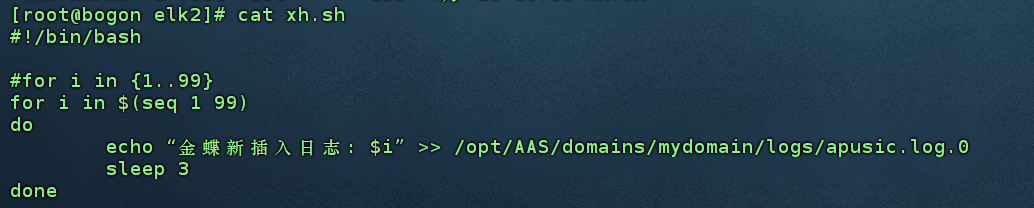
- 编写一个脚本自动往采集的文件中写入信息

- 修改filebeat.yml的配置,使采集的数据输出到控制台
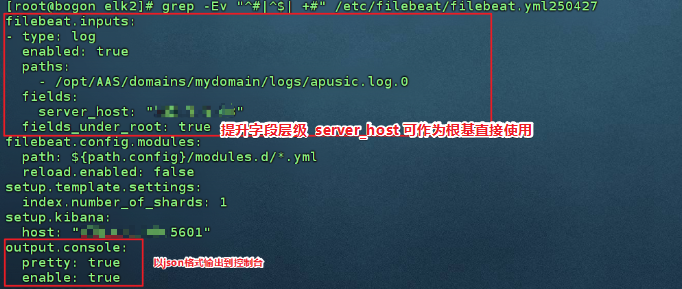
- 通过journalctl 命令实时查看filebeat日志,查看采集情况验证已接收到数据后,将flebeat配置改为输出到 logstash
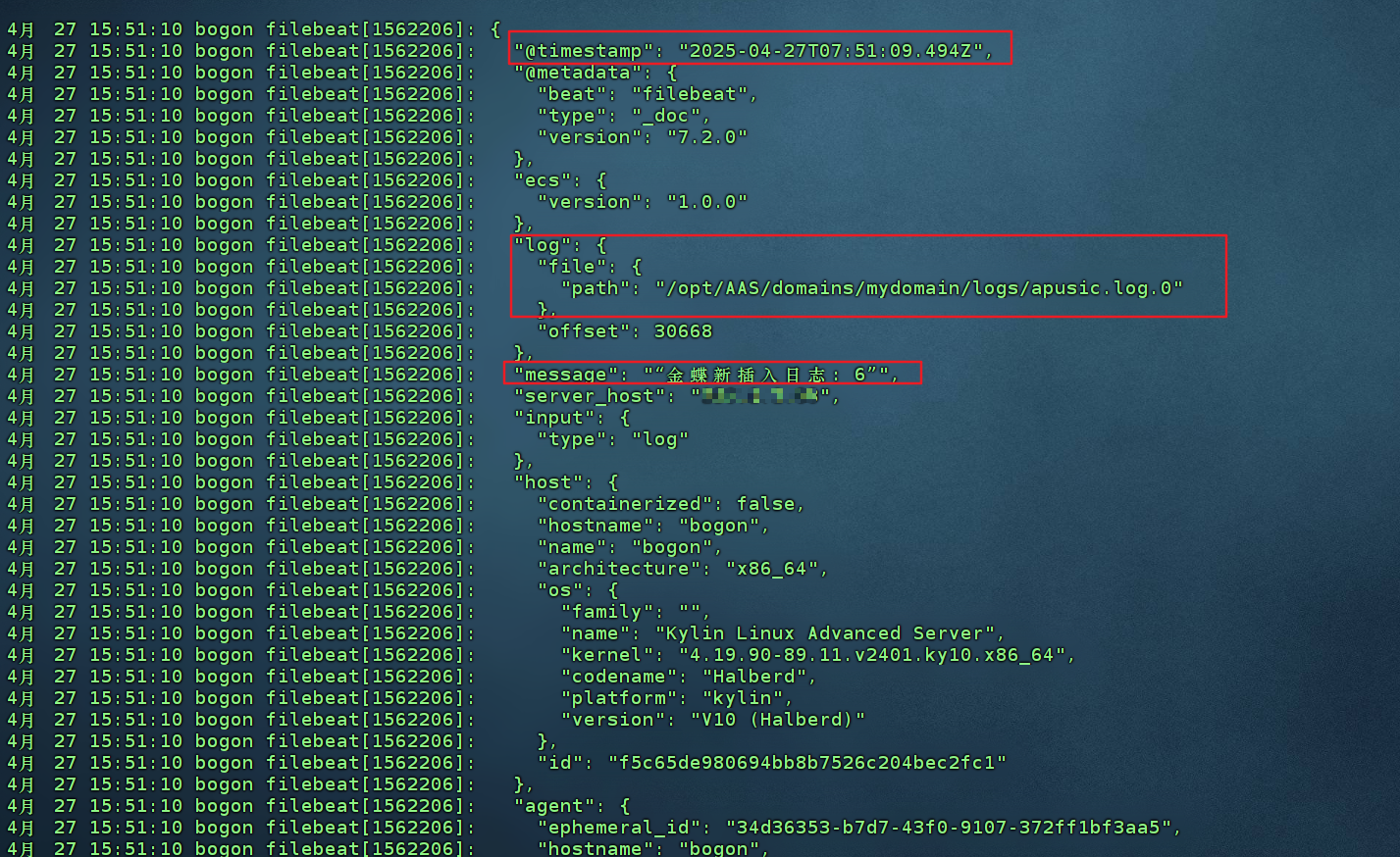
- 优化logstash的配置文件,使用grok插件编写过滤规则
filter {
date {
match => ["@timestamp", "ISO8601"]
target => "formatted_time"
timezone => "Asia/Shanghai"
}
mutate {
replace => { "formatted_time" => "%{+yyyy-MM-dd HH:mm:ss}" }
}
mutate {
add_field => {
"aas_test_log" => "%{formatted_time} - %{message}"
}
}
}
- 重启filebeat服务和logstash服务,按上述第8步验证创建索引模式流程,即可看到该索引中的 aas_test_log 指标中的数据,过滤规则实操可用。
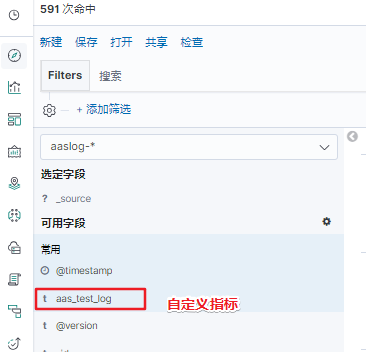
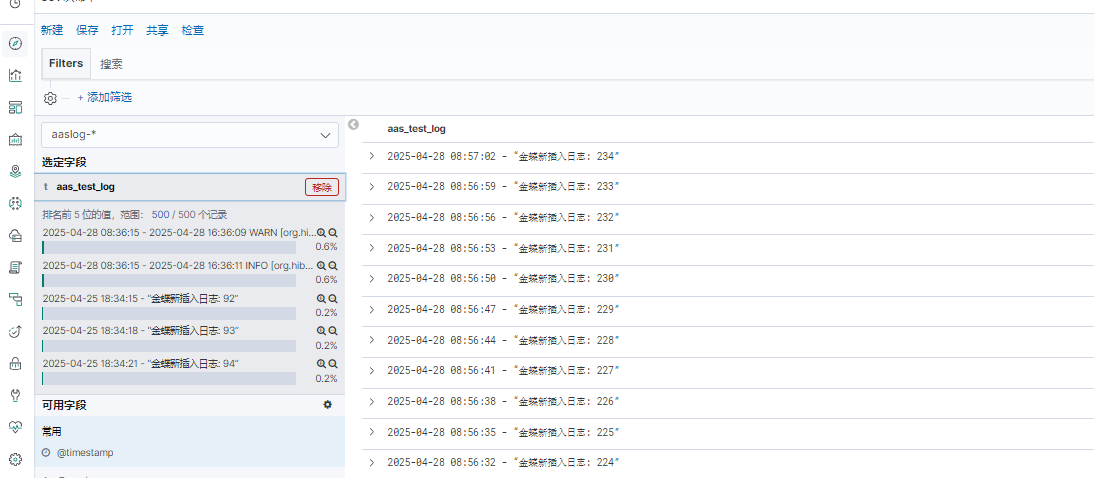
其他匹配规则及想获取的日志内容,可与研发沟通确定日志输出规则,编写grok规则即可

















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









